By
The Five Pillars of Red Hat OpenShift Observability
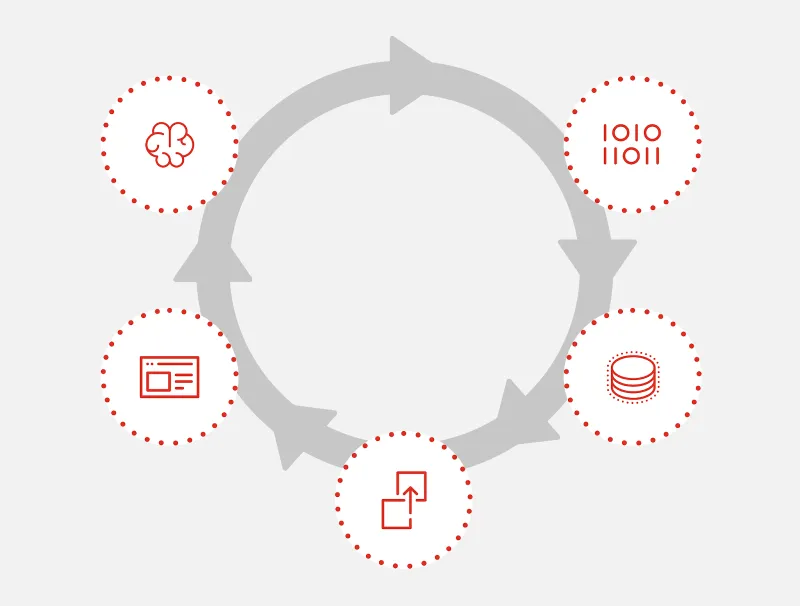
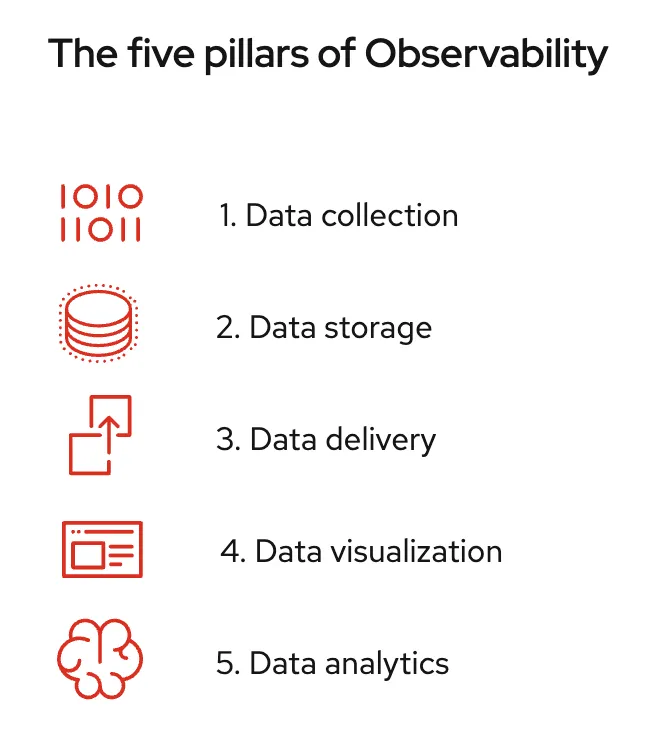
As stated in our previous blog, we aim to offer a consistent and simplified Observability experience for all environments, including cloud, on-premises, and edge. Our emphasis is on all five pillars of Red Hat OpenShift Observability: (i) Data Collection, (ii) Data Storage, (iii) Data Delivery, (iv) Data Visualization, and (v) Data Analytics. To achieve this vision, we have been working on providing more functionality with the releases of Red Hat OpenShift Monitoring 4.13, Logging 5.7, and Distributed Tracing 2.8.
What are the problems you can now solve with Red Hat OpenShift Observability?
Data Collection
Red Hat OpenShift 4.13 has introduced numerous enhancements that elevate the monitoring experience.This version introduces the ability for users to customize node-exporter collectors, including tcpstat, netclass, netdev, and cpufreq, with more to come in the next release. Furthermore, Red Hat OpenShift 4.13 enables the design of scrape profiles directly within the Cluster Monitoring Operator (CMO), simplifying the creation and management of scrape configurations. The integration of Vertical Pod Autoscaler (VPA) metrics also offers valuable insights into application resource usage, assisting in informed decision-making regarding scaling to meet workload demands.
With Red Hat OpenShift Logging 5.7, users can now forward logs to both Syslog and HTTP targets. Furthermore, multiline exception traces will now be transmitted as single log entries with Logging 5.7, allowing users to view trace logs as a unified event. These enhancements improve the flexibility and usability of Red Hat OpenShift Logging, enabling users to collect and view logs more efficiently.
Red Hat OpenShift Distributed Tracing 2.8 introduces a Tech Preview of the integration with Tempo as a backend for distributed traces. Tempo is open source, easy-to-use, highly scalable and able to process a high-volume of tracing signals. This cost-effective approach is achieved by not indexing the traces, which makes it possible to store orders of magnitude more of tracing data. Adoption is made easy for users due to its compatibility and integration with open source tools and protocols. Within the data collection perspective, another feature provided in this release as Tech Preview is the ability to gather traces from multiple Red Hat OpenShift clusters and forward them to a single Tempo instance.
Data Storage
Red Hat OpenShift 4.13 continues to enhance its monitoring capabilities with the addition of two notable features for the Alertmanager component. Users can now specify secrets within the Alertmanager component. Additionally, Red Hat OpenShift 4.13 introduces the Alertmanager proxy environment, providing an extra layer of flexibility when configuring and deploying Alertmanager instances.
Red Hat OpenShift Logging 5.7 now supports log-based alerts from the default Loki log store. This enhancement broadens the alerting capabilities for logs as an observability signal, allowing OpenShift Administrators to establish alerting rules based on logs. As a result, users can proactively identify and address issues before they cause significant problems, increasing the overall reliability and performance of their environments.
The Tech Preview of Tempo integration in Red Hat OpenShift Distributed Tracing 2.8 expands data storage capabilities. This enhancement aligns better with Logging (Loki) and Metrics (Prometheus), while also providing S3 compatible storage for traces, eliminating the need for a dedicated Elasticsearch instance. Additionally, multitenancy is made available, providing users with greater flexibility and control over their tracing data. These features improve the scalability and usability of Red Hat OpenShift Distributed Tracing, enabling users to store and access their tracing data more efficiently.
Data Delivery
The Cluster Monitoring Operator (CMO) is now available without the need for an ingress controller. This improvement simplifies the deployment process and removes the dependency on the ingress controller, offering more flexibility in diverse environments. In addition, the new node-related filters introduced provide users with the ability to narrow their monitoring scope by focusing on specific nodes. This feature enhances efficiency by allowing users to view the performance of specific nodes, providing a more targeted and streamlined approach to cluster monitoring.
With respect to data delivery, the Tech Preview of Tempo Integration coming in Red Hat OpenShift Distributed Tracing 2.8 provides similar data access mechanisms from an end-user perspective. This feature allows for a backend black box replacement, enhancing data delivery capabilities and providing users with greater control over their tracing data.
Data Visualization
The latest Red Hat OpenShift release focuses on improving user navigation within the OpenShift Web Console. The Metrics UI, in particular, provides an improved navigation experience when querying metrics. Users can enjoy the convenience of having new queries automatically rendered at the top of the queries list instead of the bottom, streamlining the navigation process and making it more efficient.
Furthermore, Red Hat OpenShift Web Console users can now configure the default log limit for front end requests in the Logs UI. This allows for more flexibility and easier adjustment of output expectations based on user needs. Along with this feature, they can benefit from plugin text translations. Additionally, OpenShift Web Console admins are now able to visualize log-based alerts through the Observe>Alerting UI, where they can access and filter Loki-based alerts. This valuable addition to the Red Hat OpenShift Web Console experience expands the range of data sources available for alerting, moving beyond just Prometheus-based alerts to include additional sources such as Logging Loki.
Red Hat OpenShift Distributed Tracing 2.8 will continue to offer the same Jaeger UI for visualizing data queried from both Tempo and Jaeger/Elasticsearch setups.
Data Analytics
Red Hat OpenShift 4.13 release brings a new feature that enables users to filter the data displayed in Monitoring Dashboards by node attributes. This added granularity provides users with more opportunities to investigate issues and gain deeper insights into their systems.
To aid in data analytics and the debugging of log results, OpenShift has added messages to troubleshoot errors for logQL queries. These messages might include links to Loki documentation, providing users with more resources to resolve any issues encountered.
What are we planning next for Observability?
Observability is a superpower! We are thrilled to share our ambitious long-term objectives, which involve all five pillars of OpenShift Observability: streamlined data collection with the Observability Operator, correlation across observability signals, a Distributed Tracing UI in the Red Hat OpenShift Web Console, aggregation of span data from traces to generate RED (Request, Error, Duration) metrics, and multicluster logging. These endeavors aim to deliver a consistent and straightforward Observability experience.
During the OpenShift Commons gathering in Amsterdam last month, which was held alongside KubeCon + CloudNativeCon, the OpenShift Roadmap Update session provided further insights into the long-term plans for OpenShift Observability. Watch it here!
Our Observability journey continues and we will share additional information in upcoming blog posts. Stay tuned and learn more here now.
About the authors

Roger Florén, a dynamic and forward-thinking leader, currently serves as the Principal Product Manager at Red Hat, specializing in Observability. His journey in the tech industry is marked by high performance and ambition, transitioning from a senior developer role to a principal product manager. With a strong foundation in technical skills, Roger is constantly driven by curiosity and innovation. At Red Hat, Roger leads the Observability platform team, working closely with in-cluster monitoring teams and contributing to the development of products like Prometheus, AlertManager, Thanos and Observatorium. His expertise extends to coaching, product strategy, interpersonal skills, technical design, IT strategy and agile project management.

Vanessa is a Senior Product Manager in the Observability group at Red Hat, focusing on both OpenShift Analytics and Observability UI. She is particularly interested in turning observability signals into answers. She loves to combine her passions: data and languages.

Jose is a Senior Product Manager at Red Hat OpenShift, with a focus on Observability and Sustainability. His work is deeply related to manage the OpenTelemetry, distributed tracing and power monitoring products in Red Hat OpenShift.
His expertise has been built from previous gigs as a Software Architect, Tech Lead and Product Owner in the telecommunications industry, all the way from the software programming trenches where agile ways of working, a sound CI platform, best testing practices with observability at the center have presented themselves as the main principles that drive every modern successful project.
With a heavy scientific background on physics and a PhD in Computational Materials Engineering, curiousity, openness and a pragmatic view are always expected. Beyond the boardroom, he is a C++ enthusiast and a creative force, contributing symphonic and electronic touches as a keyboardist in metal bands, when he is not playing videogames or lowering lap times at his simracing cockpit.

Jamie Parker is a Product Manager at Red Hat who specializes in Observability, particularly in the Logging and OpenStack areas. At Red Hat, Jamie works with organizations and customers to learn about their needs within the ever changing Observability landscape, and based on their feedback, helps to guide upcoming products within the Red Hat Observability Platform. Jamie enjoys sharing lessons learned to the community by frequently speaking at meetups and conferences, and by blogging.
More like this
Introducing OpenShift Service Mesh 3.2 with Istio’s ambient mode
Looking ahead to 2026: Red Hat’s view across the hybrid cloud
Crack the Cloud_Open | Command Line Heroes
Edge computing covered and diced | Technically Speaking
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds