AI が国家の競争力の原動力となるにつれ、ソブリン AI (外部からの影響を受けずに AI システムを運用する能力) の概念はますます重要性を増していますが、その導入への道程は課題に満ちています。AI の導入に関する 900 人を超える IT リーダーと AI エンジニアを対象とした最近の調査では、大きな「価値のギャップ」が存在することが明らかになりました。高い意欲 (72%) にもかかわらず、実際の成果を上げているのはわずか 7% であることが示されています。
この調査では、データプライバシーとインフラストラクチャのサイロ化が AI 開発の取り組みを停滞させていることが強調されています。そのため、ソブリン AI の位置付けは、理論上の「クラウドの課題」から、現実的な必要性へと急速に移行しています。ソブリン AI は、Red Hat の調査で特定された具体的なリスクを軽減させることができ、かつ規制対象企業が以下の点を損なうことなく、パイロットから本番環境に確実に移行できるようにします。
- 規制の遵守:一般データ保護規則 (GDPR)、EU AI 法、および市民のデータが特定の境界内にとどまることを義務付けるデータレジデンシー法などの厳格な規制の遵守。
- オペレーショナル・レジリエンス:地政学的不安定状態やグローバルインターネットからの切断時においても業務を継続する能力。
- 戦略的自律性:組織はベンダーロックインを回避し、機密データから生成されたモデルや重みなどの知的財産を完全に制御する。
Red Hat OpenShift AI は、この主権の基盤を提供し、組織がセキュリティ、データ、モデル、および結果の絶対的な制御を維持しながら、「エアギャップ」された AI ファクトリーを構築できるようにします。
この記事では、お客様が直面しているソブリン AI の課題の具体的な例を取り上げて、対処する必要のある主要なテーマを抽象化し、これらの問題に対するソリューションを提案します。
ユーザーストーリー:「AI の独立性」というジレンマ
主人公: Aris 博士 (実際の顧客の課題を基にし複合的な人物像)。中規模の欧州国家の保健省の最高データ責任者。
課題:同省は、数十年にわたる匿名化された患者記録、ゲノム配列、および地域の疫学的履歴といった貴重なデータ資産を保有しています。 Aris 博士は、医師が自国の人口に特有の希少疾患を診断するのを支援するため、「国民健康 LLM」を構築したいと考えています。
重大な点として、同省は現在「シャドー AI」の問題に直面しています。不満を抱えた研究者は、作業を処理するために匿名化されたスニペットをパブリック LLM に密かにアップロードし、データ漏洩のリスクを冒しています。彼らは、パブリッククラウドと同じくらい使いやすい、認可された、完全に安全な内部プラットフォームを必要としています。
対立する状況:
- クラウドの罠:Models-as-a-Service (MaaS) を提供する主要な AI プロバイダーは、機密データを米国を拠点とするパブリッククラウドにアップロードすることを要求します。しかし、これは一般データ保護規則 (GDPR)、データレジデンシー法、および国家安全保障プロトコルに違反する可能性があります。
- DIY の悪夢: Aris 博士は、プラットフォームをゼロから構築しようとします。しかし、彼のチームの運営は、500 個の GPU クラスタへのアクセスを仲裁することによる運用上の混乱によってすぐに麻痺し、絶え間ないリソースの競合が発生するでしょう。そうなると、予約済みのハードウェアがアイドル状態が続く間に、重要な実験の開始を無期限に待機しなければならない状況が生じます。
解決策:そこで、保健省は OpenShift AI 上に、Kubeflow と Feast を使用したソブリン AI プラットフォームを構築します。
- シフト:プロプライエタリーなクラウド API に依存する代わりに、Aris 博士のチームは、独自のエアギャップされた、保護されたインフラストラクチャ上に「モデルファクトリー」を構築します。Kubeflow コンポーネントを含む OpenShift AI は、GPU クラスタのハードウェアを抽象化するので、チームは 1 バイトも国外に送信せずに大規模なモデルをトレーニングできます。Feast は、トレーニングと推論全体で特徴量の管理を一元化するのに役立ち、モデルに供給される特徴量が常に一貫して定義されるようにすることで、ガバナンスとトレーサビリティを可能にします。
- 結果:データサイエンティストがトレーニングリクエストを送信するだけで、システムは分散クラスタを自動的にスピンアップし、Feast から特徴量を取得し、モデルをトレーニングして解体します。これらすべてが、エアギャップされた国内のデータセンター内で行われます。 Aris 博士は、スケーラブルで切断された AI プラットフォームを使用して、自国独自の条件で「AI の自律性」を可能にすることができます。
ソブリン AI の 3 つの柱
「デジタル植民地」、つまり、自国のデジタル経済、データ、および将来の開発に対する制御を失うほど外国の技術インフラストラクチャに大きく依存している国 (またはコミュニティ) から「デジタル主権」へと移行するには、国家は AI テクノロジースタックの 3 つの主要なレイヤーを制御できる必要があります。
テクノロジー主権 (基盤)
