
What’s CRIU?
Snapshotting of virtual machines is used on a daily basis now. Red Hat Enterprise Linux 7.4 beta comes with Checkpoint/Restore In Userspace (CRIU, https://criu.org) version 2.12 which allows snapshot/restore of userland processes, so let’s have a look at that.
Did you ever start a process on a remote system, just to remember seconds later that the process will run for a long time, and will stop in an unpleasant state when you close the remote connection? Of course, having run it in screen/tmux, or with nohup would have helped if you had known that before starting!
CRIU has the potential to help us in this situation with snapshots of long running computing jobs (so you can recover that state in case the system crashes), moving processes to other systems and more.
There were approaches to process migration on Linux in the past, for example:
-
Berkeley Lab Checkpoint/Restart (BLCR): aimed at HPC workloads, required an extra kernel module which was not upstream, required application code to be prepared for checkpointing, the sockets used by the application (i.e. TCP) get closed on process restore and the project looks inactive since some years.
-
The HTCondor framework supports process checkpoint/migration: it’s aimed at balancing compute workloads over farms of compute nodes and no source code change is required for snapshot/restore. This project seems to be active.
Snapshot/Restore of a process
We will use a Red Hat Enterprise Linux 7.4 beta (available on the Red Hat Customer Portal) system to illustrate. Here we install CRIU, which is part of the normal Red Hat Enterprise Linux repo, and perform a check:
[root@rhel7u4 ~]# yum install criu [root@rhel7u4 ~]# criu check Looks good. [root@rhel7u4 ~]#
Let’s look at the ‘long running backup script’ situation mentioned before. We logged onto a remote system and then executed a command which is not running in the background but producing output in our terminal, for example, a backup script. Just after starting we notice that closing the terminal will terminate the script.
In our example, we will now create a new directory, store a simple script there which produces output, start the script, and then use CRIU to ‘move’ the script into a screen session.
Let’s first create and run the script.
[root@rhel7u4 ~]# vi /tmp/criutest.sh [root@rhel7u4 ~]# cat /tmp/criutest.sh #!/bin/bash for i in {0..2000}; do echo foobar, step $i sleep 1 done [root@rhel7u4 ~]# chmod +x /tmp/criutest.sh [root@rhel7u4 ~]# /tmp/criutest.sh foobar, step 0 [..]
At this point we log onto the system from a different terminal, ensure that screen is installed, start a screen session and perform further commands from the screen session.
Next, we find out the PID of our script and execute ‘criu dump’ to initiate the snapshot. As we use no additional options, this will remove the original process. File dumplog.txt will contain details from the dump procedure. Using ‘criu restore’ inside the screen session we will then continue the process - having input/output now directed to the screen session.
[root@rhel7u4 ~]# yum install screen [...] [root@rhel7u4 ~]# mkdir /tmp/criu && cd /tmp/criu [root@rhel7u4 criu]# screen -S criu [screen starts] [root@rhel7u4 criu]# PID=$(pgrep criutest.sh) [root@rhel7u4 criu]# criu dump -o dumplog.txt -vvvv -t $PID --shell-job && echo OK OK [root@rhel7u4 criu]# criu restore -o restorelog.txt -vvvv --shell-job Foobar, step 352 [..]
When executing ‘criu dump’, we instructed to produce an output logfile ‘-o dumplog.txt’, be extra verbose ‘-vvvv’, which PID we want to snapshot (the child PIDs below were also snapshot) and that our process uses the terminal and thus needs to be considered differently ‘--shell-job’.
Modifying the process
Using gdb, processes can be inspected and modified. The snapshot is stored in files, in our example in directory /tmp/criu. Modifying these files is another way to influence the process. Let’s kill the example process which we moved into the screen session and investigate the files:
[root@rhel7u4 criu]# killall criutest.sh [root@rhel7u4 criu]# ls core-2056.img ids-2056.img pages-1.img stats-dump core-2491.img ids-2491.img pages-2.img stats-restore dumplog.txt inventory.img pstree.img tty-info.img fdinfo-2.img mm-2056.img reg-files.img tty.img fdinfo-3.img mm-2491.img restorelog.txt fs-2056.img pagemap-2056.img sigacts-2056.img fs-2491.img pagemap-2491.img sigacts-2491.img
The process state is stored in these files. pagemap* files contain details regarding the virtual regions, pages* files contain the process memory. As this is just a test, let’s try a simple modification of the process:
[root@rhel7u4 criu]# cp pages-1.img pages-1.img.orig [root@rhel7u4 criu]# sed -e 's,foobar,barfoo,g' pages-1.img.orig >pages-1.img [root@rhel7u4 criu]# criu restore -o restorelog.txt -vvvv --shell-job barfoo, step 352 barfoo, step 353 [..]
After restoring the modified process, ‘barfoo’ is printed instead of ‘foobar’.
Live migration of a process
With the commands seen so far, we can already snapshot a process. After making the snapshot files available on a different Linux system, for example using NFS or rsync, we can then restore the process on that system. CRIU already implements the ‘page-server’-mode, which sets up a listener, waits for a connection from a ‘criu dump’ over the network, can then receive the process memory and finally runs the process on the destination system.
The effective process downtime depends mostly on:
-
the amount of memory which is used
-
how quickly the memory changes
-
and the network connectivity between both involved systems.
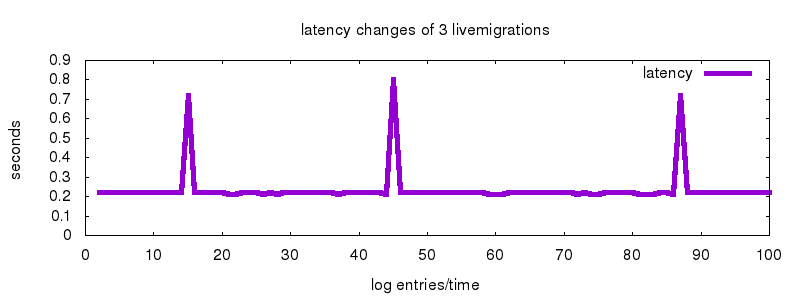
How long is the effective downtime of a process which is getting migrated? I wrote a small script which writes a timestamp into a logfile in 200ms intervals. This process was then migrated to a further Red Hat Enterprise Linux 7.4 system, a second KVM guest on the same hypervisor.
Latency changes of up to 800ms were seen while the process was migrated.
What can we do with this, what are the limits?
Red Hat Enterprise Linux 7.4 is now in beta. CRIU has Technology Preview status at the moment and is not intended to be used on production systems. While playing with this technology, one quickly understands that it’s not yet in production state like KVM live migration.
What are the most important restrictions and characteristics?
-
The restored process has the same PID as the original process - even when the process gets restored on a different system. This prevented some of my attempts to migrate processes - a process with that PID already existed on the destination. Multiple namespaces can help around this limitation.
-
Migrations of processes using unknown socket types fail (‘ping’ using ICMP, ‘hping3’ using RAW socket mode)
-
Shared memory areas are not bound to a single process and are not snapshot by CRIU.
-
IPs remain untouched by CRIU.
-
As of today, snapshotting the original process and resuming the process (possibly on a different system) are 2 separate processes, to be executed for example by a script. If resuming fails, the script has to unfreeze the original script. As of today, this process seems more error prone than for example KVM live migration.
-
CRIU does plain snapshot/restore of the process - there is no rundown of the application, no graceful disconnection of network connections to clients and no closing of files. This is not always a downside: when a system needs to go down for maintenance, one could consider to use CRIU instead of the time-consuming process of shutdown/startup.
-
Further points are mentioned here: https://criu.org/What_cannot_be_checkpointed
How can this help us in the future?
-
Debugging: instead of just taking an application core and finishing the process, we can also snapshot it for debugging on a different system, while keeping it running.
-
Long running computation jobs: snapshotting them in time intervals allows us to later restore the computation, for example after a system crash.
-
System upgrades: now there is kpatch to patch live systems. A further idea is to snapshot a process, kexec into a new kernel, and then restore the process.
-
Assume we have a process which at the beginning takes data via network and then does a lot of computations. We might not trust the memory of the system. Why not snapshot the process and have it finish the calculation on multiple systems, comparing the results?
-
Further usage scenarios: https://criu.org/Usage_scenarios
Where do I get more information?
-
An article with more technical details from Adrian, our CRIU package maintainer
-
Container Live Migration using runC and CRIU, also from Adrian
-
Our kbase around CRIU: https://access.redhat.com/articles/2455211

Christian Horn is a Red Hat AMC TAM in Tokyo. AMC refers to the Red Hat Advanced Mission Critical program, where partners together with Red Hat provide support for systems which are especially essential for companies and business. In his work as Linux Engineer/Architect in Germany since 2001, later as Red Hat TAM in Germany and Japan, Virtualization, operations and performance tuning are among the returning topics of this daily work.
A Red Hat Technical Account Manager (TAM) is a specialized product expert who works collaboratively with IT organizations to strategically plan for successful deployments and help realize optimal performance and growth. The TAM is part of Red Hat’s world class Customer Experience and Engagement organization and provides proactive advice and guidance to help you identify and address potential problems before they occur. Should a problem arise, your TAM will own the issue and engage the best resources to resolve it as quickly as possible with minimal disruption to your business.
Connect with TAMs at a Red Hat Convergence event near you! Red Hat Convergence is a free, invitation-only event offering technical users an opportunity to deepen their Red Hat product knowledge and discover new ways to apply open source technology to meet their business goals. These events travel to cities around the world to provide you with a convenient, local one-day experience to learn and connect with Red Hat experts and industry peers.
執筆者紹介
Christian Horn is a Senior Technical Account Manager at Red Hat. After working with customers and partners since 2011 at Red Hat Germany, he moved to Japan, focusing on mission critical environments. Virtualization, debugging, performance monitoring and tuning are among the returning topics of his daily work. He also enjoys diving into new technical topics, and sharing the findings via documentation, presentations or articles.
類似検索
vi エディター入門
急激に進化する AI の脅威に対応する防御作とは
Container Roundup | Compiler
Untangling Networks | Compiler
チャンネル別に見る

自動化
テクノロジー、チームおよび環境に関する IT 自動化の最新情報

AI (人工知能)
お客様が AI ワークロードをどこでも自由に実行することを可能にするプラットフォームについてのアップデート

オープン・ハイブリッドクラウド
ハイブリッドクラウドで柔軟に未来を築く方法をご確認ください。

セキュリティ
環境やテクノロジー全体に及ぶリスクを軽減する方法に関する最新情報

エッジコンピューティング
エッジでの運用を単純化するプラットフォームのアップデート

インフラストラクチャ
世界有数のエンタープライズ向け Linux プラットフォームの最新情報

アプリケーション
アプリケーションの最も困難な課題に対する Red Hat ソリューションの詳細
仮想化
オンプレミスまたは複数クラウドでのワークロードに対応するエンタープライズ仮想化の将来についてご覧ください