
AI の導入と開発は加速しており、生成 AI やエージェント型 AI が普及しています。新たな市場の出現に伴い、企業は AI を活用して実質的な投資収益率を向上させることに苦労しています。GPU がインフラストラクチャの主流を占めてきたものの、需要の増加に伴うコストの増加と可用性の低下により、経営陣はパフォーマンス要件と顧客満足度基準を満たす代替手段を模索するようになっています。
一方、AI に取り組む開発者とエンジニアは、複雑で時間のかかるインフラストラクチャのセットアップや、検索拡張生成 (RAG) を用いた最適な大規模言語モデル (LLM) 推論のためのソフトウェアスタックとアーキテクチャの構築の難しさという課題に直面しています。使いやすさ、プロプライエタリデータのセキュリティ、さらには AI の構築を開始する方法でさえ、開発者が AI への参入を妨げる可能性のある技術面での課題になります。
Intel と Red Hat のコラボレーションは、Xeon CPU のパフォーマンスと Red Hat OpenShift AI のスケーラビリティを組み合わせ、エンタープライズにおけるエージェント型 AI のデプロイメントのための、保護された、柔軟な基盤を提供します。このプラットフォームでは、ハイブリッドクラウド環境全体で、AI および機械学習モデルとアプリケーションをより安全に、大規模に構築できます。
導入プロセスを単純化するために、Intel では多くの AI クイックスタートを作成しています。AI クイックスタートは、OpenShift を備えた Xeon に迅速にデプロイできる実際のビジネスユースケースの例であり、開発と市場投入までの時間を短縮します。これらのクイックスタートは、AI quickstarts catalog から入手可能です。
Xeon で AI を使用する理由
GPU はディープラーニング、生成 AI、エージェント型 AI において主流となっていますが、推論については、より小型でコスト効率の高いコンピューティング・プラットフォームを使用して、機能およびパフォーマンスの要件を満たすことが可能です。CPU はこれまで、データ処理、データ分析、および従来の機械学習に最適なプラットフォームでした。これには、サポートベクターマシン、XGBoost、K 平均法などの手法を用いた回帰、分類、クラスタリング、およびデシジョンツリーが含まれます。ユースケースには、金融および小売の予測、不正検出、サプライチェーンの最適化などがあります。これは、長期的な AI インフラストラクチャのコスト管理に役立ちます。Intel Xeon は、これらの小規模プラットフォームのヘッドノードとして適しています。
Intel Xeon のハードウェア機能
ハードウェア機能により、Xeon は AI に適した CPU プラットフォームとして際立っています。命令セットである Advanced Matrix Extensions (AMX) と、Multiplexed Rank Dual In-line Memory Modules (MRDIMM) による高メモリ帯域幅が、Xeon を特徴付ける最も重要なコンポーネントです。
AMX は、第 4 世代 Intel® Xeon® Scalable Processors に、組み込みの AI アクセラレーター (コア上の専用ハードウェアブロック) として導入され、個別のアクセラレーターに依存せずに行列演算を実行します。Bfloat16 (BF16) や INT8 などの低精度データ型をサポートしています。BF16 の主な利点は、FP32 と比較して精度を犠牲にすることなくパフォーマンスが向上させることができる点ですAMX による高速化は、PyTorch や TensorFlow などの AI フレームワークに組み込まれた最適化機能により、電力とリソースの使用率を削減し、開発時間を短縮します。
レコメンダーシステム、自然言語処理、生成 AI、エージェント型 AI、およびコンピュータビジョンのユースケースすべてにおいて、AMX を活用することで、エンドユーザーとビジネス双方にとって価値が向上します。

図 1:Intel® AMX は、1 度の操作で大規模な行列を計算する TMUL タイル行列乗算命令を備えた 2D レジスタタイルを特長としています。
AI および LLM 推論において、メモリのボトルネックは、高いメモリ需要によるキーバリュー (KV) キャッシュです。MRDIMM は、計算の複雑さを 2 次から 1 次に移行することでこれに対処し、RDIMM よりも 37% 以上高いメモリ帯域幅を実現します。これにより、AI 推論の実行時にデータ集約型のタスクを処理する際のメモリのスループットが向上し、レイテンシが短縮されます。GPU メモリが制限されているシステムでは、Xeon CPU が KV データをオフロードできるため、高いパフォーマンスを維持しながら高価な GPU リソースを解放できます。
Xeon には、推論、RAG とセキュアなデータ処理、およびエージェント型 AI といった、いくつかの実用的な AI ユースケースがあります。Xeon は機能と性能の両方を備えており、GPU を必要とせずに AI のニーズに対応するためのサポートソフトウェアを備えたプラットフォームです。
Xeon ユースケース 1:AI 推論
LLM 推論は、エンタープライズ・チャットボット、ドキュメントの要約、コードアシスタント、および RAG パイプラインなどのアプリケーションを強化します。大規模な GPU 投資を行わずに、コスト効率の高い生成 AI を求めている中堅企業や組織にとって、Xeon はより現実的な選択肢となる可能性があります。Xeon は、中小規模の LLM および最大 13B パラメータの Mixture-of-Experts (MOE) で最適に動作し、3 秒の Time-To-First-Token (TTFT) や 100 ミリ秒の Time-Per-Output-Token などの標準を満たしています。
Intel は、オープンソースコミュニティと緊密に連携して、vLLM や SGLang などの AI 推論を最適化しています。vLLM は、高スループットとメモリ効率を実現する推論サービスエンジンです。Pytorch.org の vLLM dashboard for Xeon には、Xeon 上の Llama-3.1-8B-Instruct を含む、一般的な LLM の公開されたパフォーマンス数値が掲載されています。Intel は、パフォーマンスの向上と、検証済みモデル (リスト) に対するサポートの追加を継続しています。SGLang は、Intel が Xeon との統合に取り組んでいるもう 1 つの高速サービングフレームワークです。
Xeon ユースケース 2:RAG とセキュアなデータ処理
RAG は、モデルを再トレーニングすることなく、LLM から正確な出力を効果的に得ることができます。ナレッジベースは、ドキュメントの解析、チャンク化、およびメタデータの抽出を使用してデータを準備し、ベクトルデータベースに格納される埋め込みを作成することによって構築されます。すべての操作は、ハードウェアベースの機密コンピューティング技術である Intel® Trust Domain Extensions (TDX) で安全に実行できます。TDX は、ハードウェアで分離された仮想マシン (VM) を使用して、データとアプリケーションを不正アクセスから保護します。これにより、企業は、顧客サポートの自動化、ドキュメント検索、および法務調査のために、利用可能なプロプライエタリデータを迅速に活用できます。検索のレイテンシは低く、同時クエリは Xeon で処理できます。

図 2:Intel® TDX は、メモリの管理と暗号化にハードウェア拡張機能を使用し、データの機密性と整合性を保護します。
Xeon ユースケース 3:エージェント型 AI
AI エージェントは、計画、実行、監視、および反映という一連のロジックに従います。データベースクエリ、API 呼び出し、ファイルアクセスなど、LLM 推論とツール実行を含む混合ワークロードを使用します。Xeon は、モデルコンテキストプロトコル (MCP) サーバー、LlamaStack エージェント型 API、LangChain、および CrewAI フレームワークをサポートしています。IT 運用の自動化、財務上の意思決定支援、およびサプライチェーンエージェントが、対象となるビジネスユースケースです。
OpenShift 上の Xeon:新機能
Red Hat OpenShift AI は、ハイブリッドクラウド、オンプレミス、およびエッジ環境全体で、AI モデルとアプリケーションの構築、トレーニング、および大規模なデプロイメントのライフサイクル全体を管理するための、エンタープライズグレードの AI プラットフォームです。OpenShift AI に含まれるテクノロジーの中でも、vLLM は、ハードウェアコストを削減しながら、最適化された高スループットと低レイテンシのモデル提供を行います。最適化され、本番環境に対応し、検証済みのサードパーティ・モデルのコレクションにより、開発チームは、セキュリティとポリシーの要件を満たすために、モデルのアクセシビリティと可視性をより詳細に制御できます。これらはすべて、高度なツールを使用して自動的にデプロイできるため、AI プロジェクトを迅速に開始し、運用上の複雑さを軽減できます。全体として、AI アプリケーションはより迅速に、本番環境に大規模に移行できます。
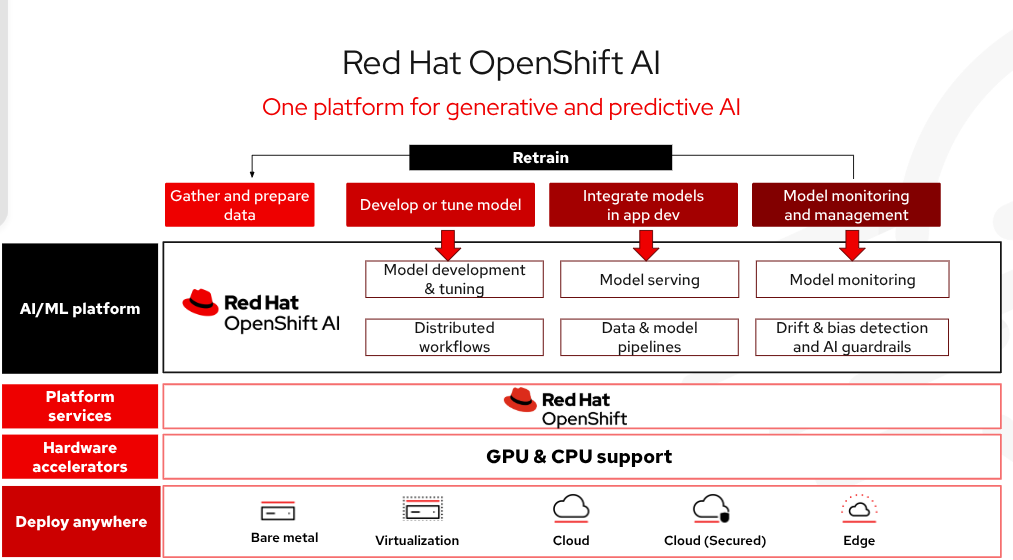
図 3:Red Hat OpenShift AI とは、柔軟でスケーラブルな人工知能 (AI) および機械学習 (ML) プラットフォームです。このプラットフォームにより、企業はハイブリッドクラウド環境全体で AI 対応アプリケーションを大規模に作成および提供できるようになります。
機能
Models-as-a-Service (MaaS) を使用して高性能モデルを簡単にデプロイし、API エンドポイントを使用してアクセスできるため、AI インフラストラクチャの管理にかかる時間が短縮されます。ベアメタル、仮想環境、またはすべての主要なパブリッククラウド・プラットフォーム上の、保護された柔軟な自己管理型ソフトウェアとして、ハイブリッドクラウド全体での柔軟性が確保されます。Red Hat は、一般的なオープンソースの AI/ML ツールとモデル提供をテストおよび統合しているため、開発者はこれらを簡単に使用できます。OpenShift AI には、大規模な分散 AI 推論用のオープンソース・フレームワークである llm-d も含まれています。
vLLM CPU イメージ
Intel は、Red Hat Universal Base Image 上に構築された、vLLM image for CPU on Dockerhub を公開しました。このイメージは AMX を有効にして構築されています。したがって、このイメージを実行するには、第 4 世代 Xeon® Scalable® プロセッサー以降が必要です。現在では、多くのオープンソースモデルが、導入直後から高スループットと低レイテンシで迅速にデプロイし、推論を実行できるようになっています。
AI クイックスタート
OpenShift AI を利用して Xeon 上の vLLM でモデルを最適に実行するための、すぐに実行できるビジネスユースケースの例をご紹介します。これは Operedhat.com 上の クイックスタートで利用可能です。開発者は、これらの例を開始点として利用し、ニーズに合わせてカスタマイズしたり、そのまま使用したりできます。いくつかの AI クイックスタートの初期ドラフトバージョンは GitHub で入手でき、Xeon ですぐに実行できます。すべての最終版クイックスタートは、AI クイックスタート・カタログを通じてリリースされます。
- LlamaStack MCP サーバー – vLLM を活用し、気象報告や HR ツールなどの MCP サーバーに LLM をデプロイします。
- LLM CPU Serving – 小規模言語モデルを提供する軽量 AI リーダーシップおよび戦略チャットアシスタント
- RAG – 検索拡張生成を使用し、専門的なデータソースで LLM を強化して、より正確でコンテキストを認識した応答を実現します。
- vLLM ツール呼び出し – 関数呼び出し機能を備えた vLLM を使用して LLM をデプロイします。
次のステップ
Red Hat OpenShift AI を使用すると、Xeon での AI の利用が簡単になります。管理され、保護された環境は、開発、デプロイメントおよび可観測性に必要な AI インフラストラクチャをセットアップするのに役立ちます。
- パフォーマンスの数値については vLLM dashboard for Xeon を、また AMX サポート付き CPU 用の vLLM イメージを構築/ダウンロードするには、vLLM ドキュメントを参照してください。
- DockerHub の Red Hat Universal Base Image をベースとする CPU 用の vLLM を使用します。
- Xeon 用のサポートされているモデルのリストを確認してください。
- すぐに実行できる例については、AI クイックスタート・カタログを参照し、開発中の AI クイックスタートについては、AI クイックスタート Github にアクセスしてください。
- Red Hat OpenShift AI サイトにアクセスしてください。
製品
Red Hat AI
執筆者紹介
類似検索
急激に進化する AI の脅威に対応する防御作とは
メタルからエージェントへ:エージェント型 AI がアプリケーションの進化形である理由
Technically Speaking | Defining sovereign AI with open source
Technically Speaking | Inside open source AI strategy
チャンネル別に見る

自動化
テクノロジー、チームおよび環境に関する IT 自動化の最新情報

AI (人工知能)
お客様が AI ワークロードをどこでも自由に実行することを可能にするプラットフォームについてのアップデート

オープン・ハイブリッドクラウド
ハイブリッドクラウドで柔軟に未来を築く方法をご確認ください。

セキュリティ
環境やテクノロジー全体に及ぶリスクを軽減する方法に関する最新情報

エッジコンピューティング
エッジでの運用を単純化するプラットフォームのアップデート

インフラストラクチャ
世界有数のエンタープライズ向け Linux プラットフォームの最新情報

アプリケーション
アプリケーションの最も困難な課題に対する Red Hat ソリューションの詳細
仮想化
オンプレミスまたは複数クラウドでのワークロードに対応するエンタープライズ仮想化の将来についてご覧ください