インテルは先頃、第 5 世代インテル® Xeon® スケーラブル・ プロセッサー (インテル Xeon SP)、コードネーム Emerald Rapids を発表しました。これは、さまざまなワークロードに対応する、エンタープライズに特化したハイエンドのプロセッサーファミリーです。インテルの新しいチップがどのように機能するかを確認するために、Red Hat はインテルおよび他社と協力して、Red Hat Enterprise Linux 8.8 / 9.2 以上でのベンチマークを実行しました。
インテルの第 5 世代 Xeon スケーラブルプロセッサーは、既存の第 4 世代 Xeon スケーラブルマザーボードとのドロップイン互換性があります。ソケットあたり最大 64 コア (60 コアとの比較) をサポートし、前世代の DDR5-4800 に対して DDR5-5600 メモリー速度、LLC の最大 3 倍、最大 20 GT/s の UPI 2.0 の速度で処理できます。Red Hat Performance Engineering チームは、パフォーマンス測定を実施するために、これら 2 つのモデル用にインテルのピーク用プロトタイプ・システムを設定しました。
SAP パフォーマンス
第 5 世代インテル Xeon スケーラブルプロセッサーでの RHEL 8.8 SAP HANA のリーダーシップ
Red Hat とインテルは、長年にわたるコラボレーションの歴史を活かして再び連携し、エンタープライズ・データセンターの内外で最先端のパフォーマンスを実現しました。Red Hat の開発チームおよびパフォーマンス・エンジニアリング・チームは、Red Hat Enterprise Linux の GA リリースに先立って 1 年以上にわたり、さまざまなベンチマークを実行し、ハードウェアの有効化およびこれらの新しいスケーラブルな プロセッサーの検証に取り組んできました。
コアごとの強化されたパフォーマンス、より大きなラストレベルキャッシュ、より高速なメモリーおよびストレージをワークロードを最適化したコアと組み合わせると、システム全体のパフォーマンスが向上します。SAP HANA のアプリケーションとワークロードについてのパフォーマンスを実証し、スケーラビリティおよびサイジングに関する追加情報を提供するために、SAP は SAP HANA Standard Application Benchmark の Business Warehouse (BWH) 版 [1] を紹介しました。現在のバージョン 3 では、このベンチマークは異なる分析要件を持つさまざまなユーザーをシミュレートし、以下に定義されている 3 つのベンチマークフェーズのそれぞれに関連する主要業績評価指標 (KPI) を測定します。
- データロードフェーズ、データレイテンシとロードパフォーマンスのテスト (低いほど良い)
- クエリースループットフェーズ。複雑さが中程度のクエリーでのクエリースループットのテスト (高いほど良い)
- クエリーランタイムフェーズ。非常に複雑なクエリーの実行パフォーマンスのテスト (低いほど良い)
Red Hat Enterprise Linux (RHEL) は、上記のベンチマークの最近の公開内容で使用されていました。具体的には、第 5 世代インテル Xeon スケーラブルプロセッサーを搭載した Dell PowerEdge R760 サーバーを使用した 2 つの個別の初期レコードサイズ (13 億レコードと 26 億レコード) により、Red Hat Enterprise Linux でワークロードを実行することで、前世代の Intel と比較してパフォーマンスが大幅に向上することが示されました。 (表 1 を参照)。
表 1. SAP NetWeaver 7.50 および SAP HANA 2.0 で SAP BW Edition for SAP HANA Standard Application Benchmark バージョン 3 を実行したスケールアップカテゴリの結果
初期 レコード (10 億) | フェーズ 1 (低いほど良い) | フェーズ 2 (高いほど良い) | フェーズ 3 (低いほど良い) | |
Red Hat Enterprise Linux 8.8 [2] | 2.6 | 7,083 秒 | 13,410 | 68 秒 |
SUSE Linux Enterprise Server 15 [3] | 2.6 | 10,404 秒 | 9,917 | 76 秒 |
第 5 世代 Intel Xeon と Red Hat Enterprise Linux のメリット | 31.9% | 35.2% | 10.5% |
[1] SAP の結果 (2023 年 3 月 1 日時点)。SAP および SAP HANA は、ドイツおよびその他の国における SAP AG の登録商標です。詳細については、www.sap.com/benchmark を参照してください
。 [2] Dell PowerEdge R760 (2 プロセッサー / 128 コア / 256 スレッド、Intel Xeon
Python 8592+ プロセッサー、1.9 GHz、80 KB L1 キャッシュ、コアあたり 2048 KB L2 キャッシュ、プロセッサーあたり 320 MB L3 キャッシュ、1536 GB メインメモリー)認定番号 #2023076
[3] AtosibleSequana SH20 (2 プロセッサー / 120 コア / 240 スレッド、Intel Xeon
Python 8490H プロセッサー、1.9 GHz、80 KB L1 キャッシュおよびコアあたり 2048 KB L2 キャッシュ、プロセッサーあたり 112.5 MB L3 キャッシュ、1024 GB メインメモリー)。認定番号 #2023028
さらに、13 億の初期レコードのデータセットサイズを使用して、Red Hat Enterprise Linux を実行している Dell EMC PowerEdge R760 サーバーもベンチマーク KPI の 3 つのうち 2 つで同様の構成を有するサーバーを上回りました。これは、データセットのロード時間と複雑なクエリのランタイムが改善されていることを示します (表 2 を参照)。
表 2 SAP NetWeaver 7.50 および SAP HANA 2.0 で SAP BW Edition for SAP HANA Standard Application Benchmark バージョン 3 を実行したスケールアップカテゴリの結果
初期レコード (10 億件) | フェーズ 1 (低いほど良い) | フェーズ 2 (高いほど良い) | フェーズ 3 (低いほど良い) | |
Red Hat Enterprise Linux 8.8 [4] | 1.3 | 6,069 秒 | 17,846 | 65 秒 |
SUSE Linux Enterprise Server 15 [5] | 1.3 | 8,041 秒 | 14,288 | 61 秒 |
第 5 世代 Intel Xeon と Red Hat Enterprise Linux のメリット | 24.5% | 24.9% | -6.6% |
[4] Dell PowerEdge R760 (2 プロセッサー/128 コア/256 スレッド、Intel Xeon
Python 8592+ プロセッサー、1.9 GHz、コアあたり 80 KB L1 キャッシュおよび 2048 KB L2 キャッシュ、プロセッサーあたり 320 MB L3 キャッシュ、1536 GB メインメモリー) 認定番号 #2023075
[5] AtosibleSequana SH20 (2 プロセッサー / 120 コア / 240 スレッド、Intel Xeon
Python 8490H プロセッサー、1.9 GHz、80 KB L1 キャッシュおよびコアあたり 2048 KB L2 キャッシュ、プロセッサーあたり 112.5 MB L3 キャッシュ、1024 GB メインメモリー)。認定番号 #2023026
これらの結果は、OEM パートナーと ISV が共通の顧客に高性能のソリューションを提供できるように支援するという Red Hat の取り組みを示すものであり、Red Hat と Dell の緊密な連携を示すものです。つまり、 SAP との取り組みは、SAP HANA 向けの認定済みのシングルソース・ソリューションの作成へとつながりました。シングルサーバーとそれより大規模なスケールアウト構成の両方で利用できます。Dell のソリューションは、Red Hat Enterprise Linux for SAP Solutions に関して最適化されています。
TPC-H @ SF = 10000
もう 1 つの業界標準ベンチマークは、Transaction Processing Council (TPC) による TPC-H 意思決定支援ベンチマークです。
結果については、TPC-H ベンチマーク @ SF= 10000 で HPE ProLiant DL380 クラスマシンの強力なパフォーマンスが報告され、クエリー/時間 (QphH) のパフォーマンスが 17.9% 向上し、価格性能比 (価格/QphH) が 31.4% 向上しました。監査済みの TPC-H の結果については、HPE によって実行され、RHEL9.3 を実行する第 5 世代 Intel Xeon SP 上で Microsoft SQLserver 2022 64 ビットを使用して実行された結果と、Microsoft Windows Server 2022 Standard Edition オペレーティングシステムで稼働する同じ SQLserver 2022 を使用した第 4 世代 Intel Xeon SP の結果を比較しました。RHEL9.3 と第 5 世代インテル Xeon SP の設計の組み合わせは、サーバーと OS をソリューションにアップグレードする価値を示しており、クラスタ化されていない 10,000GB TPC-H で #1 のパフォーマンス結果を達成しました the #1 non-clustered 10,000GB TPC-H performance result [6]
TPC-H w/ HPE DB @ 10 TB SF = 10000 | |||||||
スポンサー | システム | パフォーマンス (QphH) | kQphH あたりの価格 | システムの可用性 | 提出日 | DB ソフトウェア名 | OS ソフトウェア名 |
旧第 4 世代 Intel Xeon プロセッサー | 2,028,444 | 821.80 米ドル | 5/1/2023 | 2/8/2023 | Microsoft SQL Server 2022 Enterprise Edition 64 ビット | Microsoft Windows Server 2022 Standard Edition | |
新規:第 5 世代インテル Xeon プロセッサー | 2,391,511 | 625.77 米ドル | 6/30/2024 | 1/25/2024 | Microsoft SQL Server 2022 Enterprise Edition 64 ビット | Red Hat Enterprise Linux Server Release 9.3 | |
Gen5/Gen4 の高速化 | 17.9% | 31.4% |
RHEL 9.4 (ベータ版) Intel® AMX による AI/ML とコンピューティングのパフォーマンス
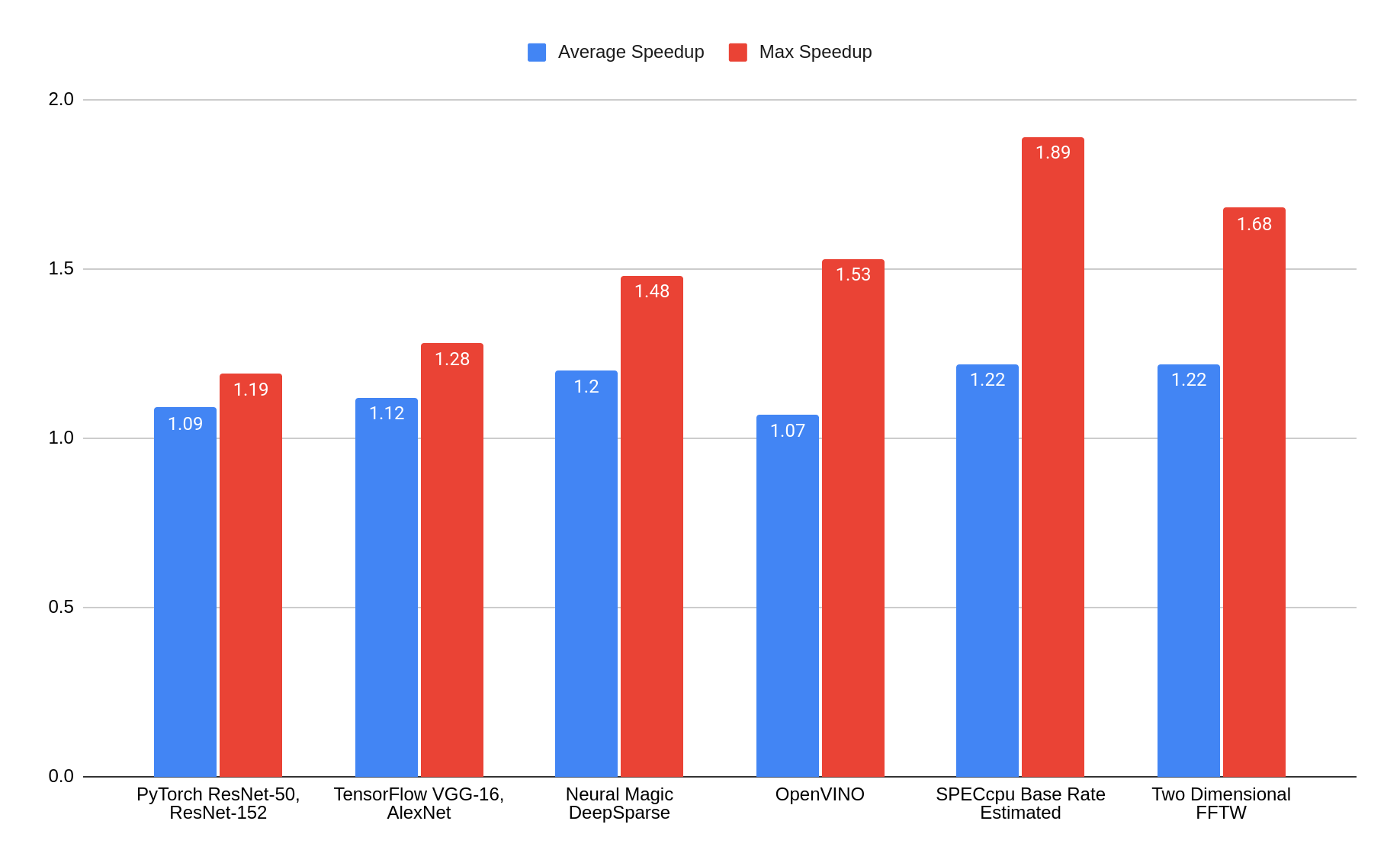
ここでは、PyTorch、TensorFlow、Neural Magic DeepSparse および Intel® OpenVINO™ テストケースに Phoronix Test Suite (PTS) ベンチマークの一部を使用して、以前の第 4 世代インテル Xeon プロセッサー [8] とパフォーマンスを比較することで、AI/ML 機能を実行する第 5 世代インテル Xeon プロセッサー [7] について検証します。これら 4 つのベンチマークスイートには、関連する 100 を超えるサブテストが含まれます。これらの結果を再現するには、[9] を参照してください。
また、SPEC CPU ベースレート (推定) などの一般的な CPU コンピューティングのベンチマークや、ラボシステムで 2 次元 FFTW を実行し、ベータ版 RHEL 9.4 システムとの比較を行いました。
(SPEC CPU Base Rate の結果は公式なものではありません。ic2024.0.2-lin-sapphirerapids-rate-20231213.cfg 構成で Intel バイナリが使用されました)
結果には、そのまま結果として表れるパフォーマンスの向上について示されています。どのベンチマークも、コンパイラーが自動的に検出できる範囲を超えて、第 5 世代インテル Xeon SP に固有のチューニングまたは最適化が行われていません。しかし、結果として、第 4 世代 Intel Xeon SP と比較した場合、第 5 世代 Intel Xeon SP の平均スピードアップ要素は 1.07 から 1.22、最大速度は 1.19 から 1.89 となっています。
まとめ
Red Hat Performance Engineering チームはインテルと連携して、ハードウェアベンダーが本番環境に導入する前に、システム上で Red Hat Enterprise Linux のパフォーマンス機能を確認します。このブログでは、CPU 数の増加、高速 DDR5 メモリー、3 次キャッシュの拡大、プロセッサー間の帯域幅の改善など、インテルの第 5 世代に関する多数の機能を確認しました。これらの機能はすべて、RHEL 8.8 および RHEL 9.2 の出荷バージョンでサポートされています。OEM がこれらの機能を使用して、SAP [1] の業界標準ベンチマークと TPC [6] で優れた結果を達成した方法を紹介しました。また、RHEL 9.4 ベータ版でテストを実施したところ、第 5 世代インテル Xeon SP と第 4 世代インテル Xeon SP を比較すると、CPU ワークロードや AI/ML ベンチマークの処理が大幅に高速化することがわかりました。
インテルと Red Hat のコラボレーションによって機能が拡張されています。Red Hat は、RHEL の今後のバージョンで革新的な機能を継続的に提供し、お客様とパートナーにとって信頼される OS であり続けたいと考えています。
詳細はこちら
- Red Hat と Dell Technologies のソリューション
- Red Hat Enterprise Linux for SAP Solutions
[6] TPC および TPC-H は、Transaction Processing Performance Council の商標です。すべてのサードパーティの商標は、それぞれの所有者に帰属します。https://www.tpc.org/tpch/results を参照してください。2024 年 3 月 15 日現在のすべての比較および記載内容については、10,000 GB でフィルタリングした結果 (https://www.tpc.org/tpch/results/tpch_perf_results5.asp?resulttype=nonc…) をご覧ください。
[7] 第 5 世代インテル Xeon SP ハードウェア構成
Processor: 2 x Intel Xeon Platinum 8592+ @ 3.90GHz (128 Cores / 256 Threads)
Motherboard: Intel D50DNP1SBB (SE5C7411.86B.9533.D01.2310110651 BIOS)
Memory: 1008 GB @ 5800 MT/s
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 52 bits physical, 57 bits virtual
Byte Order: Little Endian
CPU(s): 256
On-line CPU(s) list: 0-255
Vendor ID: GenuineIntel
BIOS Vendor ID: Intel(R) Corporation
Model name: INTEL(R) XEON(R) PLATINUM 8592+
BIOS Model name: INTEL(R) XEON(R) PLATINUM 8592+
CPU family: 6
Model: 207
Thread(s) per core: 2
Core(s) per socket: 64
Socket(s): 2
Stepping: 2
CPU(s) scaling MHz: 100%
CPU max MHz: 3900.0000
CPU min MHz: 800.0000
BogoMIPS: 3800.00
Flags:
fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht
tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc
cpuid aperfmperf tsc_known_freq pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm
pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch
cpuid_fault epb cat_l3 cat_l2 cdp_l3 cdp_l2 ssbd mba ibrs ibpb stibp ibrs_enhanced tpr_shadow flexpriority ept vpid
ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid cqm rdt_a avx512f avx512dq rdseed adx smap avx512ifma
clflushopt clwb intel_pt avx512cd sha_ni avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc
cqm_mbm_total cqm_mbm_local split_lock_detect avx_vnni avx512_bf16 wbnoinvd dtherm ida arat pln pts hwp hwp_act_window
hwp_epp hwp_pkg_req vnmi avx512vbmi umip pku ospke waitpkg avx512_vbmi2 gfni vaes vpclmulqdq avx512_vnni avx512_bitalg
tme avx512_vpopcntdq la57 rdpid bus_lock_detect cldemote movdiri movdir64b enqcmd fsrm md_clear serialize tsxldtrk
pconfig arch_lbr ibt amx_bf16 avx512_fp16 amx_tile amx_int8 flush_l1d arch_capabilities
Virtualization features:
Virtualization: VT-x
Caches (sum of all):
L1d: 6 MiB (128 instances)
L1i: 4 MiB (128 instances)
L2: 256 MiB (128 instances)
L3: 640 MiB (2 instances)
NUMA:
NUMA node(s): 4
NUMA node0 CPU(s): 0-31,128-159
NUMA node1 CPU(s): 32-63,160-191
NUMA node2 CPU(s): 64-95,192-223
NUMA node3 CPU(s): 96-127,224-255
Vulnerabilities:
Gather data sampling: Not affected
Itlb multihit: Not affected
L1tf: Not affected
Mds: Not affected
Meltdown: Not affected
Mmio stale data: Not affected
Retbleed: Not affected
Spec rstack overflow: Not affected
Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl
Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Spectre v2: Mitigation; Enhanced / Automatic IBRS, IBPB conditional, RSB filling, PBRSB-eIBRS SW sequence
Srbds: Not affected
Tsx async abort: Not affected[8] 第 4 世代 Intel Xeon SP ハードウェア設定
Processor: 2 x Intel Xeon Platinum 8480+ @ 3.80GHz (112 Cores / 224 Threads)
Motherboard: Dell 0VRV9X (1.3.2 BIOS)
Memory: 2016 GB @ 4800 MT/s
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 46 bits physical, 57 bits virtual
Byte Order: Little Endian
CPU(s): 224
On-line CPU(s) list: 0-223
Vendor ID: GenuineIntel
BIOS Vendor ID: Intel
Model name: Intel(R) Xeon(R) Platinum 8480+
BIOS Model name: Intel(R) Xeon(R) Platinum 8480+
CPU family: 6
Model: 143
Thread(s) per core: 2
Core(s) per socket: 56
Socket(s): 2
Stepping: 8
CPU(s) scaling MHz: 98%
CPU max MHz: 3800.0000
CPU min MHz: 800.0000
BogoMIPS: 4000.00
Flags:
fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht
tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc
cpuid aperfmperf tsc_known_freq pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm
pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch
cpuid_fault epb cat_l3 cat_l2 cdp_l3 cdp_l2 ssbd mba ibrs ibpb stibp ibrs_enhanced tpr_shadow flexpriority ept vpid
ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid cqm rdt_a avx512f avx512dq rdseed adx smap avx512ifma
clflushopt clwb intel_pt avx512cd sha_ni avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc
cqm_mbm_total cqm_mbm_local split_lock_detect avx_vnni avx512_bf16 wbnoinvd dtherm ida arat pln pts hwp hwp_act_window
hwp_epp hwp_pkg_req vnmi avx512vbmi umip pku ospke waitpkg avx512_vbmi2 gfni vaes vpclmulqdq avx512_vnni avx512_bitalg
tme avx512_vpopcntdq la57 rdpid bus_lock_detect cldemote movdiri movdir64b enqcmd fsrm md_clear serialize tsxldtrk
pconfig arch_lbr ibt amx_bf16 avx512_fp16 amx_tile amx_int8 flush_l1d arch_capabilities
Virtualization features:
Virtualization: VT-x
Caches (sum of all):
L1d: 5.3 MiB (112 instances)
L1i: 3.5 MiB (112 instances)
L2: 224 MiB (112 instances)
L3: 210 MiB (2 instances)
NUMA:
NUMA node(s): 2
NUMA node0 CPU(s): 0,2,4,6,8, . . .
NUMA node1 CPU(s): 1,3,5,7,9, . . .
Vulnerabilities:
Gather data sampling: Not affected
Itlb multihit: Not affected
L1tf: Not affected
Mds: Not affected
Meltdown: Not affected
Mmio stale data: Not affected
Retbleed: Not affected
Spec rstack overflow: Not affected
Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl
Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Spectre v2: Mitigation; Enhanced / Automatic IBRS, IBPB conditional, RSB filling, PBRSB-eIBRS SW sequence
Srbds: Not affected
Tsx async abort: Not affected[9] コンテナでの Phoronix-Test-Suites の使用
PTS フレームワークは、パフォーマンステストを実行するための非常に便利な方法であり、大規模なエコシステムがあり、多数の結果が記録され、比較に利用できます。PTS テストの実行方法を説明する公式手順など、正式な情報については、Phoronix Test Suite および OpenBenchmarking.org を参照してください。
Centos Stream 9 コンテナ (RHEL 9.4 ベータホスト上) で AI/ML 関連のテストを実行し、ホストシステム環境への偶発的な変更を回避し、繰り返されるトライアルごとに白紙の状態にします。
システムで AI/ML 関連のテスト結果を再現する手順:
podman run -it --rm --net=host --privileged centos:stream9 /bin/bashsed -i "/\[crb\]/,+9s/enabled=0/enabled=1/" /etc/yum.repos.d/centos.repodnf -y install https://dl.fedoraproject.org/pub/epel/epel-release-latest-9.noarch.rpmdnf -y install atlas-devel autoconf automake binutils blas blas-devel boost-devel boost-thread bzip2 cmake expat-devel findutils gcc gcc-c++ gcc-gfortran gflags-devel git glog-devel gmock-devel gzip hdf5-devel iputils leveldb-devel libquadmath-devel libusb-devel libusbx-devel lmdb-devel make meson nfs-utils ninja-build openblas-devel opencv opencv-devel openssl-devel patch pciutils php-cli php-json php-xml procps-ng protobuf-compiler protobuf-devel python3 python3-devel python3-pip python3-yaml snappy-devel tar unzip vim-enhanced wget xz zipAt this point you might mount a shared volume with phoronix-test-suite already installed, or you can just download and unpack it in the container with steps like these:wget https://phoronix-test-suite.com/releases/phoronix-test-suite-10.8.4.tar.gztar xvzf phoronix-test-suite-10.8.4.tar.gzcd phoronix-test-suite
./phoronix-test-suite install deepsparse openvino pytorch tensorflow./phoronix-test-suite benchmark deepsparse openvino pytorch tensorflow
執筆者紹介


Michey is a member of the Red Hat Performance Engineering team, and works on bare metal/virtualization performance and machine learning performance.. His areas of expertise include storage performance, Linux kernel performance, and performance tooling.
類似検索
Red Hat and Netris bring multi-tenant networking to sovereign AI clouds and neoclouds
Supercharging local AI development with RHEL on NVIDIA DGX Spark
Technically Speaking | Build a production-ready AI toolbox
Technically Speaking | Platform engineering for AI agents
チャンネル別に見る

自動化
テクノロジー、チームおよび環境に関する IT 自動化の最新情報

AI (人工知能)
お客様が AI ワークロードをどこでも自由に実行することを可能にするプラットフォームについてのアップデート

オープン・ハイブリッドクラウド
ハイブリッドクラウドで柔軟に未来を築く方法をご確認ください。

セキュリティ
環境やテクノロジー全体に及ぶリスクを軽減する方法に関する最新情報

エッジコンピューティング
エッジでの運用を単純化するプラットフォームのアップデート

インフラストラクチャ
世界有数のエンタープライズ向け Linux プラットフォームの最新情報

アプリケーション
アプリケーションの最も困難な課題に対する Red Hat ソリューションの詳細
仮想化
オンプレミスまたは複数クラウドでのワークロードに対応するエンタープライズ仮想化の将来についてご覧ください