Developing software as efficiently and swiftly as possible is a competitive necessity. The faster and sooner you can get new products to market, the greater advantage you have with your customers. In recent years, AI coding has become a compelling way to help solve these challenges by handling tedious, repetitive tasks and debugging and testing more quickly. This frees up valuable time for higher-impact development work.
However, the rapid adoption of generative AI-powered coding has introduced new enterprise-level challenges. As organizations scale their use of AI tools, they confront critical questions: How can we be sure of long-term cost efficiency? How do we protect intellectual property and sensitive data within and around the codebase? And how can we meet our data and regulatory compliance mandates?
Most organizations begin their AI journey with hosted model services, which is often a great starting point. But as usage increases, the reliance on hosted third-party endpoints, which charge based on quantity of tokens, can lead to unpredictable, high operational costs. Additionally, you have minimal control over the infrastructure, security and governance of the overall stack. This lack of control poses challenges for enterprise organizations, often forcing them to create exceptions to long-standing and well-justified policies. NVIDIA and Red Hat are collaborating to help you overcome these challenges with platforms such as Red Hat AI Factory with NVIDIA, letting you run high‑performance inference and tuning on your own hybrid cloud infrastructure while keeping security, access policies, and GPU usage under enterprise control.
Models-as-a-Service: Enterprise AI on your terms
Addressing these challenges is also where Models-as-a-Service (MaaS) on Red Hat AI comes in.
MaaS is a fully-integrated feature within Red Hat AI that fundamentally shifts how enterprises manage AI. It allows your centralized IT teams to host and manage their own models on their own multi-tenant infrastructure, entirely on your organization’s terms. These models are then made available to support multiple internal use cases and teams via controlled API token access.
This approach of having your own private hosted model service offers you an unprecedented level of governance and control. Administrators can define and set user tiers and prescribe specific usage constraints for each team or project, which helps make sure each internal consumer has the resources they need, and prevents unnecessary overuse with expensive resources sitting idle. This simplifies model access, manages consumption, and allows the central IT teams to monitor metrics, forecast capacity and compute requirements, and perform chargebacks with a high degree of control and predictability.
Launch your own private AI code assistant today with our new AI quickstart
Seeing the need for a practical, secure, and cost-controlled path to AI coding, we’ve added a new: "Accelerate enterprise software development with NVIDIA and MaaS" AI quickstart to our AI quickstarts catalog. This AI quickstart is a ready-to-run deployment designed to get you started on Red Hat AI with a simple, immediately useful solution.
This AI quickstart is a simple, repeatable path to deploying your own private AI code assistant, leveraging the power of NVIDIA Nemotron open models and NVIDIA accelerated computing within Red Hat AI.
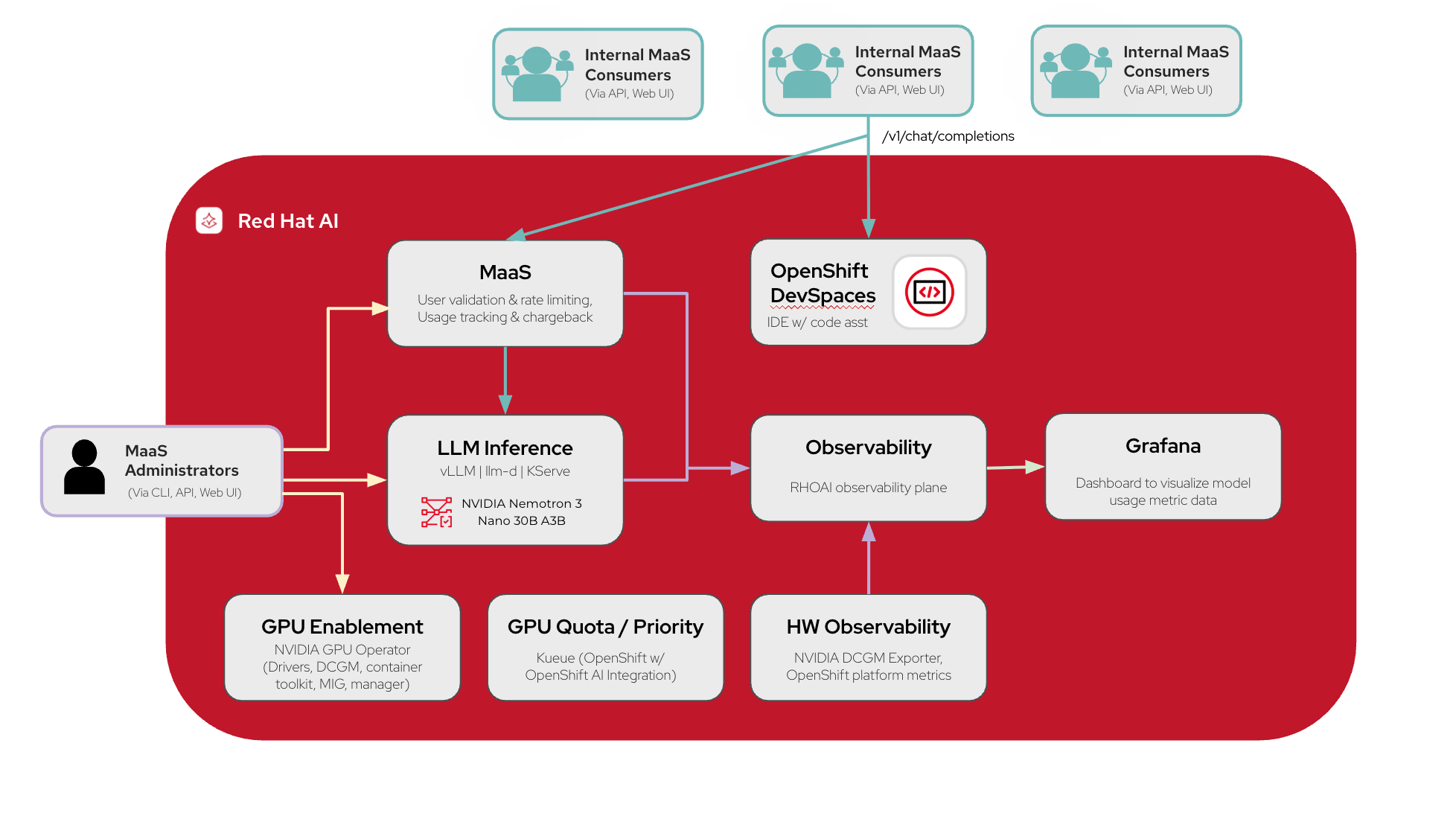
What’s in the AI quickstart?
The AI quickstart provides all the necessary components for a high-performance, secure AI code assistant:
The platform: Red Hat AI, with the foundation of Red Hat OpenShift, provides the orchestration layer for all of your models and AI workloads.
Inference: vLLM and llm-d with KServe offer the distributed inference performance you require when running models at scale to enable the best possible performance and optimal resource utilization.
Large language model (LLM): The AI quickstart uses leading LLMs including the NVIDIA Nemotron 3 Nano 30B A3B model. This is a model quantized to FP8 precision, designed for efficient reasoning, chat, and agentic AI apps.
Models-as-a-Service: Fully integrated into the Red Hat AI dashboard, providing an API gateway for usage tracking, governance, and the necessary data for simple chargeback across teams.
Red Hat OpenShift Dev Spaces: OpenShift Dev Spaces gives your teams cloud-native IDE instances to develop and deploy, all in the same cluster.
Note: OpenShift Dev Spaces is included in OpenShift subscriptions.
Observability: Via the Prometheus operator in OpenShift, you get the inference metrics and GPU telemetry you need to understand model usage and performance across teams.
GPU acceleration: This AI quickstart runs on NVIDIA AI infrastructure which are enabled by the NVIDIA GPU Operator, supported by NVIDIA through the NVIDIA AI Enterprise subscription. This operator enables the GPUs, manages necessary drivers, NVIDIA Data Center GPU Manager (DCGM), container toolkit, and MIG capabilities for partitioning supported accelerators.
Key benefits
The code assistant AI quickstart provides 3 primary business benefits:
1. Predictable cost and budget control
By running your own infrastructure, you’re in control with built-in features for implementing usage rate limits and quotas and monitoring consumption in detail. It makes budget tracking simple and scaling costs easier to forecast.
2. Built in security and compliance
For organizations with strict governance requirements, security is something you cannot compromise on. The AI quickstart gives you an example of an on-premise or private cloud deployment that keeps your code within your organizational boundaries. Since you have the model hosted internally on infrastructure you manage, you’re not dealing with external API calls or data leakage concerns.
3. Top-tier developer experience
We’re providing the foundation of a high-performance environment that your developers need to work more quickly and efficiently. The platform’s high-speed inference, powered by NVIDIA GPUs and our vLLM and llm-d inference stack, provides fast inference at enterprise scale. This performance is then integrated with an OpenShift Dev Spaces environment, allowing your developers to work together in the same cluster, improving productivity.
Get started now
Ready to put Models-as-a-Service and NVIDIA models to work with your AI coding?
- Check out the accelerate enterprise software development with NVIDIA and MaaS AI quickstart:
- This AI quickstart links to our GitHub repository with the complete deployment code.
- Review the hardware and software requirements
- Reach out via a GitHub issue or your Red Hat team for any questions or guidance on using the AI quickstart
Additional resources
- Check out the AI quickstarts catalog
- Learn more about NVIDIA Nemotron
- Explore the benefits of the Red Hat AI Factory with NVIDIA
製品
Red Hat AI
執筆者紹介

Taylor specializes in helping global enterprises transition Generative AI from experimental pilots to production-scale deployments. A specialist in large-scale inference and agentic systems, Taylor bridges the gap between complex infrastructure and practical application development. She is a dedicated advocate for open-source ecosystems, leveraging projects such as vLLM, llm-d and MLflow to build sovereign, secure, and observable AI stacks. Her work is centered on empowering organizations to reclaim control over their AI lifecycle through transparent and scalable open-source solutions.
チャンネル別に見る

自動化
テクノロジー、チームおよび環境に関する IT 自動化の最新情報

AI (人工知能)
お客様が AI ワークロードをどこでも自由に実行することを可能にするプラットフォームについてのアップデート

オープン・ハイブリッドクラウド
ハイブリッドクラウドで柔軟に未来を築く方法をご確認ください。

セキュリティ
環境やテクノロジー全体に及ぶリスクを軽減する方法に関する最新情報

エッジコンピューティング
エッジでの運用を単純化するプラットフォームのアップデート

インフラストラクチャ
世界有数のエンタープライズ向け Linux プラットフォームの最新情報

アプリケーション
アプリケーションの最も困難な課題に対する Red Hat ソリューションの詳細
仮想化
オンプレミスまたは複数クラウドでのワークロードに対応するエンタープライズ仮想化の将来についてご覧ください