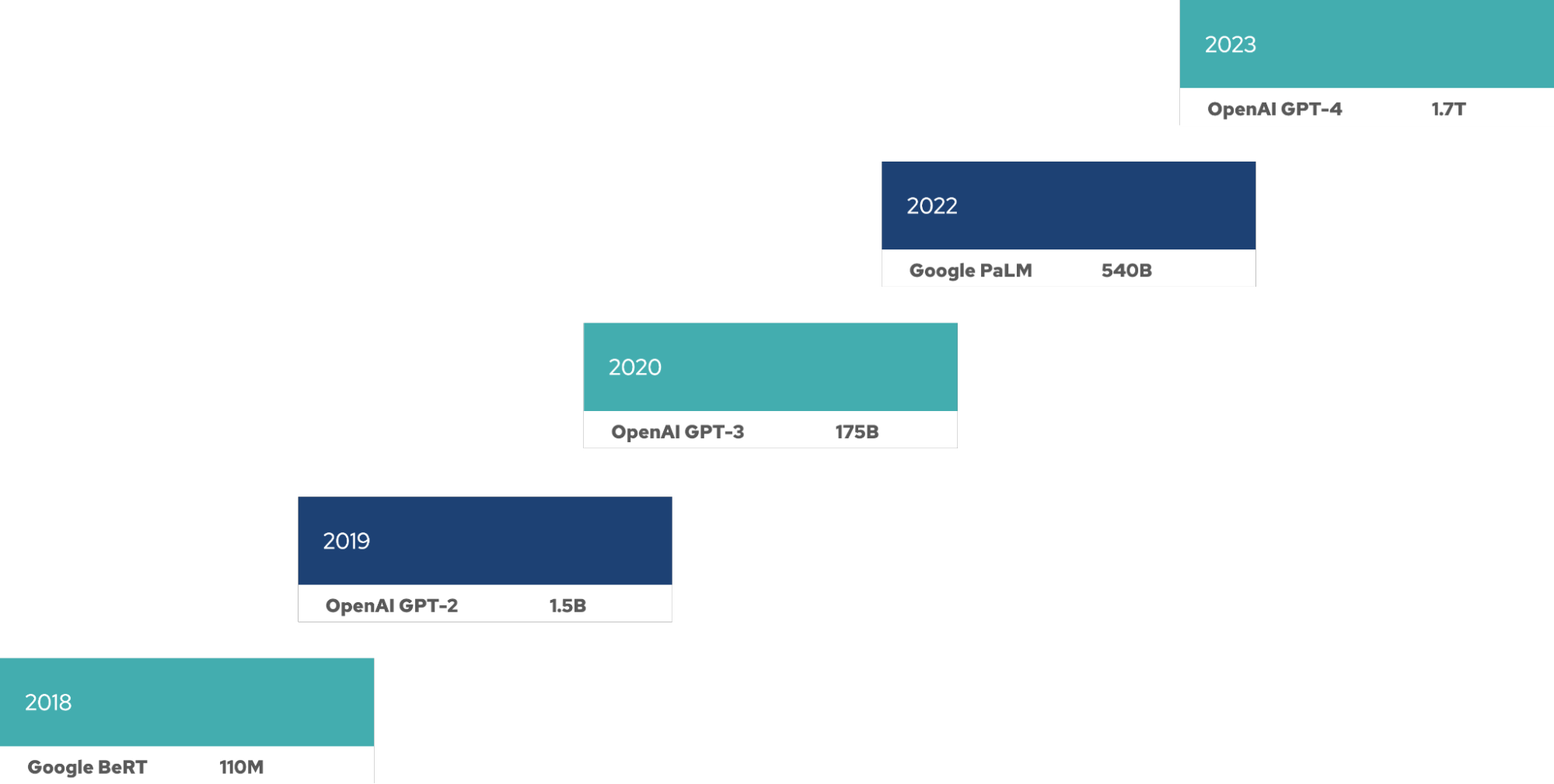
大規模言語モデル (LLM) はどれも、リリースを重ねるごとに大規模化しているように見えます。そのようなモデルのトレーニングには多数の GPU が必要であり、ファインチューニングや推論などには、これらのモデルのライフサイクル全体でさらに多くのリソースが必要になります。これらの LLM には、モデルサイズ (パラメーターの数で測定) が 4 カ月ごとに倍増するという、新しいムーアの法則が存在します。
LLM は高コスト
LLM のトレーニングと運用には多くのリソース、時間、費用がかかり、リソースの要件は LLM をデプロイする企業に直接影響を与えます。デプロイ先が自社のインフラストラクチャであるかハイパースケーラーを利用するかは関係ありません。しかも、LLM の規模はさらに拡大を続けます。
さらに、LLM の運用には多大なリソースが必要です。Llama 3.1 LLM は 4,050 億のパラメーターを持ち、推論だけで 810 GB のメモリーを必要とします (FP16 の場合)。Llama 3.1 モデルファミリーは、3,900 万時間もの GPU 時間を費やして、GPU クラスタ上で 15 兆のトークンを使用してトレーニングされました。LLM のサイズが飛躍的に増加するにつれ、トレーニングと運用に必要なコンピューティングおよびメモリー要件も増大しています。Llama 3.1 のファインチューニングには 3.25 TB のメモリーが必要です。
昨年には GPU の大幅な不足が生じました。現在は供給と需要のギャップが改善しつつありますが、次は電力がボトルネックになると予想されます。オンライン化されるデータセンターが増え、各データセンターの電力消費量が倍増して約 150 MW になることから、これが AI 業界にとって問題になることは容易に理解できます。
LLM のコストを抑える方法
LLM のコストを抑える方法について説明する前に、身近な例を考えてみましょう。カメラは常に進化しており、新モデルが登場するたびに解像度は上がり続けています。そのため、1 枚の写真の raw ファイルサイズは 40 MB (またはそれ以上) になる場合があります。プロの写真家などのこの画像を扱う必要があるユーザーを除き、ほとんどの人は JPEG 画像で満足しており、この場合はファイルサイズを 80% 縮小できます。圧縮することによって画質は元の raw 画像と比べて低下しますが、ほとんどの目的においては JPEG で十分です。さらに、raw 画像の処理や表示には通常、特別なアプリケーションが必要です。したがって、raw 画像を扱う際には、JPEG 画像よりもコンピューティングのコストが高くなります。
では、LLM に戻りましょう。モデルのサイズはパラメーターの数に比例します。ですから、コストを抑えるアプローチの 1 つはパラメーターの数が少ないモデルを使用することです。あらゆる一般的なオープンソースモデルはさまざまなパラメーターを持っており、この中から特定のアプリケーションに最適なものを選択できます。

しかし一般的に、パラメーター数が多い LLM はほとんどのベンチマークでパラメーターの少ない LLM よりも優れたスコアを記録します。したがって、リソース要件を軽減するには、パラメーター数がより多いモデルを使用し、それを小さなサイズに圧縮することが理にかなっている場合があります。GAN 圧縮によって計算量を約 20 分の 1 に削減できるという試験結果も出ています。
LLM の圧縮には、量子化、プルーニング、知識蒸留 (knowledge distillation)、レイヤー削減など、さまざまなアプローチがあります。
量子化
量子化は、モデルの数値を 32 ビット浮動小数点形式から、精度の低いデータ型 (16 ビット浮動小数点、8 ビット整数、4 ビット整数、さらには 2 ビット整数) に変更します。データ型の精度を下げることで、モデルが動作中に必要とするビット数が少なくなり、その結果メモリーと計算量が削減されます。量子化は、モデルのトレーニング後またはトレーニングのプロセスで実行できます。
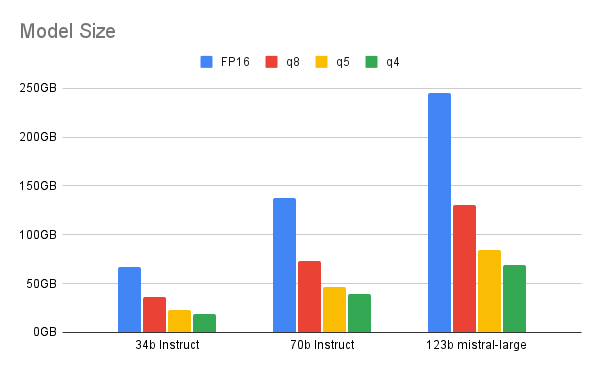
ビット数を下げていくと、量子化とパフォーマンスの間でトレードオフが生じます。こちらの資料では、比較的大規模な (700 億以上のパラメーター) モデル用の 4 ビット量子化で提供される理想的な範囲が示されています。これより低い値では、LLM とその量子化されたものとのパフォーマンスの不一致が顕著に表れます。小規模なモデルでは、6 ビットまたは 8 ビット量子化がより良い選択となる場合があります。
量子化により、この LLM RAG のデモをノートパソコンでも実行できます。
プルーニング
プルーニングは、重要性の低いウェイトやニューロンを除外することでモデルサイズを縮小します。モデルサイズの縮小と精度の維持には、精緻なバランスが求められます。プルーニングは、モデルのトレーニングの前後、またはトレーニング中に行うことができます。レイヤープルーニングは、このアイデアをさらに発展させ、レイヤーのブロック全体を削除します。こちらの資料では、パフォーマンスの低下を最小限に抑えつつ、レイヤーの最大 50% を削除できることが報告されています。
知識蒸留
大規模モデル (教師) から小規模モデル (生徒) に知識を移転します。つまり、小規模モデルに対し、大規模なトレーニングデータではなく、大規模モデルの出力でトレーニングを行います。
こちらの資料では、Google が BERT モデルを DistilBERT へと蒸留したことにより、言語理解能力の 97% を維持しつつ、モデルサイズが 40% 縮小され、推論速度が 60% 高速化したことが示されています。
ハイブリッドアプローチ
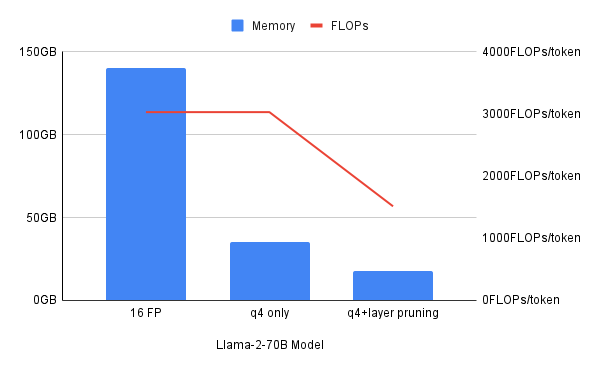
これらの圧縮技術は、それぞれを個別に使用しても有益ですが、場合によっては、複数の圧縮技術を組み合わせたハイブリッドアプローチが最も大きな効果を出します。こちらの資料では、4 ビット量子化によって必要なメモリーが 4 分の 1 に削減されるのに対し、FLOPS (1 秒あたりの浮動小数点演算) で測定されるコンピューティング・リソースは 4 分の 1 にはならないことが示されています。量子化とレイヤープルーニングを組み合わせることで、メモリーとコンピュートリソースのどうちらも削減することができます。
小規模モデルのメリット
小規模なモデルを使用することで、高レベルのパフォーマンスと精度を維持しながら、計算要件を大幅に低減できます。
- コンピューティングコストの削減:小規模なモデルでは CPU と GPU の要件が軽減されるため、大幅なコスト削減が可能になります。ハイエンドの GPU のコストが 1 基あたり 30,000 ドルにもなることを考えると、計算コストの削減は有益です。
- メモリー使用量の削減:小規模なモデルでは、必要なメモリー量は大規模なモデルに比べて少なくなります。これは、IoT デバイスやスマートフォンなど、リソースに制約のあるシステムへのモデルのデプロイに役立ちます。
- 推論の迅速化:小規模なモデルはロードも実行も速いので、推論のレイテンシーが短縮されます。自動運転車のようなリアルタイム・アプリケーションでは、推論の速度は大きな違いをもたらします。
- 二酸化炭素排出量の削減:小規模モデルでは計算量が少なくなるため、エネルギー効率が向上し、環境への影響が軽減されます。
- デプロイの柔軟性:コンピュート要件が軽減されるので、必要な場所にモデルをデプロイするための柔軟性が向上します。動的に変化するユーザーのニーズやシステムの制約に合わせて、ネットワークのエッジを含むさまざまな場所にモデルをデプロイできます。
一般には、より小規模で安価なモデルに注目が集まりつつあり、最近のリリースである ChatGPT-4o Mini (GPT-3.5 Turbo より 60% 安価) や、SmolLM および Mistral NeMo のオープンソース・イノベーションからもそれは明らかです。
- Hugging Face SmolLM:1 億 3,500 万、3 億 6,000 万、17 億のパラメーターを持つ小規模モデルファミリー
- Mistral NeMo:NVIDIA との共同作業で構築された、120 億のパラメーターを持つ小規模モデル
ここまで紹介してきたメリットにより、SLM (小規模言語モデル) への移行がトレンドになっています。事前構築済みのモデルを使用することや、圧縮技術を使用して既存の LLM を縮小するなど、小規模モデルでは多くの選択肢があります。小規模モデルを選択する際には、どのようなアプローチを取るかをユースケースに応じて決める必要があります。これには、慎重な検討が必要になります。
執筆者紹介

Ishu Verma is an AI Solution Architect at Red Hat dabbling in emerging technologies like AI Ops, AI safety and security. He, along with fellow open source hackers, works on building enterprise focused solutions with open source technologies. Prior to Red Hat, Ishu worked in technical marketing at Intel on IoT Gateways and building end-to-end IoT solutions with partners.
チャンネル別に見る

自動化
テクノロジー、チームおよび環境に関する IT 自動化の最新情報

AI (人工知能)
お客様が AI ワークロードをどこでも自由に実行することを可能にするプラットフォームについてのアップデート

オープン・ハイブリッドクラウド
ハイブリッドクラウドで柔軟に未来を築く方法をご確認ください。

セキュリティ
環境やテクノロジー全体に及ぶリスクを軽減する方法に関する最新情報

エッジコンピューティング
エッジでの運用を単純化するプラットフォームのアップデート

インフラストラクチャ
世界有数のエンタープライズ向け Linux プラットフォームの最新情報

アプリケーション
アプリケーションの最も困難な課題に対する Red Hat ソリューションの詳細
仮想化
オンプレミスまたは複数クラウドでのワークロードに対応するエンタープライズ仮想化の将来についてご覧ください