
Since the earliest OpenShift 3.x versions, a load balancer has been required for the API and ingress services. This allows the cluster nodes to scale up, down, and recover from failure transparently (or nearly transparently) from the perspective of the clients. OpenShift 4 is no different and requires a load balancer to provide a common, highly available endpoint for client access. OpenShift 4’s different installation experiences, which are user provisioned (UPI), installer provisioned (IPI), and non-integrated, levy different requirements on the administrator for configuring the load balancers depending on the installation type and infrastructure platform.
When deploying IPI to a hyperscaler, the provider’s load balancer service is deployed and configured using the installer during installation and managed by an operator afterward. But what about on-premises IPI, where there is not a common and predictable API-enabled load balancer service? On-premises IPI clusters still need a load balancer for all the same reasons, so how is that requirement met?
Let’s start by looking at the load balancer requirements for OpenShift clusters.
Load balanced endpoints
The first thing to understand is that there are two primary endpoints that need load balancing: API (api.clustername.domainname) and ingress (*.apps.clustername.domainname). The API endpoint is served by the control plane nodes on port 6443. It is where clients, both internal and external, such as the oc CLI, connect to the cluster to issue commands and otherwise interact with the control plane.
The second load balanced endpoint is ingress. This is backed by the ingress controllers, by default a set of HAproxy pods that are hosted by compute nodes, though it is also one of the “infrastructure” qualified workloads. This is where port 80 and 443 traffic, defined by routes, is brought into the cluster for external access to hosted applications.
Finally, there is the internal API endpoint, “api-int.clustername.domainname”. This is used by the compute nodes to interact with the OpenShift control plane. The most prominent and well-known use of this endpoint is port 22623, which is used to serve machine configuration to the nodes.
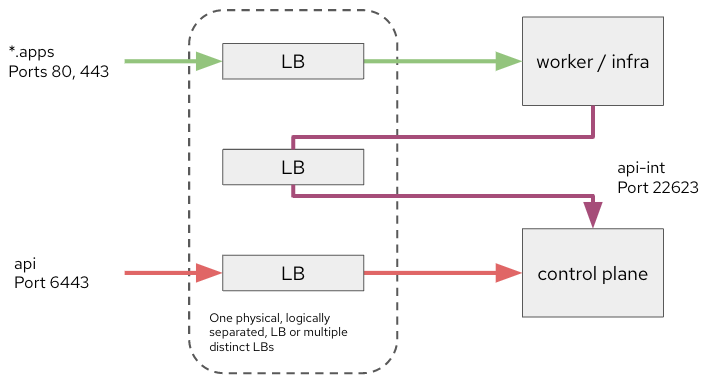
These three endpoints can be served by a single load balancer or from multiple load balancers. The api-int endpoint can, and should, have limited access so that only cluster nodes are able to access it since the machine configuration files may have sensitive data in them. If you have multiple ingress controllers, for additional domain names or if you are using sharding, then each of those will also need a load balancer as well, which can also be shared or independent, to send traffic to each of the ingress controller instances.
These requirements are the same for all OpenShift 4 clusters, regardless of how they are deployed (IPI, UPI, or non-integrated) and what infrastructure platform (AWS, Azure, vSphere, OpenStack, and others.) is used. However, on-premises IPI deployments, specifically vSphere and RHV, OpenStack (when not using Octavia), bare metal IPI, and clusters deployed using the Assisted Installer, use a common method to provide “load balancing” for the endpoints: virtual IPs (VIP) managed by keepalived.
Keepalived “load balancing”
Keepalived is a service that provides the ability to manage virtual IP addresses across multiple hosts. In short, the participating nodes communicate with each other to elect a node to host the virtual IP address. That node then configures the IP and all traffic is sent to it. If that node is taken offline, for example to reboot for updates or because of failure, the nodes elect a new VIP host, which then configures the IP address and resumes network traffic.
With on-premises OpenShift 4 IPI clusters, there are two keepalived managed VIPs used for on-premises IPI deployments: ingress (*.apps) and API. The internal API (api-int) endpoint is managed differently and does not need a VIP. Please know that this is not the same as the keepalived operator functionality. It is deployed and configured at the host level using MachineConfig. It is not configurable for other domains, applications, or IP addresses.

This has the advantage of not requiring the administrator to configure and provide an external load balancer prior to deploying the OpenShift cluster. Instead, they only need to allocate the two IP addresses and DNS names, which are provided to the installer.Once deployed, keepalived manages the VIPs, ensuring that the API VIP is always running on a control plane node and the ingress VIP is running on a compute node (or control plane node if schedulable) hosting an ingress controller pod.
However, there are some limitations:
- First, you will notice that this results in all ingress traffic coming into a single node. If you have a very high volume of traffic, this may be a bottleneck. It is worth mentioning that a common deployment pattern with OpenShift is to use HAproxy, or a similar load balancer, deployed to a virtual machine, which has the same (potential) limitations.
- Scaling the number of ingress controllers does not result in increased ingress throughput. Instead, because the ingress VIP will only be hosted on a node with an ingress controller pod, it only increases the number of failover opportunities for the VIP.
- Creating additional domains managed by the OpenShift ingress controller can result in unexpected results. For example, let’s say that a new IngressController is created with a different domain. This will result in a second set of ingress pods, also listening on ports 80 and 443 and deployed to the compute nodes. The keepalived logic is not sophisticated enough to determine which ingress pods are responsible for which domain, so it is possible that the *.apps VIP could land on a compute node with a *.newdomain ingress pod. This would break ingress for any applications using *.apps. For this same reason, route sharding does not work either.
- For VRRP to function correctly, all nodes, both control plane and compute, must be in the same broadcast domain. This effectively means that all nodes must be on the same subnet and prevents architectures where, for example, the control plane nodes use a different subnet or infrastructure nodes are in a DMZ.
- Keepalived uses the Virtual Router Redundancy Protocol (VRRP) to identify nodes participating and eligible for hosting a VIP. Each VRRP domain representing a single VIP in the OpenShift cluster must have a unique ID to avoid conflicts when they are in the same broadcast domain. The domain IDs, one each for API and ingress, are generated automatically from the cluster name during the install process. The domain ID is an 8-bit integer; however, values are limited to whole integers between 1 and 239 due to how they are generated. Each OpenShift cluster uses two domain IDs, which makes collisions even more likely.
Unfortunately, there is no way for a new cluster to communicate with existing clusters and deconflict the VRRP domain IDs. This means that the administrator must identify the domain ID and change the cluster name should a conflict occur. You can do this using podman and the following command:
podman run quay.io/openshift/origin-baremetal-runtimecfg:4.<version> vr-ids <cluster name>

- The amount of time for keepalived to detect node failure and re-home the VIP varies, but is always greater than zero. For applications that cannot tolerate a few seconds of potential interruption, this may be an issue.
Alternatives to keepalived for Ingress
For some infrastructure types, specifically OpenStack and bare metal IPI, it is supported to “move” the DNS entries from the VIPs to an external load balancer as a day two-plus operation. This effectively allows you to have the same configuration as a user-provisioned infrastructure (UPI) deployment type. Unfortunately, at this time, this is not supported with all of the on-premises IPI infrastructure providers, most prominently vSphere.
Another workaround for this is to use an appsDomain, documented here for AWS, but it works the same with all deployments. This will result in the cluster using the configured domain for all routes; however, it does not remove or un-configure the keepalived VIPs for the default *.apps domain, which means you cannot use *.apps.clustername.domainname for the appsDomain. DNS for the domain configured as appsDomain can be pointed to an external load balancer, which would be configured the same as with UPI. One potentially significant upside to this approach is that your application’s DNS names are now decoupled from the cluster name, which can make migrating them between clusters much easier for the clients/users.

What about MetalLB in OpenShift 4.9 and later?
MetalLB, which was added with support for layer 2 mode in OpenShift 4.9 and layer 3/BGP mode in OpenShift 4.10, provides a way for applications deployed to OpenShift to request a Service with type LoadBalancer. This is useful for applications you want to expose to clients on ports other than 80 and 443. For example, this could be a MariaDB database using port 3306 or an application spanning OpenShift and external resources which is using custom ports for communication.
While this is a very useful, and powerful, capability, MetalLB cannot be used to replace either the ingress or API endpoints. MetalLB is a feature deployed after cluster deployment and not available early enough for the API, which needs to be accessible before other features and functions are deployed and configured, or default ingress domain. For ingress (*.apps), the ingress controller(s) and route mechanisms are not integrated with a service in this manner. It is possible to expose the application using MetalLB and a LoadBalancer Service and then configure DNS to point to the IP address assigned to the Service; however, this would not have the benefits of a route, such as automatically integrating certificates and others for securing communications between the clients and the application.
Choosing the right option
The keepalived solution deployed as a part of the on-premises IPI clusters, and with Assisted Installer provisioned clusters, is adequate for many scenarios, but, understandably, not suitable for all scenarios. When deploying clusters using IPI, the process is necessarily opinionated: It has to be predictable when the installer cannot directly control or configure the resource, so this limits the options available to us today. The above sections describe some alternatives, such as using an appsDomain or MetalLB, but sometimes you need a traditional load balancer with your OpenShift deployment. If you must have a traditional load balancer with your cluster, then using the UPI deployment method is the best way.
Deploying a cluster using the UPI method will give you maximum flexibility during cluster instantiation to use the resources that are right for your infrastructure and requirements. For most infrastructure types (RHV UPI and non-integrated deployments being the exception), you still have the option of using features normally associated with IPI deployments day two and later. For example, the cloud provider and Machine API components are configured with UPI deployments, which means that you can use MachineSets to (auto)scale cluster compute nodes as needed.
If you would like to learn more about OpenShift load balancer options, capabilities, and limitations, we have talked about this topic on the Ask an OpenShift Admin live stream during episodes 60 (MetalLB L3/BGP), 49 (MetalLB L2), and 27 (day 2 ops). If you have questions, please join us each Wednesday at 11 a.m. Eastern Time on YouTube and Twitch to ask questions live, or reach out via social media: @practicalAndrew on Twitter and Reddit.
About the author
More like this
Reclaiming infrastructure autonomy: The 180-day mandate for virtualization service providers
Why Red Hat partners are the ultimate telco business asset
Crack the Cloud_Open | Command Line Heroes
Edge computing covered and diced | Technically Speaking
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds