
OpenShift 4 provides unparalleled automation for cluster tasks like installation, scaling, maintenance, and security updates. OpenShift is quite similar to having a Kubernetes cluster made available as a service, complete with automated, single-click updates. Thanks to this automation, OpenShift users can manage 10-100+ node clusters without adding more personnel to their operations team.
This blog aims to prepare cluster administrators to upgrade their OpenShift fleet by providing helpful information concerning how best to utilize the platform's automated cluster update processes.
There are five key tenets for each OpenShift update release:
- No downtime
OpenShift Updates should not cause downtime for existing applications as long as the applications, cluster, and underlying cluster infrastructure implement all Kubernetes best practices to ensure high availability. - Pause on blocking errors
A cluster should be allowed to pause on any blocking failures during an update whenever possible. All components are self-healing, and most errors must have no noticeable effect on operation. An administrator can then use this pause to take corrective action or restore the system to a safe state. - Fail-forward
The OpenShift update design focuses on always rolling forward if bugs are encountered. OpenShift doesn't support rollback. Also, the Kubernetes API migrations are not always reversible and vary from component to component; thus OpenShift components are forward and backward-compatible only within a range of versions due to version skew policy. - Fully Managed
The Cluster Administrator can control every aspect of their cluster, from the operating system to the control plane and any additional components. - Uniform update experience
The day-2 operations are standard and consistent across all installations on OpenShift. Updating a multi-node cluster that has been properly provisioned by either the user or the installer will be a repeatable and consistent experience.
These tenets are fundamental to OpenShift, and they can be seen as we dive into how the OpenShift update and release process works. Applications that implement Kubernetes best practices for highly available applications are all you need to be successful with OpenShift, but a deeper understanding of the process can propel your success even further.
OpenShift is driven by Operators
Before proceeding further, let us understand what an OpenShift "release" means. OpenShift releases consist of a collection of tested and released Operators and changes to the machine. OpenShift is pre-configured to automate the deployment, maintenance, and scalability of business applications. OpenShift includes everything software builders need for continuous integration and continuous delivery, logging and monitoring data, and more. This includes a container registry, storage, networking, security, and many more cluster services. Each of these capabilities is built from a number of interdependent parts that must work together to coordinate their configuration, scale individually, and update cooperatively. These parts and functions are contained within Operators.
Operators in OpenShift contain the required operational knowledge to make OpenShift a highly available system. Each Operator understands precisely what it must do during an update, how to safely enable new product features, and how to reconcile a cluster admin's preferred configuration with best practices.
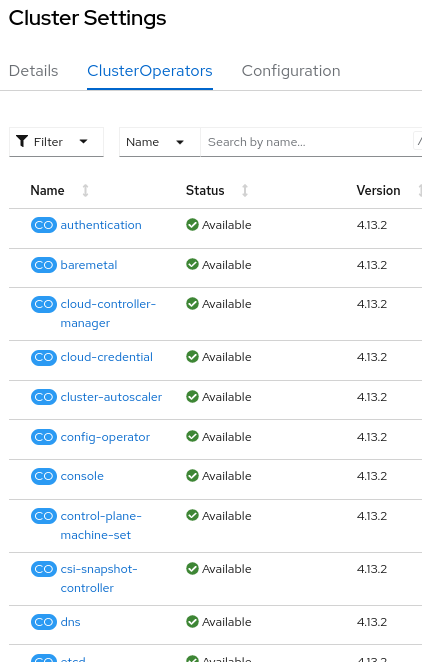
Image-1: ClusterOperators shown in OpenShift Console.
All of the Cluster Operators that make up a given OpenShift version can be viewed inside the cluster settings section of the OpenShift Console(see Image-1), as well as through the OpenShift CLI.
# command to show all cluster operators.
$ oc get clusteroperator
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE
console 4.13.2 True False False 86m
control-plane-machine-set 4.13.2 True False False 96m
dns 4.13.2 True False False 97m
etcd 4.13.2 False False False 25m
image-registry 4.13.2 True False False 91m
kube-apiserver 4.13.2 True False False 86m
kube-controller-manager 4.13.2 True False False 94m
kube-scheduler ...
OpenShift Releases

Image-2: Semantic versioning scheme for OpenShift release versions
OpenShift follows a semantic versioning scheme, where version number x.y.z corresponds to major.minor.patch. For Openshift 4.y.z, there are two kinds of releases, the y-release and the z-stream(patches) release. We’ll cover them below.
Z-Stream release
OpenShift releases security patches and bug fixes each week for all supported versions. This ongoing series of revisions is named "z-stream" per the semantic versioning scheme.
Each Z-stream release is made available after a lot of testing, and the releases are available every week for the latest Y-release. For older Y-releases, it may take much longer for new Z-stream releases to be made available. Each z-stream update is risk-free to deploy, has no impact on cluster behavior, and no changes to the API. Our intent is to make performing z-stream updates something our customers embrace.
Y-Stream release
When you read about new OpenShift features in an errata, blog post, or tweet, you are usually reading about the most recent y-stream, which is a minor release with new product enhancements and an improvement over a z-stream. During these periods, new versions of Kubernetes, OS features, Operators, automation enhancements on IaaS providers, and other added benefits become available.
Each OpenShift release payload contains the required changes which need to be made to the cluster operators and the nodes.
OpenShift Lifecycle
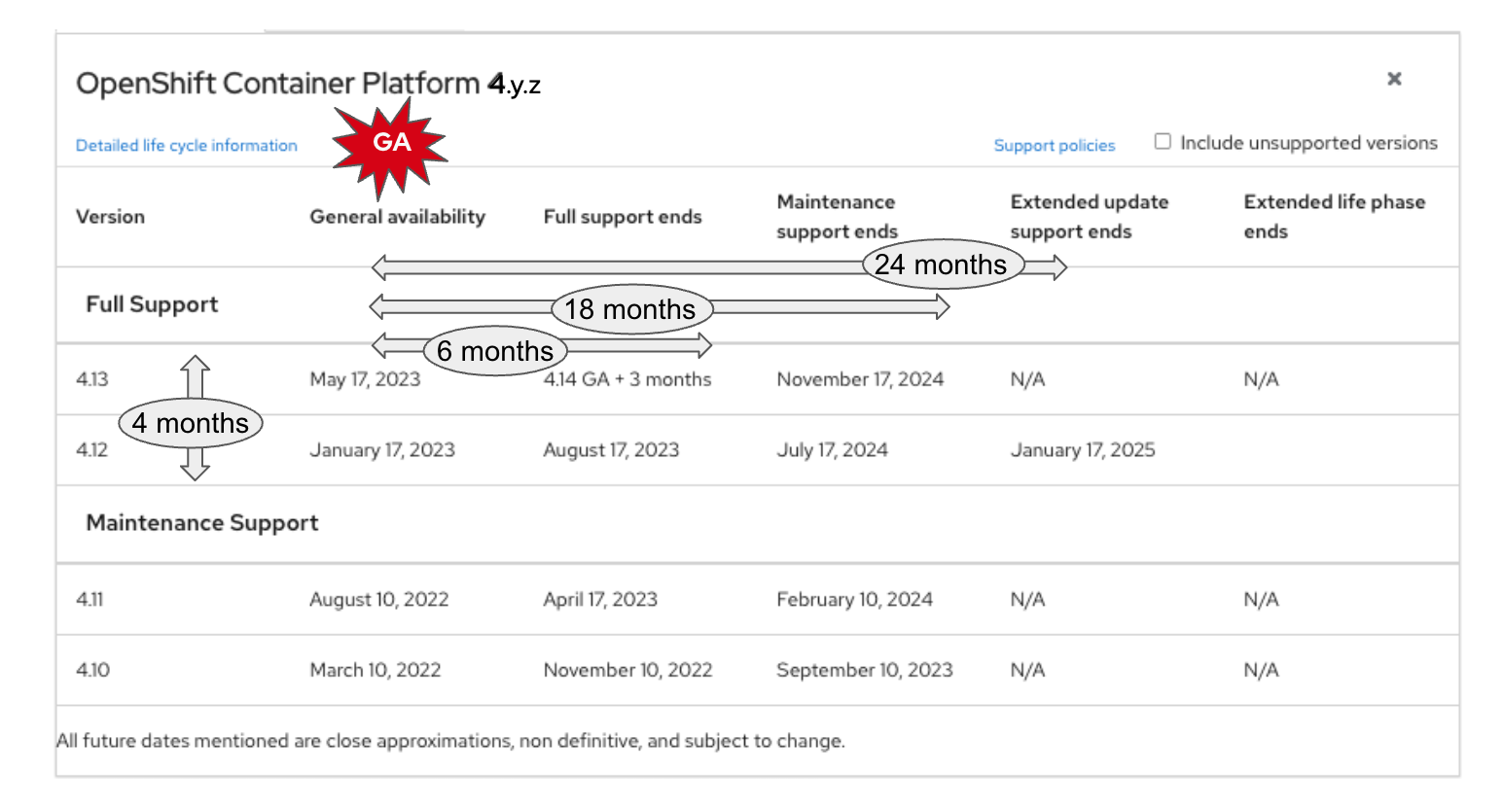
Image-3: OpenShift Lifecycle
As depicted in Image-3, the Y-releases GAs are done approximately every 4 months. We closely align the OpenShift release with the upstream Kubernetes release. The important point to note is that all releases have 18 months of support, of which 6 months are full support, wherein we release weekly z-releases for bugs and CVEs. Once the full-support period ends, the customer has another 12 months of maintenance support, where support is given for updates only. With EUS, which we will cover later, the customer has extended update support for a total of 24 months, which gives much relief to the customers who can’t update often and have a longer update window. Refer to the Red Hat OpenShift Container Platform Life Cycle Policy for more information.
Release Channels
OpenShift version 4.y.z installations and updates come with a selection of "channels" to connect the new or an existing cluster to. You can select between candidate, fast, or stable channels(as shown in Image-4). On the OpenShift web-console, the cluster administrator has to choose the channel before an update can be initiated.

Image-4: Channel can be changed by selecting the edit icon.
# use the below commands to select the channel and update to a specific version
oc adm upgrade channel <channel>
oc adm upgrade --to=<version>
As shown in Image-5, a new release is initially added to the candidate channel and, after a lot of successful testing, promoted to the fast channel. The red boxes above highlight the three main points when an issue might be identified and what is done about it. The new, fully supported releases are broadly available on both fast and stable channels, and what sets these two channel variants apart is the release timing. Red Hat's automated testing is improved by information gleaned from all channels (including candidate, fast, and stable channels).
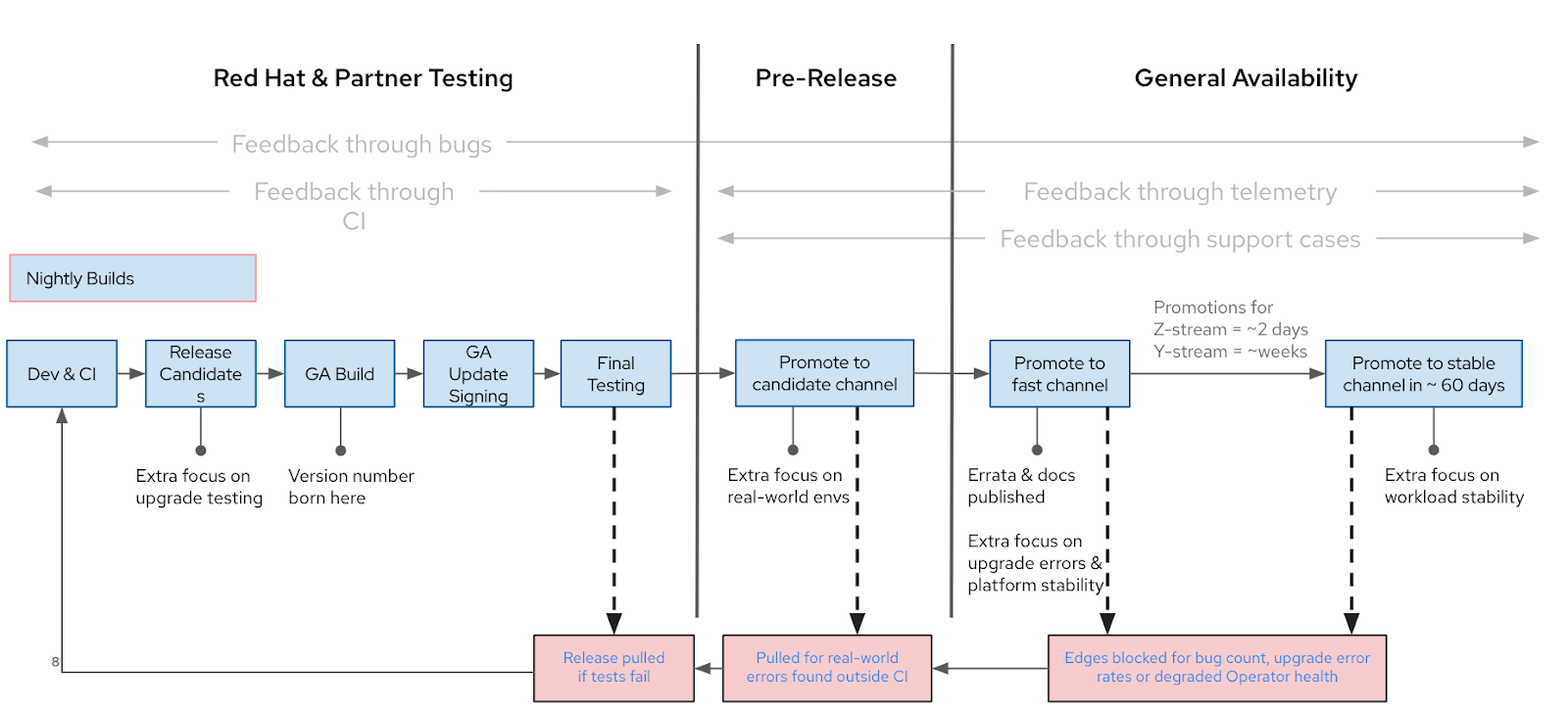
Image-5: OpenShift Release process
Because of this "fast before stable" pattern, when a new y-stream or minor version of OpenShift is released, there will be no update pathways available on the stable channel. In the background, our engineering teams collect data and evaluate many criteria, such as customer tickets and the insights gained from Red Hat consultants working with clients. This usually takes 45-90 days. Once the minor version is promoted to the stable channel, it is simultaneously promoted in the EUS channel. If post-release, we find certain bugs that warrant blocking one or both of these channels from updating to a certain version, then create a conditional update path.
Conditional Updates
Sometimes we remove an update path from the OpenShift Update Service (OSUS) to prevent update problems with OpenShift clusters. This update path adjustment affects all OpenShift clusters using a specific z-release.
We've taken note of the frustration that arises when a defect affects a few specific OpenShift clusters with certain platforms or configurations, and we block the edge for all clusters, including unaffected ones.
To ensure a more seamless experience from OpenShift 4.10, the OSUS will recommend conditional updates to the Cluster Version Operator (CVO). CVO, an OpenShift component responsible for the update procedure, will analyze cluster metadata intelligently and determine whether it's appropriate to apply an update for a particular cluster or not. Due to the Conditional update feature, OpenShift will not block update paths from version 4.10 onwards. Our goal is to minimize any disruptions and improve the user experience. See Introducing Conditional OpenShift Updates to learn more about conditional updates.

Image-6: Conditional update path between 4.12.10 to 4.12.18
As shown in Image-6, for non-recommended updates to the cluster, the cluster administrator can easily obtain metadata like risk descriptions and documentation links that details what may happen to assess risk.
Extended Update Support (EUS) Update
It was once the case that a new minor version of Kubernetes or OpenShift would be released every three months; however, these communities have lately shifted to a four-month release cadence. The rapid pace of innovation and the serialized nature of Kubernetes' minor version updates have caused certain customers to be unable to keep up with the innovation. It takes work to catch up when you lag behind.
We created EUS-to-EUS updates with this concern in mind. From OpenShift 4.8, all even-numbered minor releases (for example, 4.8, 4.10, and 4.12) are Extended Update Support (EUS) releases. Customers with Premium subscriptions or Standard subscriptions + an add-on SKU can use EUS. EUS provides companies with the option to apply important security updates and urgent bug fixes to a specific range of Red Hat OpenShift minor versions. This allows businesses to maintain production environments for their mission applications by using the same minor release of OpenShift for a period of 24 months. We have also reduced the maintenance steps required to maintain a supported, long-lived cluster by making it easier for administrators to update their clusters between EUS versions with less impact on workloads and providing updates that take less time. OpenShift minor version updates are sequential due to Kubernetes Version Skew Policies, which require serialized updates of all components other than the Kubelet. We cannot skip a minor version. More on EUS here.
What happens in an OpenShift Update?
With the stated goals of having zero application downtime and automation built into the Operators, updating OpenShift is reduced to a single click. Updating the OpenShift cluster involves updating the worker and control plane node pools and also the operators running in the nodes. Node pools are used for grouping together specific hardware configurations (such as GPUs).
To understand the update process after you click the update button, we need to delve more into the terms like OpenShift Update Service(OSUS), Cluster Version Operator (CVO), and MachineConfig Operator(MCO). These terms will be explained below.
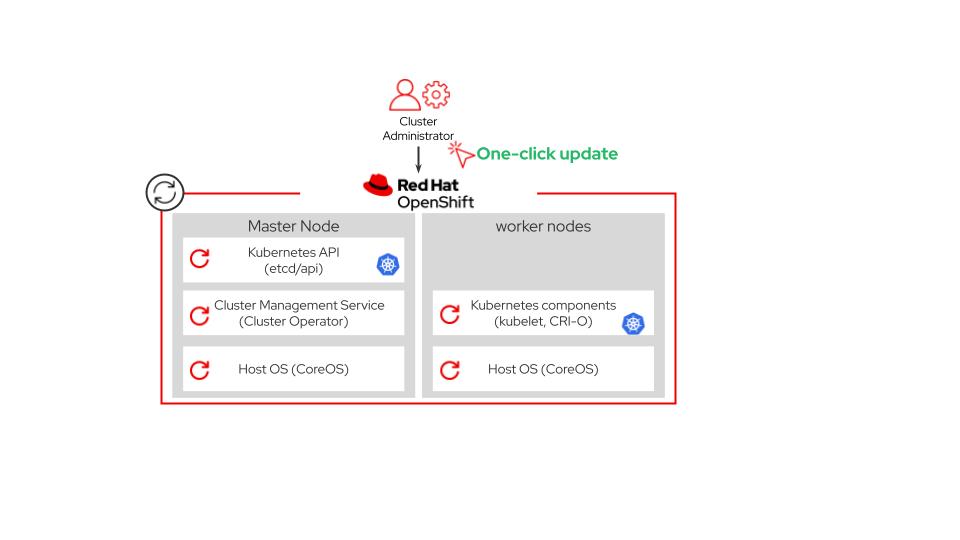
Image-7: OpenShift update process
The OpenShift Update Service (OSUS)
Red Hat offers over-the-air updates for internet-connected clusters via a hosted OpenShift Container Platform update service accessible via public APIs. This service is called the OpenShift Update Service (OSUS). The updates to the OpenShift Container Platform, including the underlying Red Hat Enterprise Linux CoreOS (RHCOS), are made available by OSUS. It accomplishes this by serving update recommendations to client clusters. Cluster administrators can review these recommendations and initiate cluster updates.
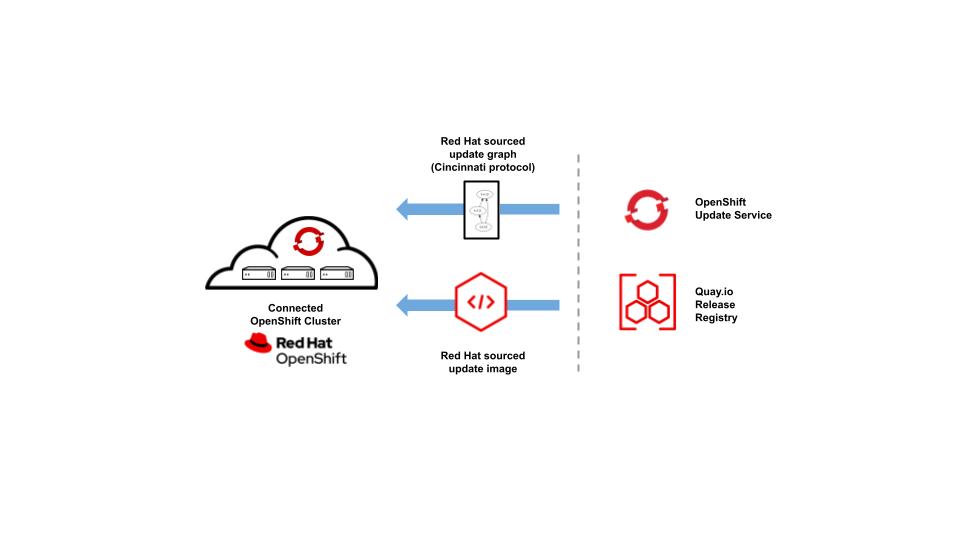
Image-8: OpenShift Update in connected Network
The Cluster Version Operator (CVO) in your connected cluster is configured to check with the OpenShift Update Service (OSUS) to see the valid updates and update paths based on the current OpenShift version. The OSUS is smart enough to know which version is recommended for your cluster, and as shown in Image-6, the recommended and non-recommended version information is shown in the OpenShift web-console.
Cluster Version Operator (CVO)
When a cluster administrator or automatic update controller updates the Cluster Version Operator (CVO)'s custom resource (CR), an update begins. The CVO downloads the target release image from an image registry and applies changes to the cluster to reconcile it with the new version. Thus, the Cluster Version Operator (CVO) starts the update process for the cluster. There is a logical order in which the individual cluster Operators must be updated to minimize disruption in the cluster.
#use below command to see the status of update
$ oc get clusterversion
NAME VERSION AVAILABLE PROGRESSING SINCE STATUS
version 4.12.10 True True 42m Working towards 4.12.25: 672 of 831 done (80% complete), waiting on network

Image-9: Runlevel 25 will start after runlevel 20 completes successfully
When updating the cluster to a new version, the CVO applies manifests in separate stages called Runlevels(shown in Image-9). Runlevels take care of the logical order. As the CVO applies a manifest to a cluster Operator, the Operator might perform update tasks to reconcile itself with its new specified version. The CVO monitors the state of each applied resource and the states reported by all cluster Operators. The CVO only proceeds to the next runlevel with the update when all manifests and cluster Operators in the active Runlevel are stable. After the CVO updates the entire control plane through this process, the Machine Config Operator (MCO) updates the operating system and configuration of every node in the cluster.

Image-10: Updating control plane and worker nodes.
Machine Config Operator
The Machine Config Operator (MCO) is another important operator after CVO. It manages changes to systemd, CRI-O and Kubelet, the kernel, Network Manager, and other system features. The change in config is captured in the machine config CRD. Once the MachineConfig changes are applied to the nodes, the nodes have to reboot. The MCO updates the number of nodes as specified by the maxUnavailable field on the machine configuration pool(MCP), used to associate MachineConfigs with Nodes at a time. If the maxUnavailable is set to 1, then the nodes on the control node pool and worker node pool are updated sequentially (as shown in Image-11). Increasing maxUnavailable on the MCP can help the pool to update more quickly. The update initiated by MCO involves a sequence of actions on nodes in the pool: Cordon and drain the node, OS Update, Reboot, and Uncordon.
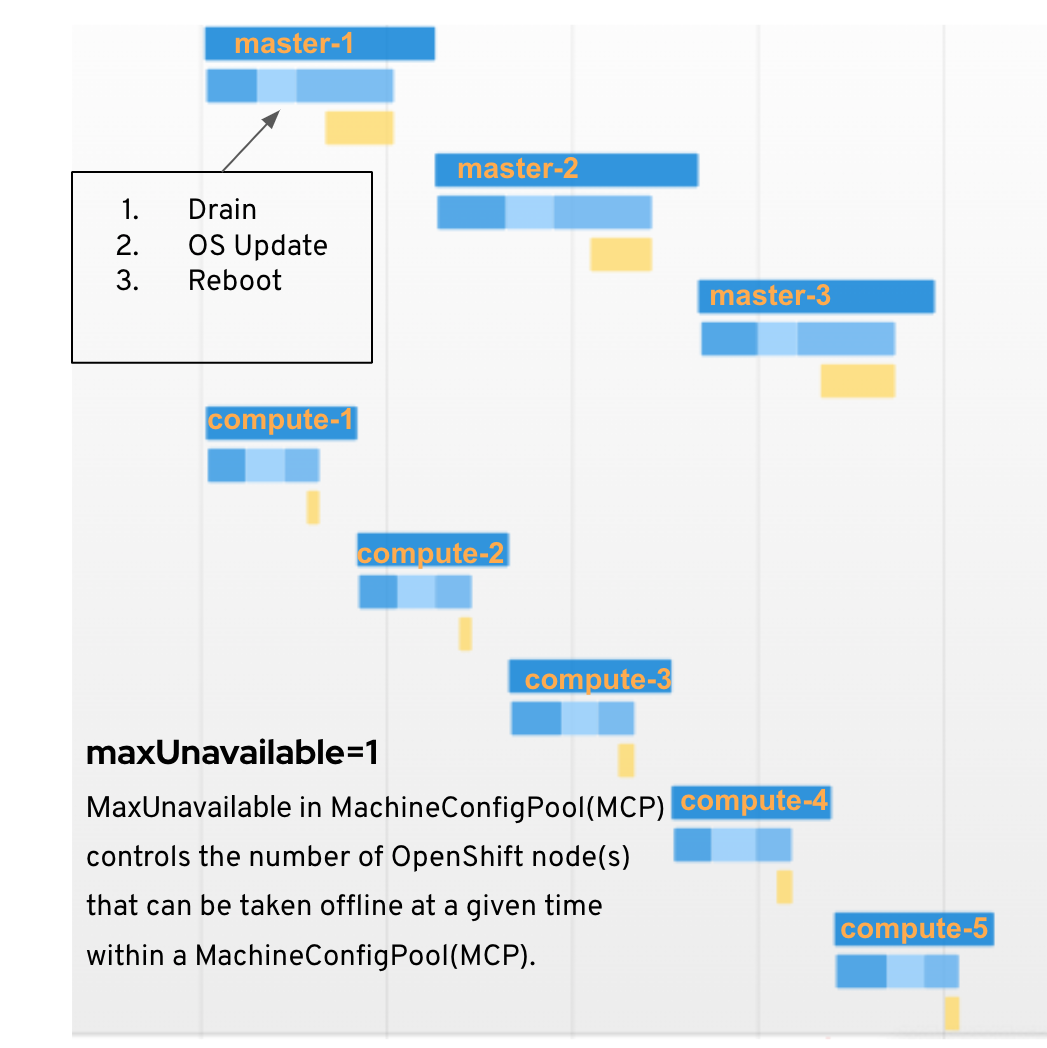
Image-11: maxUnavailable=1 updates node sequentially.
Updating the control plane
A release image contains the release metadata, every manifest needed to deploy individual OpenShift cluster Operators and a list of SHA digest-versioned references to all container images that make up this OpenShift version. OpenShift update can be done using the CLI or web console. During the OpenShift update process, the CVO validates the integrity and authenticity of the release image, thus ensuring the security aspects of the image. And then, CVO checks the Operators' health at regular intervals while systematically implementing the desired state modifications by applying the manifests from the release image. First, the cluster operators are updated(as shown in image-12); next, the nodes running the control plane and worker nodes have their operating system and configuration changed.
Container downloads, component reconfigurations, and Node restarts typically take up to an hour when upgrading a 3-node Control Plane. The Console is where you can see everything unfold in real-time. The time required to update the Control Plane is proportional to the cluster’s Node count. Refer to Understanding OpenShift Update time to estimate how long updates would take in your environment. The control-plane portion of the update takes 60 to 120 minutes; the compute nodes update portion depends on node count.

