


In large, complex systems, replicating configurations between environments or sites is a good way to improve standardization and efficiency. Treating your configs as a form of code allows you to track bugs, fixes, and deployments. This approach is generally referred to as Configuration as Code (CaC or CasC).
Our previous article explained how to use Ansible Automation Platform automation controller to support CaC with a GitOps approach. CaC usually uses an API to configure an application or software, so the Ansible modules are not directly connected to the host you want to configure. Instead, it's done locally, and the module makes a call to the host serving that API.
[ Learn best practices for implementing automation across your organization. Download The automation architect's handbook. ]
Automation in multisite active/passive architectures
In a multisite active/passive architecture, where your (active) application stack is replicated in a different (passive) datacenter for failover and disaster recovery, you must consider where the automation executes. Whether a site is active or passive could change a controller object's behavior through variables.
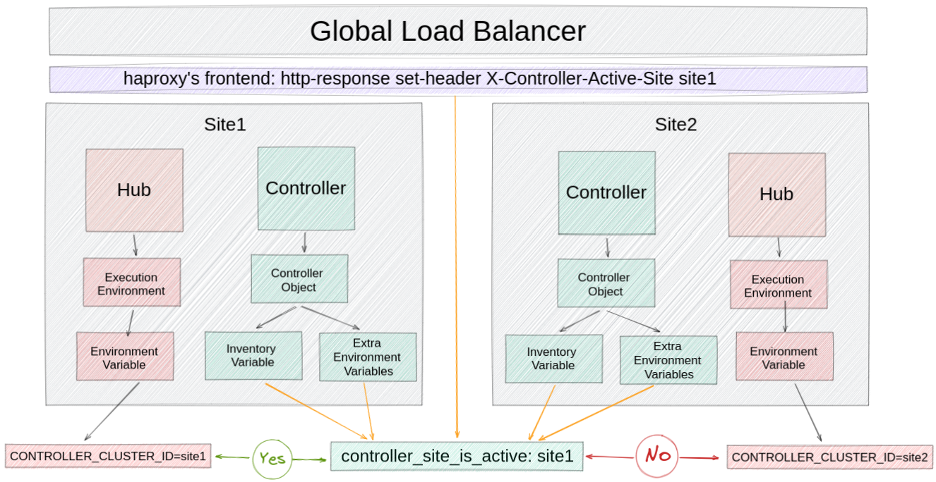
You can use an environment variable in the execution environment to determine where the execution occurs. Because you're working with containers, the variable is immutable, so you can anchor it to the site from where execution happens.
A variable that determines which site is active can be obtained from controller objects or load balancer headers.
Get variables from controller objects
In this scenario, the variable is retrieved from the Git repository in the super-admin organization, so a team with superpowers controls which site is active. This variable can be added to these objects:
- Inventory: You could add the variable in the Inventory, and permissions can be given to the organizations consuming the CaC.
- Settings: You can add the variable as an extra var of the jobs in the settings, making it global and usable by all organizations.
Get variables from the load balancer header
Alternatively, you could add the value of the variable as a header in the load balancer configuration. This approach reduces the risk of a single point of failure and the number of steps required for maintenance or disaster recovery.
- Redirect requests to switch sites.
- Add the value of the active site to the header. The value is retrieved from the corresponding flow playbooks, which changes the behavior of the controller's objects.
[ Also read: Set up GitLab CI and GitLab Runner to configure Ansible automation controller. ]
Automatic triggering in a multisite active/passive architecture
In an active/passive architecture, automation execution must be carried out only from one site. There are exceptions.
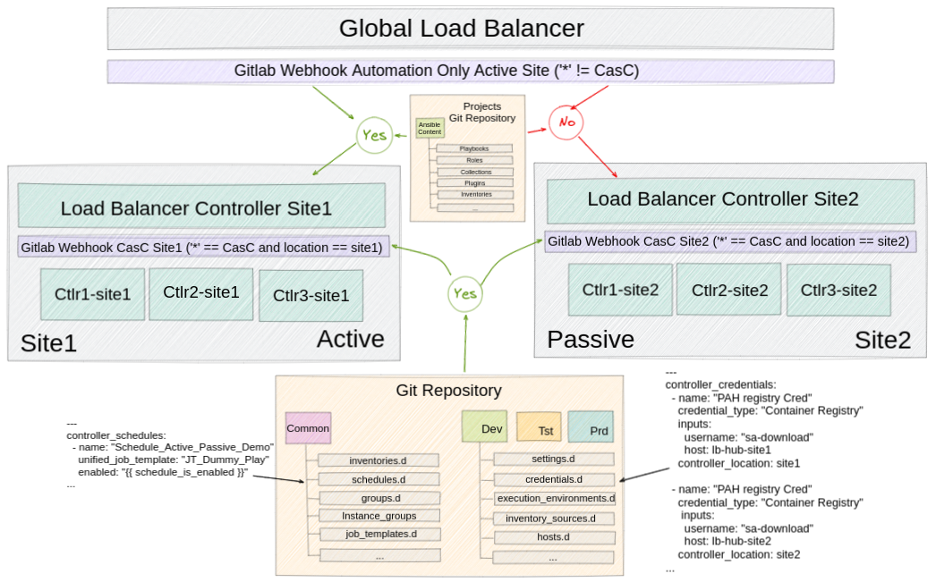
You might consider two approaches for an active/passive scenario: CaC automation or an automation-only active site.
CaC automation
Automation must be executed in both sites in this scenario, so this is really an active/active scenario. The main function here is to replicate the configuration between sites. Three important considerations are:
- Object values differ depending on the site where they are meant to be applied. For instance, an object, like an execution environment, might need to point to a different Automation Hub, depending on the site. Alternatively, a specific automation hub might generate a credential that can't be duplicated.
- The variable Controller_Location could be added to the specific environment controller object that needs to be differentiated, depending on the site. Filter this with an Ansible role filetree_read from the Ansible collection infra.controller_configuration. This variable sets the location of an object, allowing it to be created with different values depending on the site being created. This provides the flexibility of managing multiple sites with the same configuration.
- To automatically trigger the creation, modification, or deletion of objects in the controller, use webhooks. One of these must be created for each environment and each site, and they must point to the controller load balancer based on each site so that the configuration is applied to both places when triggered.
Automation-only active site
This approach must run on the active site only. These considerations apply:
- If webhooks are needed to trigger jobs in the controller automatically, they must be configured to point to the global load balancer to avoid a job being triggered and executed on both sites.
- Controller objects: To control the behavior of objects that need to be active only in the active site (such as schedules or pretasks in playbooks in an active/passive architecture), you must add logic, in addition to variables, to achieve the expected behavior.
First, create a temporary branch to add the basic objects. This applies the configuration in the controller. These objects are projects, credentials, job_templates, workflow_job_templates, schedules, inventories, and hosts. This can be adapted as needed.
[ Download Ansible for DevOps. ]
Wrap up
This architecture creates a workflow to achieve consistency across multiple Ansible Automation Platform sites simultaneously. The solution removes the overhead associated with maintaining database backups or expensive replication solutions while enabling disaster recovery and failover. You can learn more about this reference architecture in the Configuration consistency across multi Ansible Automation Platform deployments docs.
執筆者紹介
Silvio is an IT freak who loves to deploy free software and open source technologies in small home projects. He is a Cloud and Automation Architect at Red Hat.
Ivan is a fan of automation applied to everything and of sharing acquired knowledge. Serves as a consultant at Red Hat and enjoys mountain biking during free time.
Adonis is a system engineer with 10 years of experience working in different companies and projects. Technical profile focused on Linux OS-based technologies and on operation, administration, and implementation of new services on multiple platforms. Adonis is a Red Hat Certified Architect in Infrastructure and a consultant at Red Hat.
類似検索
急激に進化する AI の脅威に対応する防御作とは
Red Hat Ansible Automation Platform による Catalyst 運用の最適化
Untangling Networks | Compiler
Operating System Management | Compiler
チャンネル別に見る

自動化
テクノロジー、チームおよび環境に関する IT 自動化の最新情報

AI (人工知能)
お客様が AI ワークロードをどこでも自由に実行することを可能にするプラットフォームについてのアップデート

オープン・ハイブリッドクラウド
ハイブリッドクラウドで柔軟に未来を築く方法をご確認ください。

セキュリティ
環境やテクノロジー全体に及ぶリスクを軽減する方法に関する最新情報

エッジコンピューティング
エッジでの運用を単純化するプラットフォームのアップデート

インフラストラクチャ
世界有数のエンタープライズ向け Linux プラットフォームの最新情報

アプリケーション
アプリケーションの最も困難な課題に対する Red Hat ソリューションの詳細
仮想化
オンプレミスまたは複数クラウドでのワークロードに対応するエンタープライズ仮想化の将来についてご覧ください