
Accelerate your path to self-healing IT infrastructure
Overview
There has never been a more challenging time for running the services that power your organization—data moves at real-time speed, digital has become the rule, and customers expect secure, always-on services. Businesses need to contain cost and manage risk while coping with an ever changing technology estate. IDC illustrates the growing challenges for operations:
“By 2024, AIOps will become the new normal for IT operations, with at least 50% of large enterprises adopting AIOps solutions for automating major IT system and service management processes.”2
Distributed architectures continue to grow in size and complexity, challenging even the most capable organization’s ability to manage them effectively. Cloud technology adds another layer of complication in a world where systems are more interdependent than ever before and service levels are increasingly difficult to maintain in a cost effective manner. Secure and reliable operations are a minimum requirement for any organization that competes digitally.
In a world where any service disruption is amplified by social media, the cost in both brand equity and lost customers can be severe. With lost confidence, hard earned customers who expect secure, always-on, uninterrupted services will look for alternatives. Investors take a punishing view of service interruptions and failures as well, potentially moving their investments elsewhere.
The reality is that for many businesses, service disruptions are self-inflicted injuries that could be prevented with investments in service reliability. By taking advantage of modern technologies and practices—like DevSecOps—organizations can detect problems and remediate them automatically. This means services are more cost effective to operate and more reliable for your customers while having lasting benefits to your brand’s reputation.
“The average hourly cost of an infrastructure failure is $100,000 per hour, a survey of the Fortune 1000 by IDC finds. In addition, the average total cost of unplanned downtime per year is $1.25 billion to $2.5 billion. The financial impact may pale in comparison to the reputational risk and cost of lost customers, let alone potential regulatory sanction.”1
Why now?
The last 12 months have pushed the world into remote working and operations while servicing customers that are digital by default. These changes were already happening, but recent events have accelerated the transition. This new reality is here to stay.
Increased security threats
The growing sophistication of nefarious actors and increased reliance on digital to deliver services over the last 18 months poses a significant challenge. The worldwide information security market is forecast to reach US$170.4B in 2022,4 and data breaches alone exposed 36 billion records in the first half of 2020.5 As a result, 68% of business leaders feel their cybersecurity risks are increasing.6 Reliance on remote workforces exacerbated hacks in mobile and Internet of Things (IoT) devices. Even as the crisis passes, trends suggest that work from anywhere and work from home will continue to be the new way of working.
Technology is becoming more complex
For many, infrastructure and operations span both on-premise and off-premise datacenters across multiple generations of technology, from mainframes and distributed servers to cloud platforms to edge computing. A failure in one area will increasingly cascade across multiple services.
Not enough human talent
Talent shortage is a key concern for most organizations, and employment in computer and information technology occupations is projected to grow 11% from 2019 to 2029.7 However, demand continues to outstrip supply. The European Commission estimates a shortage of 756,000 skilled workers in these fields in just the next 18 months.8
What is self-healing infrastructure?
Early pioneers of running digital services at scale have championed the concept of self-healing infrastructure. By bringing together monitoring, streaming, intelligence and automation, organizations can respond more quickly to datacenter events, reducing operational toil and improving reliability without requiring human intervention. The self-healing aspect of this approach is the automation that is applied to an event, but automation is only part of the story.
Thanks to a convergence of new technologies from machine learning to data streaming, self-healing infrastructure is attainable for many organizations. It allows systems to automatically sense and respond to a wide range of events, and to identify and self-correct operational issues; thereby keeping services secure and available while delivering superior service to customers.
“Data breaches alone exposed 36 billion records in the first half of 2020. The average cost of a data breach is $3.86 million as of 2020, according to IBM, the average time to identify a breach in 2020 was 207 days, and the average life- cycle of a breach was 280 days from identification to containment.”3
Self-healing infrastructure is a response to the need to remediate the operational challenges today’s organizations face in a cost effective way. It helps meet both customer and regulatory expectations for business-critical services while mitigating cost.
Fully functioning self-healing infrastructure introduces the practical application of AIOps, which brings together a range of intelligent technologies from across the enterprise, including AI, machine learning, and infrastructure automation to provide end-to-end coverage. The real power of these technologies comes when they are paired with real-time data that can autonomously execute immediate insight-driven actions.
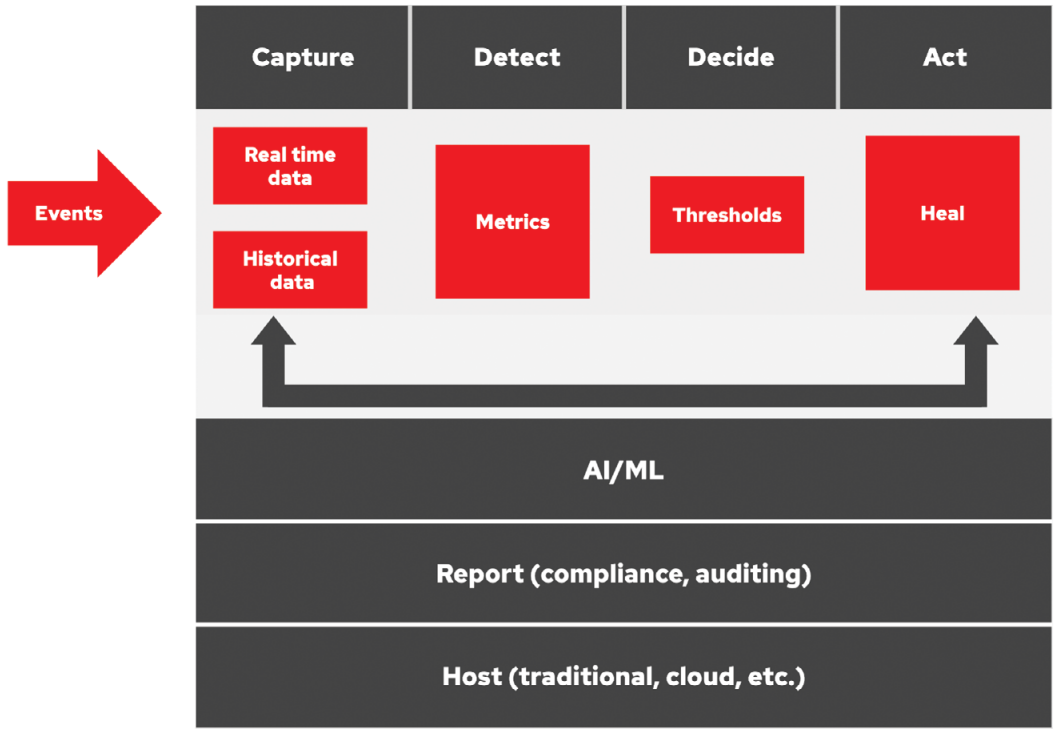
- Events: Today’s technologies support real-time data streaming, allowing all datacenter events to be processed in real time. Information is sourced from infrastructure, network, application, and other sensors across the datacenter.
- Capture: Both real time and historical information is collected, such as changes in the state of machines or systems and applications, as well as changes in customer interactions.
- Detect: Anomaly detection correlates and traces problems to their source using the environment's topology. Artificial intelligence and machine learning (AI/ML) models detect issues before they create problems.
- Decide: Automatic responses to alerts for anomalies or threshold breaches as designated by service managers. Exception handling based on predefined rules and processes.
- Act: These events can be acted on automatically using remediation playbooks that go across all datacenter assets.
“In 2022, enterprises focused on digital resiliency will adapt to disruption and extend services to respond to new conditions 50% faster than ones fixated on restoring existing business/IT resiliency levels.“9
Ultimately, the goal of self-healing infrastructure to remove the operational burden of running systems. To accomplish this, organizations need a highly intelligent and highly automated platform that can cope with multiple generations of technologies across a range of deployment scenarios. Red Hat® OpenShift® is a leader in Kubernetes and other communities shaping the future of cloud technology. It gives you the ability to run anywhere (on-premises, off-premise, or a combination of both.) You also get access to Red Hat Integration to connect and automate almost any element within the datacenter. Red Hat Ansible® Automation Platform provides built-in playbooks for everything from servers to storage to networking and security.
Evolving from DevOps to AIOps
To ensure the continuous automation, security, iterations, and innovations that make self-healing infrastructure possible, teams need to work closely together. The DevOps process ensures high levels of collaboration and automation. Similarly, AIOps leverages artificial intelligence and machine learning to manage infrastructures. Self-healing infrastructure offers the possibility of significantly improving performance and uptime, and achieving the goal of AIOps where automation and AI handle the majority of operations.
Organizations will need to develop high-level plans for their automation efforts and the technologies needed to support them. These plans will guide investments through the lens of the automation strategy, ensuring that automation supports the needs of its organization.
Benefits of self-healing infrastructure
Adding self-healing capabilities to the organization’s existing infrastructure can have immediate and tangible benefits. Early adopters have improved the operational performance of their existing distributed systems and have applied many of the principles to their cloud environments as well.
Reducing the cost of running systems
As distributed systems become more numerous and complex it is no longer cost effective to manage them the same way as organizations did in the past. Employee turnover has made it difficult to retain operational knowledge and alert fatigue reduces the time and attention available for running these critical systems. Organizations minimize direct costs by applying self-healing practices to their infrastructure. Consider a recent financial services customer that receives approximately 1000 infrastructure service tickets per day, which can cost up to $50 per ticket to manually resolve. It is expected that 30% of these requests can be eliminated through self-healing infrastructure and save the organization millions of dollars.
Securing systems more effectively
Security threats targeting enterprises are overwhelming their capacity to keep systems secure. An expanding array of systems has reduced the ability of operational staff to appropriately respond to security issues that affect systems. Organizations can reduce their risk exposure and staff burden by investing in self-healing infrastructure.
Easing the burden of meeting compliance obligations
In regulated industries such as financial services or healthcare, regulators require traceability into actions across the datacenter. Organizations can reduce this burden by employing predefined playbooks and reports to meet International Organization for Standardization (ISO) and security operations center (SOC) obligations.
Improving service reliability
Customers are increasingly impacted by service issues. Swiftly resolving these issues by reducing the mean time to recovery can reduce their overall impact. Detecting an infrastructure issue and self-correcting not only saves on infrastructure costs, it also makes operations more reliable.
Learn more
Red Hat has helped enterprises across the globe meet their most pressing infrastructure and operations challenges. We have helped customers drastically reduce the running cost of their existing infrastructure while improving resiliency and security.
To deliver the full benefits of automated self-correction, a self-healing infrastructure needs an architecture that lets operational teams maximize the value of its data. An open architecture can provide the flexibility to add new AI models and evolve the system to meet new operational requirements over time.
Reach out to your Red Hat representative or talk to a Red Hatter today to learn more about how Red Hat can help you enhance your automation strategy and roadmap so that your organization can enjoy the benefits of self-healing infrastructure.
“Cost of a Data Breach Report 2020.” IBM Security. Accessed Mar. 2021.
Gartner research, Forecast Analysis: Information Security, Worldwide, 2Q18 Update, Sept. 2018
Risk Based Security. “New Research: Number of Records Exposed Reaches Staggering 36 Billion.” Risk Based Security Q3 Report, Oct. 2020.
Accenture Security. The Cost of Cybercrime, 2019.
U.S. Bureau of Labor Statistics. Occupational Outlook Handbook: Computer and Information Technology Occupations, Apr. 2021.
Kurkal, Vijay. “2020 Business Trends: AIOps and the Promise of Self-healing IT.” DevPro Journal, November 14, 2019
IDC FutureScape Doc #US46942020, Oct. 2020.
Consider a recent financial services customer that receives approximately 1000 infrastruc- ture service tickets per day, which can cost up to $50 per ticket to manually resolve. It is expected that 30% of these requests can be eliminated through self-healing infrastruc- ture and save the organization millions of dollars.