Image-12: Progress of Update shown in web-console
There shouldn't be any interruptions in service to the Kubernetes API, etcd database, or cluster ingress/routing at this time. The cluster operators are updated in-place, and there is no disruption to the workloads. The Control Plane update will be marked as complete once it is finished.
Updating the Worker Nodes
Machine Config Operator (MCO) manifests is applied toward the end of the control plane update process. The MCO then begins updating the system configuration and operating system of every node. Updates to the Worker Nodes and Control Plane nodes are done by MCO, and each node must be drained, updated, and rebooted before it starts to accept workloads again. This is shown in Image-11.
Factors beyond the control of the cluster can slow down or even halt the rollout of your worker nodes. For example, PodDisruptionBudgets, affinity/anti-affinity rules, resource limitations, Readiness/Liveness probes, and so on are used in applications to make them highly available and resilient throughout the update process and thus can affect or impede updates.
Canary Rollout Update
Canary update is helpful for the controlled rollout of an update to the worker nodes in order to ensure that mission-critical applications stay available during the whole update. This is done by creating a custom (MachineConfigPool) MCP. As you already know, there are two default MCPs in the cluster: one for the control plane nodes and one for the worker nodes. To prevent specific nodes from being updated, Cluster Administrators can create custom MCPs for these nodes. When we pause those MCPs, then the nodes associated with those MCPs are not updated by MCO during the update process.
Connected and disconnected OpenShift Cluster
OpenShift updates can be performed in both connected and disconnected clusters. We aim to ensure the update experience is consistent for our customers.Image-13 captures the difference in the update experience of connected and disconnected clusters.
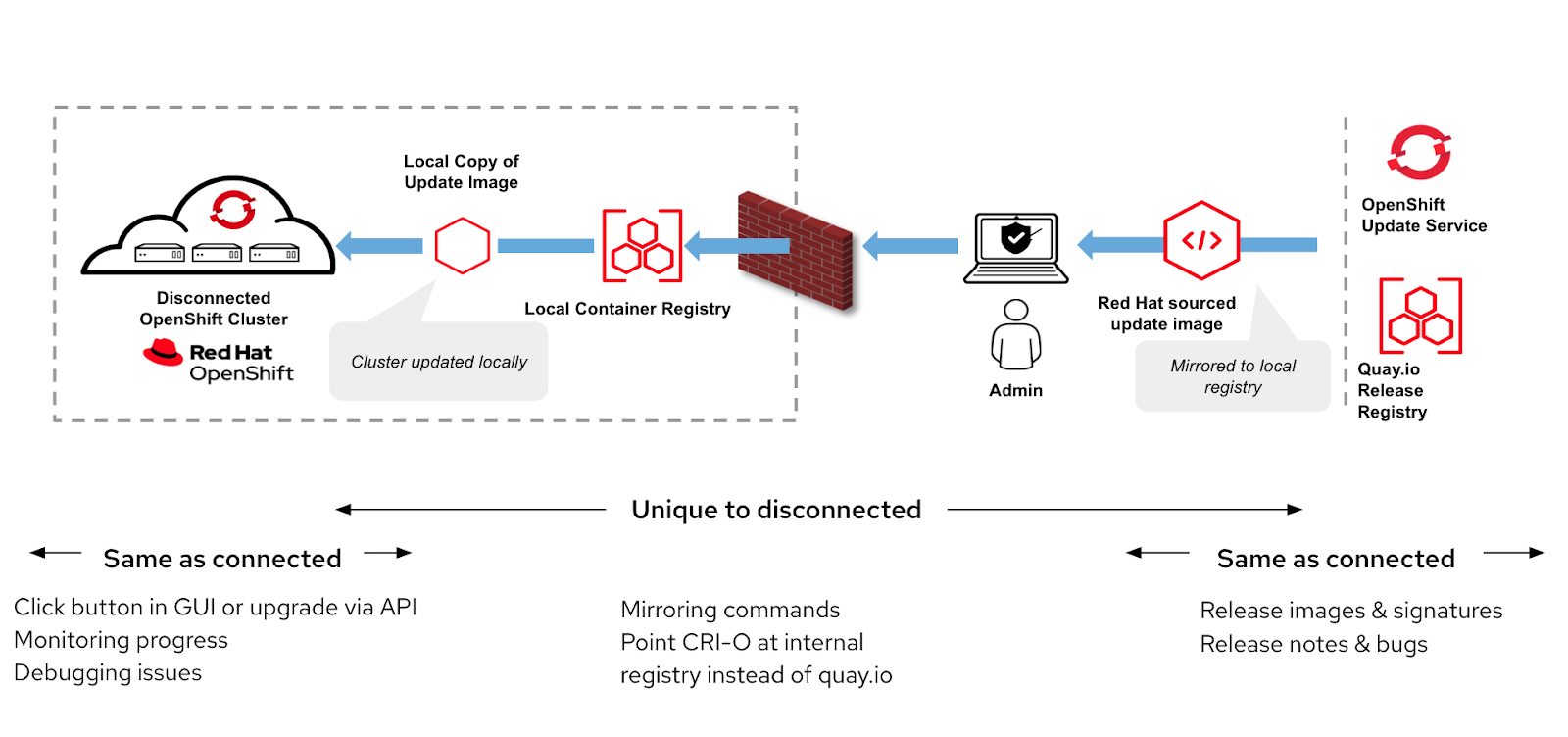
Image-13: Updates in Connected vs Disconnected OpenShift Cluster
Cluster Update in Connected Network
By default, OpenShift clusters in internet-accessible environments receive updated information from a publicly hosted OSUS by Red Hat OpenShift clusters, regularly connect to the hosted OSUS to report the cluster's health and check for updates(as shown in Image-8). After the cluster's parameters(like architecture x86, arm, version) have been reported to the hosted service, it sends a cluster-specific update graph with a list of recommended update versions that can be securely applied by CVO. If a new update is available, administrators can see it in the web console and can update to the new version with a single click.
Cluster Update in Disconnected Environment
A disconnected environment is one in which your cluster nodes cannot access the internet.Similar update experience, as mentioned above, in a connected network can be expected in disconnected clusters(as shown in Image-13), albeit with increased curation efforts from administrators. Once all of the containers and metadata are loaded into the container registry behind your firewall using a local OpenShift Update Service architecture, you will enjoy the same update experience as a connected cluster. Mirroring the release images to the local registry can be done oc-mirror tool.

Note that moving release images required for disconnected clusters is still a manual process, but the rest of the update experience, like setup & connecting to the local OSUS operator, can all be automated.
The cluster administrator is responsible for selecting the release to update. To do this, you need to analyze the update path app tool or look at errata at the point in time when you begin mirroring to determine which OpenShift versions are available in the channel. The update path app tool provides a visual representation of the Update graph by channel and is useful for selecting the release versions. We cover more details about mirroring and OSUS operator and updating Operator Lifecycle Manager (OLM) operators below.
Mirroring Images
Mirroring container images onto a mirror registry is the first step before you can update a cluster in a disconnected environment. You can get the oc-mirror plugin from the Downloads page of the OpenShift Cluster Manager Hybrid Cloud Console. Before you can use the oc-mirror plugin, you must create an image set configuration file that defines which OpenShift releases, Operators, and other images to mirror, along with other configuration settings for the oc-mirror plugin. After you populate your target mirror registry with the initial image set, you must update it regularly so that it has the latest content. You can also set up a cron job to automate this.
OSUS Operator
After mirroring is complete, the cluster administrator has to install the OSUS operator to get an update experience similar to connected clusters. The metadata contained within the OpenShift release payloads stored in the local container registry is used by the graph-builder component of OSUS to construct an update graph. Once the on-premises OpenShift Update Service endpoint has been configured in the Cluster Version Operator (CVO), the cluster can benefit from the policy engine ( a cluster-specific filter that returns cluster-specific update recommendations) as soon as the release-payload has been mirrored to the neighborhood container registry. This allows administrators to quickly and easily update clusters using the web portal or command line interface.

Image-14: OSUS provides recommendations to the cluster when configured to use the local registry.
It is also possible to update a cluster without using OSUS instead, using the `oc adm upgrade` command with the --to-image option, where you must reference the sha256 digest that corresponds to your targeted release image. The cluster administrator also has to configure the OpenShift cluster to redirect requests to pull images from a repository on a source image registry and have it resolved by a repository on a mirrored image registry.
Rollback and Backup
OpenShift clusters cannot be rolled back from an ongoing update to the previous version. It is recommended to have a recent etcd backup in case your update is problematic and you like to restore your cluster to a previous state. Note that you must use an etcd backup that was taken from the same z-stream release, and then you can restore the OpenShift cluster from the backup. For problematic updates, refer to troubleshooting guide for self-service option.
Best wishes for an upgrade!
In conclusion, We sincerely hope this guide has provided cluster administrators with the ultimate resource for navigating the OpenShift release and update process. By understanding the key concepts and components outlined here, administrators can orchestrate smooth and efficient updates. We appreciate your participation in this journey through the OpenShift release and update process. Best wishes for an upgrade!
About the author
Subin Modeel is a principal technical product manager at Red Hat.
More like this
Why Operational Resilience and Digital Sovereignty Top the CIO Agenda
How Red Hat OpenShift 4.22 impacts enterprise AI’s bottom line
Crack the Cloud_Open | Command Line Heroes
Edge computing covered and diced | Technically Speaking
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds