
Let's start with a small introduction to Red Hat OpenShift: Red Hat OpenShift is an enterprise-ready Kubernetes container platform with full-stack automated operations to manage hybrid cloud and multi-cloud deployments. Red Hat OpenShift is optimized to improve developer productivity and promote innovation.
OpenShift includes an Enterprise grade Linux operating system, container runtime, networking, monitoring, registry, authentication and authorization solutions. Users can automate life-cycle management to provide increased security, tailored operations solutions, easy-to-manage cluster operations and application portability.
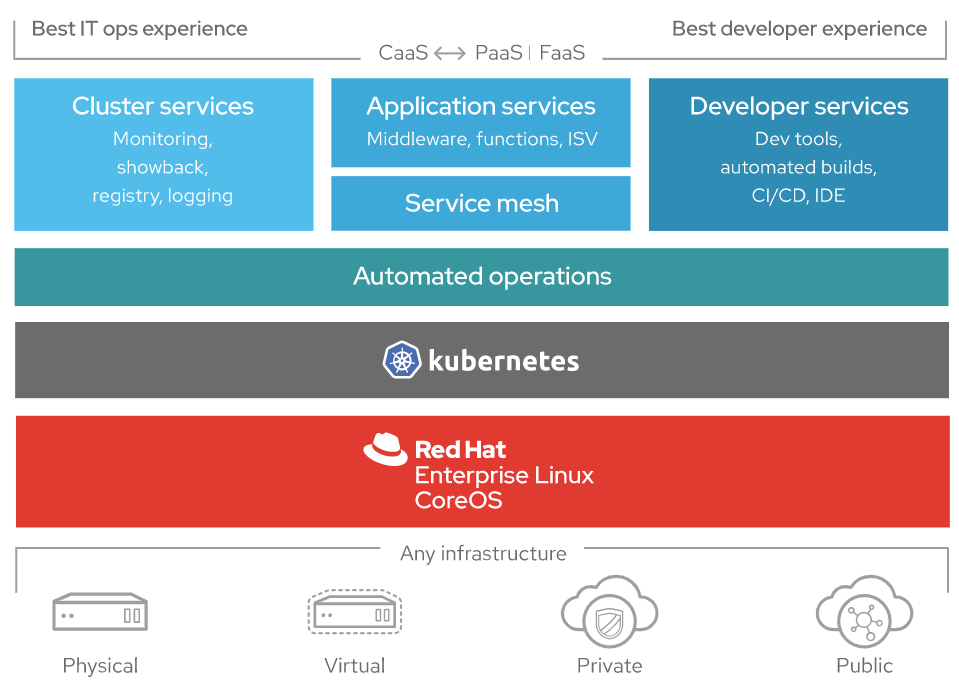
OpenShift stands out as a leader with a security-focused, supported Kubernetes platform—including a foundation based on Red Hat Enterprise Linux.
But we already knew all that, the game changer for OpenShift, is the release of OCP version 4.x: OpenShift 4 is powered by Kubernetes Operators and Red Hat’s commitment to full-stack security, so you can develop and scale big ideas for the enterprise.
OpenShift started with distributed systems. It was eventually extended to IBM Power Systems, and now it is available on IBM Z. This creates a seamless user experience across major architectures such as x86, PPC and s390x!
This article's goal is to share my experience on how to install Red Hat Openshift Platform (OCP) 4.2 on IBM Z. We will use the minimum requirements to get our environment up and running, that said, for production or performance testing using the preferred configuration from the official Red Hat documentation. The minimum machine requirements for a cluster with user-provisioned infrastructure are as follows:
The smallest OpenShift Container Platform clusters require the following hosts:
- One temporary bootstrap machine
- Three control plane, or master, machines
- At least two compute, or worker, machines
The bootstrap, control plane (often called masters), and compute machines must use the Red Hat Enterprise Linux CoreOS (RHCOS) as the operating system.
All the Red Hat Enterprise Linux CoreOS (RHCOS) machines require network in initramfs during boot to fetch Ignition config files from the Machine Config Server. The machines are configured with static IP addresses. No DHCP server is required.
To install on IBM Z under z/VM, you require a single z/VM virtual NIC in layer 2 mode. You also need:
- A single virtual NIC in layer 2 mode
- A z/VM VSwitch set up (or a shared OSA device for all VMs)
MINIMUM RESOURCE REQUIREMENTS
Each cluster machine must meet the following minimum requirements, in our case, this are the resource requirements for the VMs on IBM z/VM:

For our testing purposes (and resources limitations) we used one dasd model 54 for each node instead of the 120GB recommended by the official Red Hat documentation.
Make sure to install OpenShift Container Platform version 4.2 using one of the following IBM hardware:
- IBM Z: versions z13, z14, or z15
- IBM LinuxONE: Emperor, Emperor II or Emperor III
Minimum Hardware Requirements
- 1 LPAR with 3 IFLs
- 1 OSA or RoCE network adapter
Operating System REQUIREMENTS
- One z/VM 7.1 LPAR
This is the environment that we created to install the Openshift Container Platform following the minimum resource requirements, keep in mind that other services will be required in this environment and you can have them either on Z or provided to the Z box from outside, like the DNS (name resolution), HAProxy ( our load balancer), Workstation (our client system where we would run the CLI commands for OCP), HTTPd (serving the files such as the Red Hat CoreOS image as well as the ignition files that will be generated by later sections of this guide):

NETWORK TOPOLOGY REQUIREMENTS
Before you install OpenShift Container Platform, you must provision two layer-4 load balancers. The API requires one load balancer and the default Ingress Controller needs the second load balancer to provide ingress to applications. In our case we used a single instance of HAProxy running on a Red Hat Enterprise Linux 8 VM as our load balancer:
The following haproxy configuration will help us provide the load balancer layer for our purposes, edit the /etc/haproxy/haproxy.cfg and add:
listen ingress-http
bind *:80
mode tcp
server worker0 <compute0-IP-address>:80 check
server worker1 <compute1-IP-address>:80 check
listen ingress-https
bind *:443
mode tcp
server worker0 <compute0-IP-address>:443 check
server worker1 <compute1-IP-address>:443 check
listen api
bind *:6443
mode tcp
server bootstrap <bootstrap-IP-address>:6443 check
server master0 <master0-IP-address>:6443 check
server master1 <master1-IP-address>:6443 check
server master2 <master2-IP-address>:6443 check
listen api-int
bind *:22623
mode tcp
server bootstrap <bootstrap-IP-address>:22623 check
server master0 <master0-IP-address>:22623 check
server master1 <master1-IP-address>:22623 check
server master2 <master2-IP-address>:22623 check
Don't forget to open the respective ports on the system's firewall as well as set the SELinux boolean as follows:
# firewall-cmd --add-port=443/tcp
# firewall-cmd --add-port=443/tcp --permanent
# firewall-cmd --add-port=80/tcp
# firewall-cmd --add-port=80/tcp --permanent
# firewall-cmd --add-port=6443/tcp
# firewall-cmd --add-port=6443/tcp --permanent
# firewall-cmd --add-port=22623/tcp
# firewall-cmd --add-port=22623/tcp --permanent
# setsebool -P haproxy_connection_any 1
The following DNS records are required for an OpenShift Container Platform cluster that uses user-provisioned infrastructure. In each record, <cluster_name> is the cluster name and <domain> is the cluster base domain that you specify in the install-config.yaml file.
Required DNS Records:
api.<cluster_name>.<base_domain>
This DNS record must point to the load balancer for the control plane machines. This record must be resolvable by both clients external to the cluster and from all the nodes within the cluster.
api-int.<cluster_name>.<base_domain>
This DNS record must point to the load balancer for the control plane machines. This record must be resolvable from all the nodes within the cluster.
The API server must be able to resolve the worker nodes by the host names that are recorded in Kubernetes. If it cannot resolve the node names, proxied API calls can fail, and you cannot retrieve logs from Pods.
*.apps.<cluster_name>.<base_domain>
A wildcard DNS record that points to the load balancer that targets the machines that run the Ingress router pods, which are the worker nodes by default. This record must be resolvable by both clients external to the cluster and from all the nodes within the cluster.
etcd-<index>.<cluster_name>.<base_domain>
OpenShift Container Platform requires DNS records for each etcd instance to point to the control plane machines that host the instances. The etcd instances are differentiated by values, which start with 0 and end with n-1, where n is the number of control plane machines in the cluster. The DNS record must resolve to an unicast IPv4 address for the control plane machine, and the records must be resolvable from all the nodes in the cluster.
_etcd-server-ssl._tcp.<cluster_name>.<base_domain>
For each control plane machine, OpenShift Container Platform also requires a SRV DNS record for etcd server on that machine with priority 0, weight 10 and port 2380. A cluster that uses three control plane machines requires the following records:
# _service._proto.name. TTL class SRV priority weight port target.
_etcd-server-ssl._tcp.<cluster_name>.<base_domain>. 86400 IN SRV 0 10 2380 etcd-0.<cluster_name>.<base_domain>.
_etcd-server-ssl._tcp.<cluster_name>.<base_domain>. 86400 IN SRV 0 10 2380 etcd-1.<cluster_name>.<base_domain>.
_etcd-server-ssl._tcp.<cluster_name>.<base_domain>. 86400 IN SRV 0 10 2380 etcd-2.<cluster_name>.<base_domain>.
As a summary, this is how our DNS records defined in our domain zone would look like when using Bind as my DNS server :
$TTL 86400
@ IN SOA <nameserver-name>.<domain>. admin.<domain>. (
2020021813 ;Serial
3600 ;Refresh
1800 ;Retry
604800 ;Expire
86400 ;Minimum TTL
)
;Name Server Information
@ IN NS <nameserver-name>.<domain>.
;IP Address for Name Server
<nameserver-name> IN A <nameserver-IP-address>
;A Record for the following Host name
haproxy IN A <haproxy-IP-address>
bootstrap IN A <bootstrap-IP-address>
master0 IN A <master0-IP-address>
master1 IN A <master1-IP-address>
master2 IN A <master2-IP-address>
workstation IN A <workstation-IP-address>
compute0 IN A <compute0-IP-address>
compute1 IN A <compute1-IP-address>
etcd-0.<cluster_name> IN A <master0-IP-address>
etcd-1.<cluster_name> IN A <master1-IP-address>
etcd-2.<clsuter_name> IN A <master2-IP-address>
;CNAME Record
api.<cluster_name> IN CNAME haproxy.<domain>.
api-int.<cluster_name> IN CNAME haproxy.<domain>.
*.apps.<cluster_name> IN CNAME haproxy.<domain>.
_etcd-server-ssl._tcp.<cluster_name>.<domain>. 86400 IN SRV 0 10 2380 etcd-0.<cluster_name>.<domain>.
_etcd-server-ssl._tcp.<cluster_name>.<domain>. 86400 IN SRV 0 10 2380 etcd-1.<cluster_name>.<domain>.
_etcd-server-ssl._tcp.<cluster_name>.<domain>. 86400 IN SRV 0 10 2380 etcd-2.<cluster_name>.<domain>.
Don't forget to create the reserve records for your zone as well, example of how we setup ours:
$TTL 86400
@ IN SOA <nameserver-name>.<domain>. admin.<domain>. (
2020021813 ;Serial
3600 ;Refresh
1800 ;Retry
604800 ;Expire
86400 ;Minimum TTL
)
;Name Server Information
@ IN NS <nameserver-name>.<domain>.
<nameserver-name> IN A <nameserver-IP-address>
;Reverse lookup for Name Server
<XX> IN PTR <nameserver-name>.<domain>.
;PTR Record IP address to Hostname
<XX> IN PTR haproxy.<domain>.
<XX> IN PTR bootstrap.<domain>.
<XX> IN PTR master0.<domain>.
<XX> IN PTR master1.<domain>.
<XX> IN PTR master2.<domain>.
<XX> IN PTR master3.<domain>.
<XX> IN PTR compute0.<domain>.
<XX> IN PTR compute1.<domain>.
<XX> IN PTR workstation.<domain>.
Where <XX> for each record will be the last octet of their IP addresses.
Make sure that your Bind9 DNS server also provides access to the outside world, a.k.a Internet access by using the parameter in your /etc/named.conf options configuration section:
options {
// listen-on port 53 { 127.0.0.1; };
// listen-on-v6 port 53 { ::1; };
directory "/var/named";
dump-file "/var/named/data/cache_dump.db";
statistics-file "/var/named/data/named_stats.txt";
memstatistics-file "/var/named/data/named_mem_stats.txt";
secroots-file "/var/named/data/named.secroots";
recursing-file "/var/named/data/named.recursing";
allow-query { localhost; <Network-IP>; };
forwarders { <IP-gateway-Internet>; };
For the sections Generating an SSH private key and Installing the CLI as well as Manually Creating the installation configuration files, we used the Workstation VM using RHEL8.
Generating an SSH private key and adding it to the agent
In our case, we used a Linux workstation as the base system outside of the OCP cluster. The next steps were done in this system.
If you want to perform installation debugging or disaster recovery on your cluster, you must provide an SSH key to both your ssh-agent and to the installation program.
If you do not have an SSH key that is configured for password-less authentication on your computer, create one. For example, on a computer that uses a Linux operating system, run the following command:
$ ssh-keygen -t rsa -b 4096 -N '' \
-f <path>/<file_name>
Then access the Infrastructure Provider page on the Red Hat OpenShift Cluster Manager site. If you have a Red Hat account, log in with your credentials. If you do not, create an account.
Navigate to the page for your installation type, download the installation program for your operating system, and place the file in the directory where you will store the installation configuration files:
https://.../openshift-v4/s390x/clients/ocp/latest/openshift-install-linux-4.2.18.tar.gz
Extract the installation program. For example, on a computer that uses a Linux operating system, run the following command:
$ tar xvf <installation_program>.tar.gz
From the Pull Secret page on the Red Hat OpenShift Cluster Manager site, download your installation pull secret as a .txt file. This pull secret allows you to authenticate with the services that are provided by the included authorities, including Quay.io, which serves the container images for OpenShift Container Platform components.

Installing the CLI
You can install the CLI in order to interact with OpenShift Container Platform using a command-line interface.
From the Infrastructure Provider page on the Red Hat OpenShift Cluster Manager site, navigate to the page for your installation type and click Download Command-line Tools.

Click the folder for your operating system and architecture and click the compressed file.
- Save the file to your file system.
https://.../openshift-v4/s390x/clients/ocp/latest/openshift-client-linux-4.2.18.tar.gz
- Extract the compressed file.
- Place it in a directory that is on your PATH.
After you install the CLI, it is available using the oc command:
$ oc <command>
Manually creating the installation configuration file
For installations of OpenShift Container Platform that use user-provisioned infrastructure, you must manually generate your installation configuration file.
Create an installation directory to store your required installation assets in:
$ mkdir <installation_directory>
Customize the following install-config.yaml file template and save it in the <installation_directory>.
Sample install-config.yaml file for bare metal
You can customize the install-config.yaml file to specify more details about your OpenShift Container Platform cluster’s platform or modify the values of the required parameters. For IBM Z, please make sure to add architecture: s390x for both compute and controlPlane nodes or the config-cluster.yaml file will be generated with AMD64.
apiVersion: v1
baseDomain: <domain>
compute:
- architecture: s390x
hyperthreading: Enabled
name: worker
replicas: 0
controlPlane:
architecture: s390x
hyperthreading: Enabled
name: master
replicas: 3
metadata:
name: <cluster_name>
networking:
clusterNetwork:
- cidr: 10.128.0.0/14
hostPrefix: 23
networkType: OpenShiftSDN
serviceNetwork:
- 172.30.0.0/16
platform:
none: {}
fips: false
pullSecret: '<pull-secret>'
sshKey: '<ssh-public-key>'
Creating the Kubernetes manifest and Ignition config files
Because you must modify some cluster definition files and manually start the cluster machines, you must generate the Kubernetes manifest and Ignition config files that the cluster needs to make its machines.
Generate the Kubernetes manifests for the cluster:
$ ./openshift-install create manifests --dir=<installation_directory>
WARNING There are no compute nodes specified. The cluster will not fully initialize without compute nodes.
INFO Consuming "Install Config" from target directory
Modify the /<installation_directory>/manifests/cluster-scheduler-02-config.yml Kubernetes manifest file to prevent Pods from being scheduled on the control plane machines:
- Open the manifests/cluster-scheduler-02-config.yml file.
- Locate the mastersSchedulable parameter and set its value to False.
- Save and exit the file.
Create the Ignition config files:
$ ./openshift-install create ignition-configs --dir=<installation_directory>
The following files are generated in the directory:
.
├── auth
│ ├── kubeadmin-password
│ └── kubeconfig
├── bootstrap.ign
├── master.ign
├── metadata.json
└── worker.ign
Copy the files master.ign, worker.ign and bootstrap.ign to the HTTPD node where you should have configured a http server (Apache) to serve these files during the creation of the Red Hat Linux CoreOS VMs.
Creating Red Hat Enterprise Linux CoreOS (RHCOS) machines
Download the Red Hat Enterprise Linux CoreOS installation files from the RHCOS image mirror
Download the following files:
- The initramfs: rhcos-<version>-installer-initramfs.img
- The kernel: rhcos-<version>-installer-kernel
- The operating system image for the disk on which you want to install RHCOS. This type can differ by virtual machine:
- rhcos-<version>-s390x-metal-dasd.raw.gz for DASD (We used the DASD version)
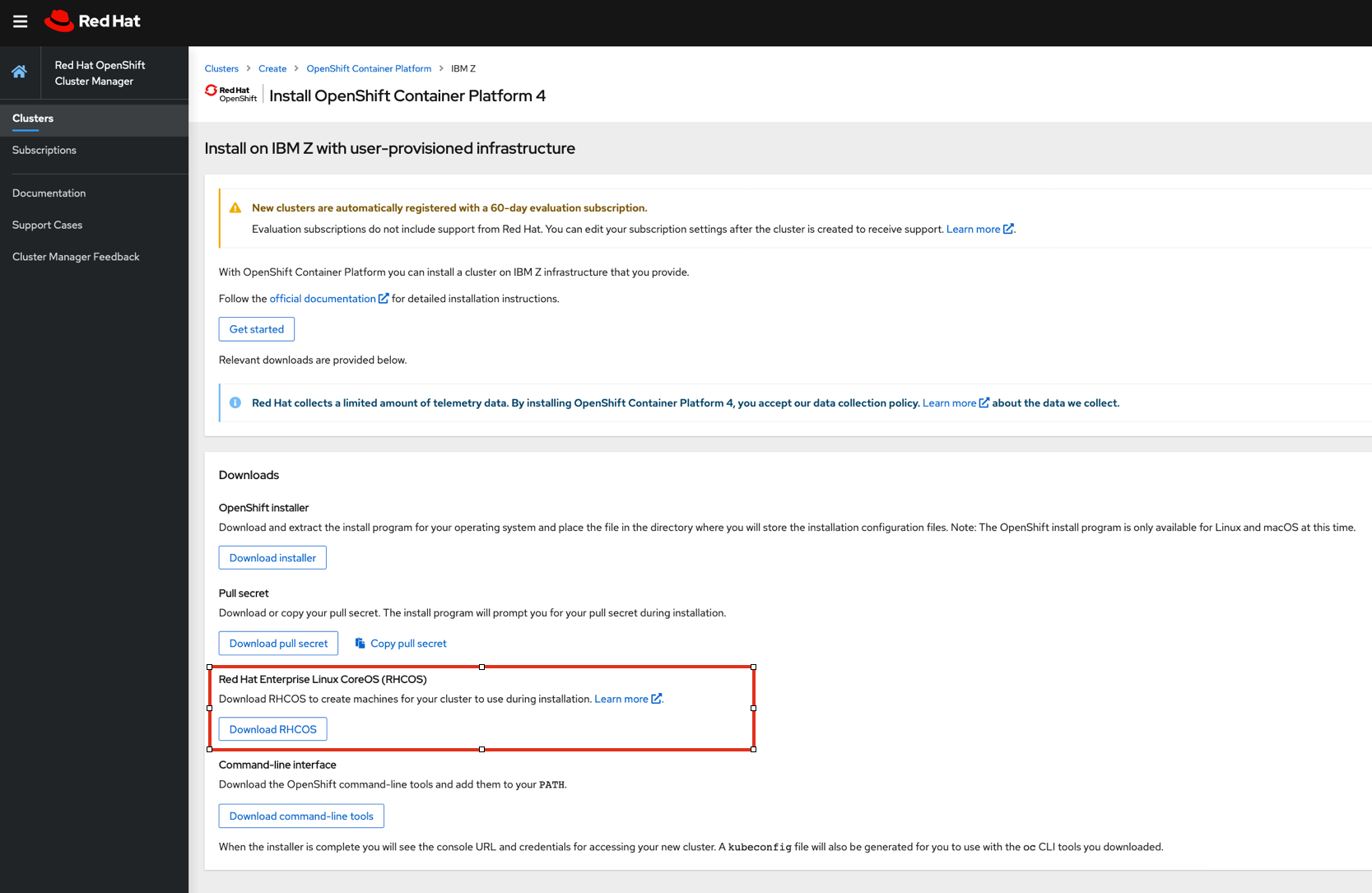
Create parameter files. The following parameters are specific for a particular virtual machine:
- For coreos.inst.install_dev=, specify dasda for DASD installation.
- For rd.dasd=, specifies the DASD where RHCOS will be installed.
The bootstrap machine ignition file is called bootstrap-0, the master ignition files are numbered 0 through 2, the worker ignition files from 0 upwards. All other parameters can stay as they are.
Example parameter file we used on our environment, bootstrap-0.parm, for the bootstrap machine:
rd.neednet=1 coreos.inst=yes
coreos.inst.install_dev=<dasda>
coreos.inst.image_url=http://<http-server>/rhcos-4.2.18.raw.gz
coreos.inst.ignition_url=http://<http-server>/bootstrap.ign
vlan=eth0.<1100>:<enc1e00>
ip=<bootstrap-IP-address>::<gateway>:<netmask>:<bootstrap-hostname>:eth0.<1100>:off
nameserver=<nameserver-IP-address>
rd.znet=qeth,<0.0.1f00>,<0.0.1f01>,<0.0.1f02>,layer2=1,portno=0
cio_ignore=all,!condev
rd.dasd=<0.0.0201>
Where <enc1e00> = physical interface, <eth0> = virtual interface alias for enc1e00 and <1100> = vlan ID
Note that for your environment the rd.znet=, rd.dasd=, coreos.inst.install_dev=, they all be different from ours.
Each VM on z/VM will require access to the initramfs, kernel, and parameter (.parm) files on their internal disk. We used a common approach which is create a VM that will use it's internal disk as a repository for all these files, and all the other VMs part of the cluster (bootstrap, master0, master1, .... worker1) will have access to this repository VMs disk (often in read-only mode) saving disk space as these files will only be used in the first stage of the process to load the files for each VM part of the cluster into the server's memory. Each cluster VM will have a dedicated disk for the RHCOS, which is a completely separate disk (as previously covered, the model 54 ones).
Transfer the initramfs, kernel and all parameter (.parm) files to the repository VM's local A disk on z/VM from an external FTP server:
==> ftp <VM_REPOSITORY_IP>
VM TCP/IP FTP Level 710
Connecting to <VM_REPOSITORY_IP>, port 21
220 (vsFTPd 3.0.2)
USER (identify yourself to the host):
>>>USER <username>
331 Please specify the password.
Password:
>>>PASS ********
230 Login successful.
Command:
cd <repositoryofimages>
ascii
get <parmfile_bootstrap>.parm
get <parmfile_master>.parm
get <parmfile_worker>.parm
locsite fix 80
binary
get <kernel_image>.img
get <initramfs_file>
Example of the VM definition (userid=LNXDB030) for the bootstrap VM on IBM z/VM for this installation:
USER LNXDB030 LBYONLY 16G 32G
INCLUDE DFLT
COMMAND DEFINE STORAGE 16G STANDBY 16G
COMMAND DEFINE VFB-512 AS 0101 BLK 524288
COMMAND DEFINE VFB-512 AS 0102 BLK 524288
COMMAND DEFINE VFB-512 AS 0103 BLK 524288
COMMAND DEFINE NIC 1E00 TYPE QDIO
COMMAND COUPLE 1E00 SYSTEM VSWITCHG
CPU 00 BASE
CPU 01
CPU 02
CPU 03
MACHINE ESA 8
OPTION APPLMON CHPIDV ONE
POSIXINFO UID 100533
MDISK 0191 3390 436 50 USAW01
MDISK 0201 3390 1 END LXDBC0
Where USER LNXDB030 LBYONLY 16G 32G is userid password memory definition, COMMAND DEFINE VFB-512 AS 0101 BLK 524288 is Swap definition, COMMAND DEFINE NIC 1E00 TYPE QDIO is NIC definition, COMMAND COUPLE 1E00 SYSTEM VSWITCHG is vswitch couple, MDISK 0191 3390 436 50 USAW01 is where you put the EXEC to run, MDISK 0201 3390 1 END LXDBC0 is the mdisk mod54 for the RHCOS.
Punch the files to the virtual reader of the z/VM guest virtual machine that is to become your bootstrap node
Log in to CMS on the bootstrap machine
IPL CMS
Create the exec file to punch the other files (kernel, parm file, initramfs) to start the linux installation on each linux servers part of Openshift cluster using the mdisk 191, this example shows the bootstrap exec file:
/* EXAMPLE EXEC FOR OC LINUX INSTALLATION */
TRACE O
'CP SP CON START CL A *'
'EXEC VMLINK MNT3 191 <1191 Z>'
'CL RDR'
'CP PUR RDR ALL'
'CP SP PU * RDR CLOSE'
'PUN KERNEL IMG Z (NOH'
'PUN BOOTSTRAP PARM Z (NOH'
'PUN INITRAMFS IMG Z (NOH'
'CH RDR ALL KEEP NOHOLD'
'CP IPL 00C'
The line EXEC VMLINK MNT3 191 <1191 Z> shows that the disk from the repository VM will be linked to this VM's EXEC process, making the files we already transferred to the the repository VM's local disk available to the VM where this EXEC file will be run, for example the bootstrap VM.
Call the EXEC file to start the bootstrap installation process:
<BOOTSTRAP> EXEC
Once the installation of the Red Hat CoreOS finishes, make sure to re-IPL this VM so it will load the Linux OS from it's internal DASD:
#CP IPL 201
The you will see the RHCOS loading from it's internal mode 54 dasd disk:
Red Hat Enterprise Linux CoreOS 42s390x.81.20200131.0 (Ootpa) 4.2"
SSH host key: <SHA256key>"
SSH host key: : <SHA256key>"
SSH host key: <SHA256key>"
eth0.1100: ,<ipaddress> fe80::3ff:fe00:9a"
bootstrap login:
Repeat this procedure for the other machines in the cluster, which means applying the same steps for creating the Red Hat Enterprise Linux CoreOS with the respective changes to master0, master1, master2, compute0 and compute1.
Make sure to include IPL 201 into the VMs definition so whenever the VM goes it will automatically IPL the disk 201 disk (RHCOS), example:
USER LNXDB030 LBYONLY 16G 32G
INCLUDE DFLT
COMMAND DEFINE STORAGE 16G STANDBY 16G
COMMAND DEFINE VFB-512 AS 0101 BLK 524288
COMMAND DEFINE VFB-512 AS 0102 BLK 524288
COMMAND DEFINE VFB-512 AS 0103 BLK 524288
COMMAND DEFINE NIC 1E00 TYPE QDIO
COMMAND COUPLE 1E00 SYSTEM VSWITCHG
CPU 00 BASE
CPU 01
CPU 02
CPU 03
IPL 201
MACHINE ESA 8
OPTION APPLMON CHPIDV ONE
POSIXINFO UID 100533
MDISK 0191 3390 436 50 USAW01
MDISK 0201 3390 1 END LXDBC0
Creating the cluster
To create the OpenShift Container Platform cluster, you wait for the bootstrap process to complete on the machines that you provisioned by using the Ignition config files that you generated with the installation program
Monitor the bootstrap process:
$ ./openshift-install --dir=<installation_directory> wait-for bootstrap-complete --log-level=debug
After bootstrap process is complete, remove the bootstrap machine from the load balancer
Logging in to the cluster
You can log in to your cluster as a default system user by exporting the cluster kubeconfig file. The kubeconfig file contains information about the cluster that is used by the CLI to connect a client to the correct cluster and API server. The file is specific to a cluster and is created during OpenShift Container Platform installation
Export the kubeadmin credentials:
$ export KUBECONFIG=<installation_directory>/auth/kubeconfig
Verify you can run oc commands successfully using the exported configuration:
$ oc whoami
system:admin
Review the pending certificate signing requests (CSRs) and ensure that the you see a client and server request with Pending or Approved status for each machine that you added to the cluster:
$ oc get csr
NAME AGE REQUESTOR CONDITION
csr-2qwv8 106m system:node:worker1.<domain> Approved,Issued
csr-2sjrr 61m system:node:worker1.<domain> Approved,Issued
csr-5s2rd 30m system:node:worker1.<domain> Approved,Issued
csr-9v5wz 15m system:node:worker1.<domain> Approved,Issued
csr-cffn6 127m system:servi…:node-bootstrapper Approved,Issued
csr-lmlsj 46m system:node:worker1.<domain> Approved,Issued
csr-qhwd8 76m system:node:worker1.<domain> Approved,Issued
csr-zz2z7 91m system:node:worker1.<domain> Approved,Issued
Check if all the nodes are Ready and healthy:
$ oc get nodes
NAME STATUS ROLES AGE VERSION
master0.<domain> Ready master 3d3h v1.14.6+c383847f6
master1.<domain> Ready master 3d3h v1.14.6+c383847f6
master2.<domain> Ready master 3d3h v1.14.6+c383847f6
worker0.<domain> Ready worker 3d3h v1.14.6+c383847f6
worker1.<domain> Ready worker 3d3h v1.14.6+c383847f6
Now it's safe to shutdown the bootstrap VM.
Initial Operator configuration
After the control plane initializes, you must immediately configure some Operators so that they all become available.
Watch the cluster components come online (wait until all are True in the AVAILABLE column :
$ watch -n5 oc get clusteroperators
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE
authentication 4.2.0 True False False 69s
cloud-credential 4.2.0 True False False 12m
cluster-autoscaler 4.2.0 True False False 11m
console 4.2.0 True False False 46s
dns 4.2.0 True False False 11m
image-registry 4.2.0 False True False 5m26s
ingress 4.2.0 True False False 5m36s
kube-apiserver 4.2.0 True False False 8m53s
kube-controller-manag 4.2.0 True False False 7m24s
kube-scheduler 4.2.0 True False False 12m
machine-api 4.2.0 True False False 12m
machine-config 4.2.0 True False False 7m36s
marketplace 4.2.0 True False False 7m54m
monitoring 4.2.0 True False False 7h54s
network 4.2.0 True False False 5m9s
node-tuning 4.2.0 True False False 11m
openshift-apiserver 4.2.0 True False False 11m
openshift-controller- 4.2.0 True False False 5m43s
openshift-samples 4.2.0 True False False 3m55s
operator-lifecycle-man 4.2.0 True False False 11m
operator-lifecycle-ma 4.2.0 True False False 11m
service-ca 4.2.0 True False False 11m
service-catalog-apiser 4.2.0 True False False 5m26s
service-catalog-contro 4.2.0 True False False 5m25s
storage 4.2.0 True False False 5m30s
You will notice that the image-registry operator shows False, to fix this follow these steps:
$ oc patch configs.imageregistry.operator.openshift.io cluster --type merge --patch '{"spec":{"storage":{"emptyDir":{}}}}'
Once the the file gets patched it will automatically make sure that the image-registry container follow that state.
This is how the command $ oc get co (abbreviation of clusteroperators) should look like
$ oc get clusteroperators
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE
authentication 4.2.0 True False False 69s
cloud-credential 4.2.0 True False False 12m
cluster-autoscaler 4.2.0 True False False 11m
console 4.2.0 True False False 46s
dns 4.2.0 True False False 11m
image-registry 4.2.0 True False False 1ms
ingress 4.2.0 True False False 5m36s
kube-apiserver 4.2.0 True False False 8m53s
kube-controller-manag 4.2.0 True False False 7m24s
kube-scheduler 4.2.0 True False False 12m
machine-api 4.2.0 True False False 12m
machine-config 4.2.0 True False False 7m36s
marketplace 4.2.0 True False False 7m54m
monitoring 4.2.0 True False False 7h54s
network 4.2.0 True False False 5m9s
node-tuning 4.2.0 True False False 11m
openshift-apiserver 4.2.0 True False False 11m
openshift-controller- 4.2.0 True False False 5m43s
openshift-samples 4.2.0 True False False 3m55s
operator-lifecycle-man 4.2.0 True False False 11m
operator-lifecycle-ma 4.2.0 True False False 11m
service-ca 4.2.0 True False False 11m
service-catalog-apiser 4.2.0 True False False 5m26s
service-catalog-contro 4.2.0 True False False 5m25s
storage 4.2.0 True False False 5m30s
Monitor for cluster completion:
$ ./openshift-install --dir=<installation_directory> wait-for install-complete
INFO Waiting up to 30m0s for the cluster to initialize...
The command succeeds when the Cluster Version Operator finishes deploying the OpenShift Container Platform cluster from Kubernetes API server.
INFO Waiting up to 30m0s for the cluster at https://api.<cluster_name>.<domain>:6443 to initialize...
INFO Waiting up to 10m0s for the openshift-console route to be created...
INFO Install complete!
INFO To access the cluster as the system:admin user when using 'oc', run 'export KUBECONFIG=/root/<installation-directory>/auth/kubeconfig'
INFO Access the OpenShift web-console here: https://console-openshift-console.apps.<cluster-name>.<domain>
INFO Login to the console with user: kubeadmin, password: 3cXGD-Mb9CC-hgAN8-7S9YG
Login using a web browser: http://console-openshift-console.apps.<cluster-name>.<domain>
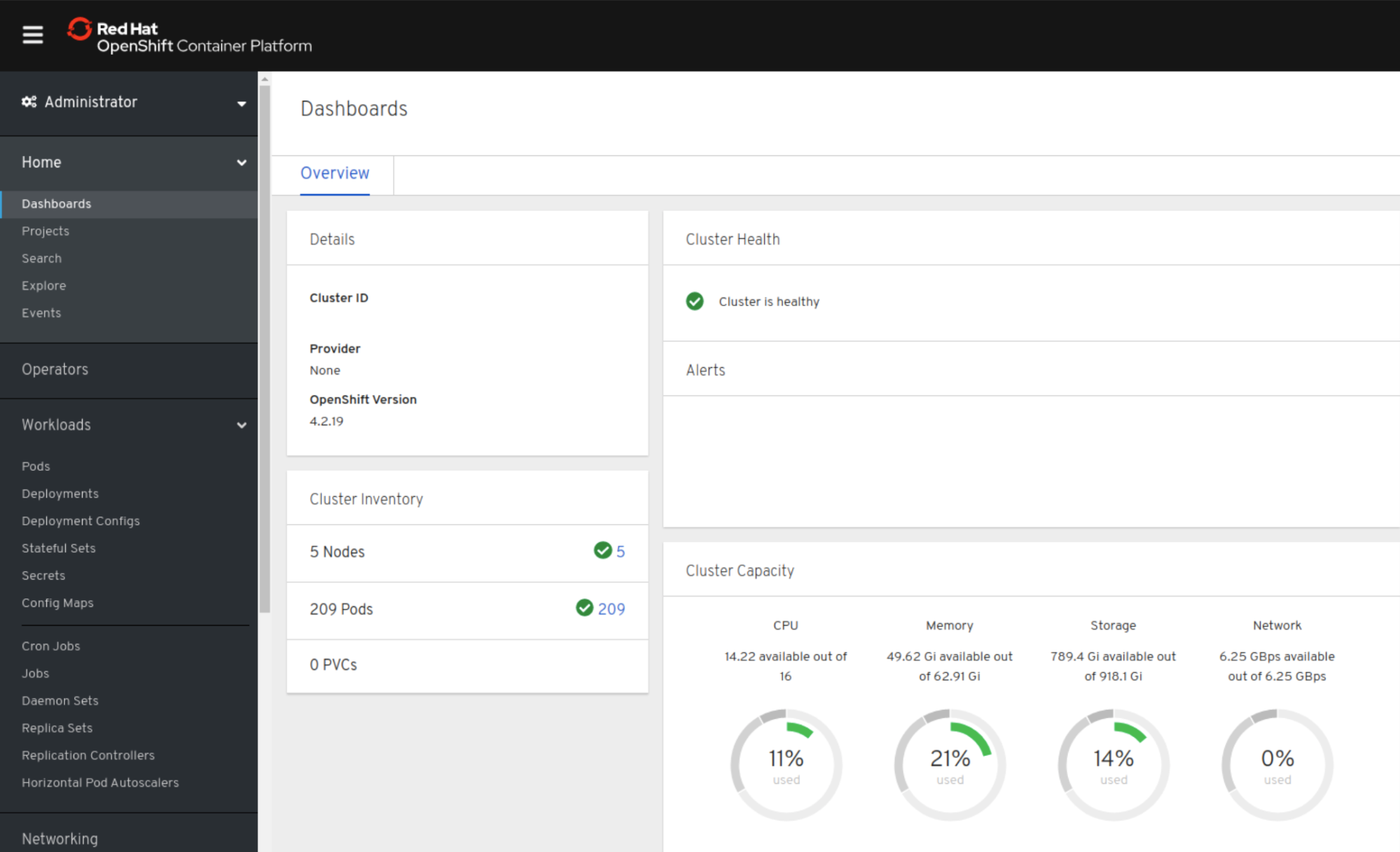
This article only covers the installation process, for day 2 operations, keep in mind that no storage was configured for workloads that requires persistent storage. As for now, Red Hat Openshift 4 is ready to be explored, the following video helps familiarize with the graphical user interface from the developer perspective:
Key people that collaborated with this article:
Alexandre de Oliveira, Edi Lopes Alves, Alex Souza, Adam Young, Apostolos Dedes (Toly) and Russ Popeil
Filipe Miranda is a Worldwide Architect Leader for Openshift on IBM Z/LinuxONE at IBM. The views expressed in this article are his alone.






