
Red Hat OpenShift Virtualization 4.19 は、データベースなどの、I/O を多用するワークロードのパフォーマンスとスピードを大幅に向上させます。Red Hat OpenShift Virtualization の複数 IO スレッドは、仮想マシン (VM) のディスク I/O をホスト上の複数のワーカースレッドに分散できるようにする新機能です。これらのワーカースレッドは VM 内のディスクキューにマッピングされます。これにより、VM は vCPU とホスト CPU の両方をマルチストリーム I/O に効率的に使用できるため、パフォーマンスが向上します。
この記事は、同僚の Jenifer Abrams が執筆した機能紹介の手引としてご利用いただけます。補足ですが、I/O スループットを向上させるために VM をチューニングする際に役立つパフォーマンス結果をご紹介したいと思います。
また、テストには、Linux VM で合成 I/O ワークロードとして fio を使用しています。各種のアプリケーションを使用したテストや Microsoft Windows 上でのテストも進めています。
この機能を KVM に実装する方法の詳細については、IOThread Virtqueue Mapping に関する記事と、Red Hat Enterprise Linux (RHEL) 環境で実行される VM におけるデータベースワークロードのパフォーマンスの向上を実証している関連記事をご覧ください。
テストの説明
次の 2 つの構成で I/O スループットをテストしました。
- Local Storage Operator (LSO) によってプロビジョニングされた論理ボリュームマネージャーを使用する、ローカルストレージを持つクラスタ
- OpenShift Data Foundation (ODF) を使用する別のクラスタ
それぞれの構成は大幅に異なっているため、この比較は割愛します。
テストは Pod (ベースライン用) と VM で行いました。VM には、16 コアと 8 GB RAM を割り当てました。1 つの VM で 512 GB、2 つの VM で 256 GB のテストファイルを使用しました。すべてのテストでダイレクト I/O を使用しました。VM にはブロックモードで、ext4 としてフォーマットされた永続ボリューム要求 (PVC) を使用しました。また、Pod 用にも ext4 としてフォーマットされたファイルシステムモードの PVC を使用しました。すべてのテストは、libaio I/O エンジンを使用して実行されました。
次のマトリックスを検証しました。
パラメーター | 設定 |
ストレージボリュームのタイプ | ローカル (LSO)、ODF |
Pod/VM の数 | 1、2 |
I/O スレッドの数 (VM のみ) | なし (ベースライン)、1、2、3、4、6、8、12、16 |
I/O 操作 | シーケンシャルおよびランダムな読み書き |
I/O ブロックサイズ (バイト) | 2K、4K、32K、1M |
並行ジョブ | 1、4、16 |
I/O iodepth (iodepth) | 1、4、16 |
テストのオーケストレーションには ClusterBuster を使用しました。VM には CentOS Stream 9 を使用し、Pod にも同様に CentOS Stream をコンテナイメージベースとして使用しました。
ローカルストレージ
ローカル・ストレージ・クラスタは、2 つの Intel Xeon Gold 6130 CPU を含む Dell R740xd ノードで構成される 5 ノード (3 つのマスター + 2 つのワーカー) のクラスタで、それぞれが 16 コアと 2 スレッド (32 CPU) を備えているため、合計 32 コアと 64 CPU になります。各ノードには 192 GB の RAM があります。I/O サブシステムは、デフォルト設定で RAID0 ストライピングの複数デバイス (MD) として構成された、4 つの Dell 製 Kioxia CM6 MU 1.6 TB NVMe ドライブで構成されています。永続ボリューム要求は、lvmcluster Operator を使用して、この MD から切り分けました。この構成はかなり控えめなものですが、より高速な I/O システムなら、複数 I/O スレッドでさらなる改善が得られると考えられます。
OpenShift Data Foundation
OpenShift Data Foundation (ODF) クラスタは、Dell PowerEdge R7625 ノードで構成される 6 ノード (3 マスター + 3 ワーカー) のクラスタで、2 つの AMD EPYC 9534 CPU を含み、それぞれが 64 コアおよび 2 スレッド (128 CPU) で合計 128 コアおよび 256 CPU を備えています。各ノードには 512 GB の RAM があります。I/O サブシステムは、ノードあたり 2 台の 5.8 TB NVMe ドライブで構成され、25 GbE のデフォルト Pod ネットワーク上で 3 方向レプリケーションに対応します。今回のテストではさらに高速なネットワークを利用できませんでしたが、新しいネットワーク・ハードウェアの場合はさらに良い結果が得られた可能性があります。
結果のまとめ
今回のテストでは、特定の I/O バックエンドで複数の I/O スレッドを評価しました。これは実際のユースケースとは異なる場合もあります。ストレージの特性の違いは、I/O スレッド数の選択に大きな影響を与える可能性があります。
今回のテストで明らかになった点は以下のとおりです。
- 最大 I/O スループット:ローカルストレージの最大スループットは、Pod と VM の両方で、読み取りが約 7.3 GB/秒、書き込みが 6.7 GB/秒でした。iodepth やローカルストレージ上のジョブ数による影響がありませんでした。これは、ハードウェアから予想される数よりも大幅に少ないと言えます。デバイス (それぞれ 4x PCIe gen4) の定格速度は、読み取りが 6.9 GB/秒、書き込みが 4.2 GB/秒です。この差の原因については調査していませんが、ハードウェアが旧式であることが原因である可能性も考えられます。最大パフォーマンスは、単一ドライブのパフォーマンスよりも明らかに優れており、ストライピングの効果があったことを示しています。ODF の場合、最高の結果は読み取り 5 GB/秒、書き込み 2 GB/秒でした。
- 大きなブロック I/O (1 MB) では、システムによってパフォーマンスが制限されていたため、ほとんど改善は見られませんでした。
- I/O スレッドの数の最適な選択は、ワークロードとストレージの特性によって異なります。予想通り、I/O の同時実行性が顕著ではないワークロードではほとんど効果が認められませんでした。
- ローカルストレージ:I/O の同時実行性が高い VM の場合、一般的には 4 - 8 から始めるのがよいでしょう。とくに I/O サイズが小さく、同時実行性が高いワークロードの場合は、スレッドを増やすとより多くの効果が得られます。
- ODF:複数の I/O スレッドが大きな効果をもたらすことはめったになく、多くの場合、これらは全く必要ありませんでした。これは、Pod ネットワークが比較的遅いことが原因である可能性があります。つまり、ネットワーク速度が改善すれば、結果が異なる可能性があります。
- 少なくとも今回のテストについては、複数の I/O スレッドがより効果を発揮したのは、深度が高い非同期 I/O よりも複数の並行ジョブの方でした。
- 基礎となる総計最大 I/O スループット (上記) に達するまで、並行 VM が 1 台と 2 台では動作に違いはありませんでした。
- 複数の I/O スレッドについては、ジョブ数や I/O iodepth が低い Pod とのギャップが完全になくなることはありませんでした。操作規模が小さく、I/O iodepth が高い場合、VM は実際には、書き込み操作で Pod を大幅に上回りました。
数字で見る
ここでは、ローカルストレージベースのシステムで複数の I/O スレッドを使用した場合の全体的な I/O スループットを示しています。ご覧のように、I/O サイズが小さく、高速 I/O システムとの多数の並列処理を伴うワークロードでは、大きな効果が得られます。ここでは、異なる数の I/O スレッドに関して得られた効果についてさらに紹介します。ブロックサイズが 1 MB の場合、わずかな改善しか見られませんでした。これは、パフォーマンスが基盤となるシステムの限度に非常に近かったためです。さらに高速なハードウェアを使用すると、追加の I/O スレッドは大きなブロックサイズでも改善される可能性があります。
VM ベースラインに対して、I/O スレッドを追加した場合の改善結果 | ||||||||||
(ローカルストレージ) | ジョブ | iodepth | ||||||||
1 | 4 | 16 | ||||||||
サイズ | 操作 | 1 | 4 | 16 | 1 | 4 | 16 | 1 | 4 | 16 |
2048 | randread | 18% | 31% | 30% | 30% | 103% | 192% | 151% | 432% | 494% |
randwrite | 81% | 59% | 24% | 153% | 199% | 187% | 458% | 433% | 353% | |
read | 67% | 58% | 25% | 64% | 71% | 103% | 252% | 241% | 287% | |
write | 103% | 64% | 0% | 143% | 99% | 84% | 410% | 250% | 203% | |
計 2048 | 67% | 53% | 20% | 97% | 118% | 141% | 318% | 339% | 334% | |
4096 | randread | 18% | 34% | 28% | 33% | 101% | 208% | 156% | 432% | 492% |
randwrite | 95% | 69% | 20% | 149% | 200% | 187% | 471% | 543% | 481% | |
read | 26% | 53% | 27% | 24% | 46% | 66% | 142% | 155% | 165% | |
write | 103% | 69% | 0% | 144% | 86% | 48% | 438% | 256% | 161% | |
計 4096 | 60% | 56% | 19% | 87% | 108% | 127% | 302% | 346% | 325% | |
32768 | randread | 16% | 23% | 26% | 23% | 71% | 124% | 99% | 160% | 129% |
randwrite | 75% | 71% | 28% | 108% | 132% | 116% | 203% | 123% | 115% | |
read | 21% | 57% | 25% | 21% | 42% | 32% | 77% | 54% | 32% | |
write | 79% | 64% | 26% | 104% | 59% | 24% | 195% | 45% | 27% | |
計 32768 | 48% | 53% | 26% | 64% | 76% | 74% | 143% | 96% | 76% | |
1048576 | randread | 5% | 2% | 0% | 9% | 0% | 0% | 17% | 0% | 0% |
randwrite | 10% | 0% | 1% | 6% | 0% | 2% | 9% | 0% | 2% | |
read | 12% | 18% | 0% | 9% | 0% | 0% | 16% | 0% | 0% | |
write | 19% | 0% | 0% | 7% | 0% | 0% | 9% | 0% | 0% | |
計 1048576 | 11% | 5% | 0% | 8% | 0% | 1% | 13% | 0% | 0% | |
以下は、最大 16 の I/O スレッドで達成可能な最良の結果のうち、90% を達成するために必要な I/O スレッドの数です。たとえば、今回のテストにおいて、操作、ブロックサイズ、ジョブ、iodepth の特定の組み合わせで得られた最良の結果が 1 GB/秒であった場合、このメトリクスは 900 MB/秒を達成するために必要な最小スレッドとなります。これにより、スレッド数を控えめに設定しても、良好なパフォーマンスを達成できます。
最良パフォーマンスの 90% を達成するための最小 iothread 数 | ||||||||||
(ローカルストレージ) | ジョブ | iodepth | ||||||||
1 | 4 | 16 | ||||||||
サイズ | 操作 | 1 | 4 | 16 | 1 | 4 | 16 | 1 | 4 | 16 |
2048 | randread | 1 | 1 | 1 | 1 | 4 | 8 | 3 | 12 | 12 |
randwrite | 1 | 1 | 1 | 3 | 16 | 12 | 8 | 12 | 12 | |
read | 1 | 1 | 1 | 1 | 4 | 4 | 4 | 6 | 8 | |
write | 1 | 1 | 0 | 2 | 12 | 6 | 8 | 6 | 6 | |
計 2048 | 1 | 1 | 1 | 2 | 9 | 8 | 6 | 9 | 10 | |
4096 | randread | 1 | 1 | 1 | 1 | 4 | 8 | 3 | 12 | 12 |
randwrite | 1 | 1 | 1 | 3 | 16 | 12 | 8 | 12 | 12 | |
read | 1 | 1 | 1 | 1 | 2 | 3 | 3 | 6 | 8 | |
write | 1 | 1 | 0 | 3 | 12 | 4 | 8 | 6 | 4 | |
計 4096 | 1 | 1 | 1 | 2 | 9 | 7 | 6 | 9 | 9 | |
32768 | randread | 1 | 1 | 1 | 1 | 3 | 6 | 2 | 4 | 3 |
randwrite | 1 | 1 | 1 | 2 | 12 | 6 | 4 | 3 | 3 | |
read | 1 | 1 | 1 | 1 | 2 | 2 | 2 | 2 | 2 | |
write | 1 | 1 | 1 | 2 | 6 | 2 | 4 | 2 | 1 | |
計 32768 | 1 | 1 | 1 | 2 | 6 | 4 | 3 | 3 | 2 | |
1048576 | randread | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
randwrite | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
read | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | |
write | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
計 1048576 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | |
結果の詳細
測定したテストケースごとに、次の性能指標を算出しました。
- I/O スループットの測定
- 最良の VM パフォーマンス (詳細は割愛)
- 最良の VM パフォーマンスの 90% を達成するための最小 iothread 数
- 最良の VM パフォーマンスと Pod パフォーマンスの比率
- ベースライン VM パフォーマンスに対する、VM パフォーマンスの改善
最良のパフォーマンスを発揮するスレッドの数は報告していませんが、それは、数の違いによる差は非常に小さく、I/O パフォーマンスの報告における通常の差異よりも小さいためです。
ローカルストレージと ODF は特性が大きく異なるため、その結果は個別にまとめています。
以下のパフォーマンスグラフはすべて、Pod (pod)、I/O スレッドを持たないベースライン VM (0) の結果を示しており、X 軸に I/O スレッドの特定の数を示しています。
ローカルストレージ
パフォーマンスのデータそのものを見てみると、少なくとも場合によっては、複数の I/O スレッドを使用することで大きな効果が得られることがわかります。たとえば、16 ジョブの非同期 I/O で iodepth 1 を指定した場合、ローカルストレージで追加の I/O スレッドを使用すると、次のように桁違いの効果が得られます。
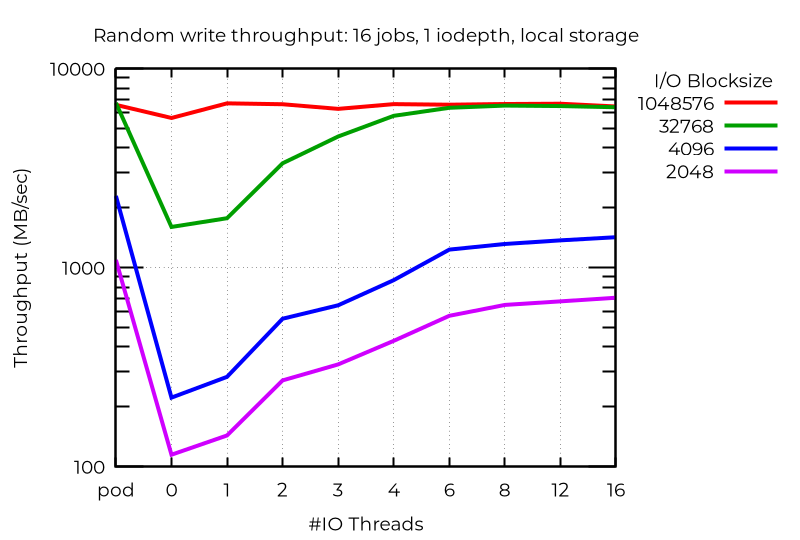
ストリーム I/O が 1 つであっても、追加の I/O スレッドを 1 つ使用することで効果は得られます。ただし、これを複数に増やしても違いはありません。

追加の I/O スレッドが実際にはパフォーマンスを低下させるという、特殊な例もあります。この場合、小さなブロックで深度の高い非同期 I/O を使用すると、専用の I/O スレッドを使用しない VM で最高のパフォーマンス (Pod よりも優れたパフォーマンス) を達成できます。これが発生する理由は解明されていません。
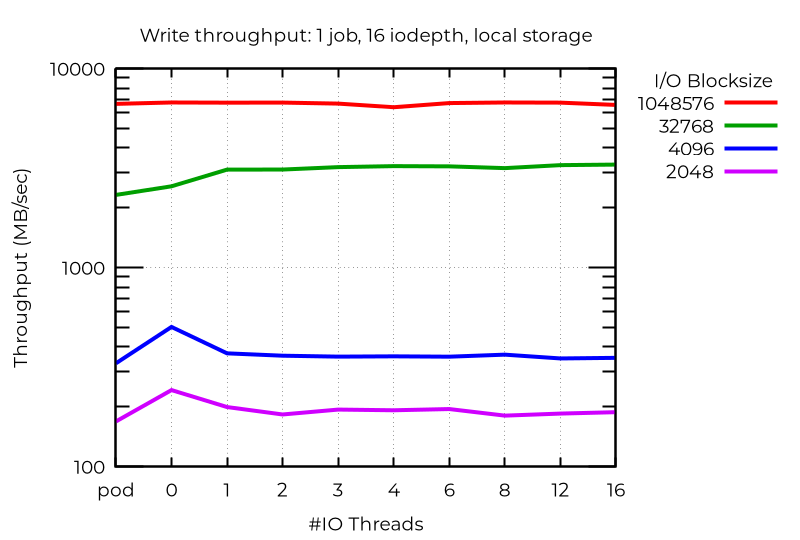
これらはすべて、複数の I/O スレッドから最適なパフォーマンスを得るには、特定のワークロードで実験する必要があることを示しています。
ODF クラスタの結果
ローカルストレージでは、小規模ブロックのランダム書き込みで複数の I/O スレッドによる大幅な改善が見られましたが、ODF では、ジョブ数が多くても改善効果は限定的でした。ネットワークをより高速に、またはレイテンシーを抑えることで、より大きな効果が得られる可能性があります。読み取り操作、とくにランダム読み取りにはある程度の効果が見られましたが、書き込みやジョブ数の減少させて場合に関しては、ほとんど効果が確認されませんでした。
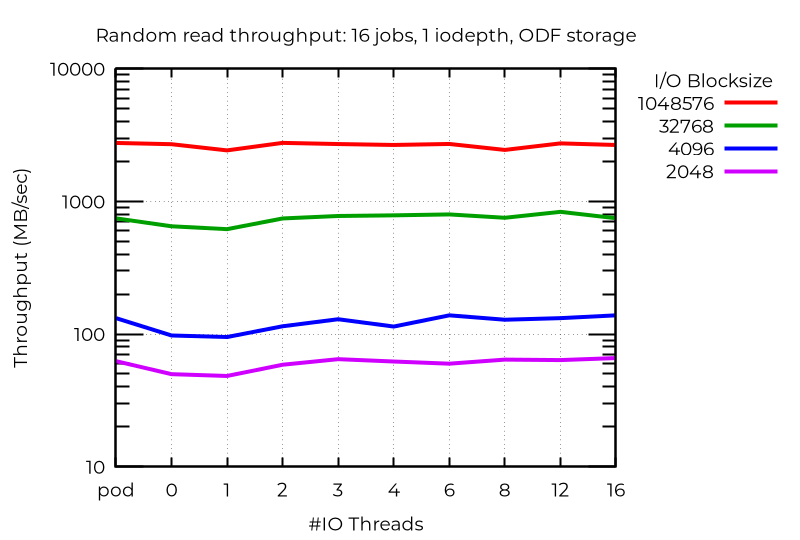
まとめ
OpenShift Virtualization の複数 I/O スレッドは、OpenShift 4.19 の画期的な新機能です。とくに今回のテストで使用したローカル NVMe ストレージのような高速 I/O システムでは、並列 I/O を使用するワークロードの I/O パフォーマンスを大幅に高める可能性があります。基盤となるベアメタル I/O を完全に駆動するためにはより多くの CPU が必要になるため、複数 I/O スレッドによる効果が最も大きくなるのは、高速な I/O サブシステムです。I/O の場合は常に言えることですが、I/O システムや全体的なワークロードの違いはパフォーマンスに大きな影響を与えかねません。この新機能を最大限に活かすには、実際のワークロードでテストを行うことをお勧めします。今回のテスト結果が、I/O スレッドについて最適な選択をする上で参考になれば幸いです。
製品トライアル
Red Hat OpenShift Virtualization Engine | 製品トライアル
執筆者紹介
チャンネル別に見る

自動化
テクノロジー、チームおよび環境に関する IT 自動化の最新情報

AI (人工知能)
お客様が AI ワークロードをどこでも自由に実行することを可能にするプラットフォームについてのアップデート

オープン・ハイブリッドクラウド
ハイブリッドクラウドで柔軟に未来を築く方法をご確認ください。

セキュリティ
環境やテクノロジー全体に及ぶリスクを軽減する方法に関する最新情報

エッジコンピューティング
エッジでの運用を単純化するプラットフォームのアップデート

インフラストラクチャ
世界有数のエンタープライズ向け Linux プラットフォームの最新情報

アプリケーション
アプリケーションの最も困難な課題に対する Red Hat ソリューションの詳細
仮想化
オンプレミスまたは複数クラウドでのワークロードに対応するエンタープライズ仮想化の将来についてご覧ください