原則:主権には、透明性のある証拠保全 (chain of custody) と、サプライチェーンの武器化に対する耐性が必要となります。ハードウェアに依存しないプラットフォーム・レイヤーを導入することで、各国はマルチベンダー戦略によってそれぞれの AI の進展を最適化できるため、グローバル・サプライチェーンの変動に関係なく、戦略的な自律性を維持できます。ソブリン・プラットフォームは、ソフトウェアとハードウェアを切り離し、インフラストラクチャの厳格な所有権と、市場状況への柔軟な適応性を兼ね備えている必要があります。オープンソース標準に準拠することで、組織の AI 機能は、特定のベンダーのロードマップやハードウェアの独占状況に拘束されることなく検査、監査、保守を行うことができ、サービスの継続性に対する絶対的な権限を保持できます。
検証:Red Hat の AI 調査では、IT リーダーの 92% が、エンタープライズ・オープンソースは AI 戦略にとって不可欠であるとしていることが確認されています。これは、AI サプライチェーンを制御するために必要な一貫性と透明性を提供します。
データ主権 (資産)
原則:データの重力は絶対的です。機密データは、主権圏内に物理的に所在する記憶媒体上に保存され、現地の法律のみに準拠しなければなりません。そのため、クラウド環境で見られるようなデータの選択と取得の容易さをデータサイエンティストに提供しつつ、物理的にはデータ移動を安全な内部ネットワークに制限することが課題となります。
運用主権 (管理)
原則:「コントロールプレーン」はローカルである必要があります。重要なワークフローが、コンピューティングリソースまたはユーザーアクセスを管理するのに、別の国でホストされている Software-as-a-Service (SaaS) コンソールに依存することは許されません。ソブリン・プラットフォームには、ID アクセス管理 (IAM) とリソース・オーケストレーションをローカル境界内で完全に処理する、自己完結型のコントロールプレーンが必要です。
技術ソリューション
当社のソリューションは、Red Hat AI が統合されたソブリン・プラットフォームとして機能し、Kubeflow のトレーニング機能と Feast のデータ管理のオーケストレーションを行う、階層化されたアーキテクチャ上に構築されています。
このソリューションは、オープンソース標準、具体的には Kubernetes 基盤を提供する Red Hat OpenShift と Kubeflow プロジェクトに基づいて構築されています。組み込みコンポーネント (モデルレジストリ、KServe、パイプラインとトレーニング、および特徴量の提供用の Feast) を使用することで、組織は自社のテクノロジー・スタックの完全な所有権を維持できます。この透明性により、組織はコードの脆弱性を検査し、プロジェクトのロードマップに直接貢献できます。この点で、Red Hat は、Kubeflow Trainer と Feast がこれらの主権要件をどのようにサポートするかに焦点を当てています。
AI 主権のためのオープンなブループリント:Red Hat AI
真の主権を達成するには、基盤となるプラットフォームが、処理するデータと同じくらい信頼できるものでなければなりません。Red Hat AI は、保護された自己完結型 AI ファクトリーの特定ニーズに対応する、強化されたエンタープライズグレードの基盤を提供します。
Red Hat AI は、完全なインフラストラクチャの独立性を提供します。これは、エアギャップされたベアメタル、プライベートクラウド、または信頼できるソブリンクラウドのパートナーへのデプロイをサポートします。これにより、組織は独自のハードウェアベンダー (NVIDIA、Intel、AMD など) を選択し、サービスの継続性に対する絶対的な権限を保持できます。
- 信頼できるソフトウェア・サプライチェーン:主権はソースから始まります。Red Hat AIは、認証済みで脆弱性スキャン済み、デジタル署名付きの AI ツールのカタログを提供します。これにより、エアギャップ境界内で動作するソフトウェアは既知の脆弱性から解放され、国家安全保障にとって不可欠な要件を満たします。
- 統合された MLOps コントロールプレーン:このプラットフォームは、断片化された AI テクノロジー・スタックを単一のインターフェースに統合します。これはオペレーティングシステム (Red Hat Enterprise Linux)、ハードウェア (GPU)、およびアプリケーション・レイヤー (Kubeflow/Feast) 間の複雑な依存関係を管理するのに役立つため、データサイエンティストはインフラストラクチャの配管作業ではなく、モデリングに集中できます。
- スケーラブルなハードウェア抽象化:ベアメタルラックで実行する場合でも、仮想化されたプライベートクラウドで実行する場合でも、Red Hat AI は物理リソースを抽象化します。これは operator を使用して、国内のスーパーコンピューター内の GPU などの特殊なハードウェアを自動的に調整および公開し、複雑さをユーザーに公開することなく、強力なマルチテナンシーを可能にします。
このように安全な基盤が確立されているので、Red Hat OpenShift AI を安心して使用できます。組織は、Red Hat AI ポートフォリオ内の分散 AI プラットフォームとして OpenShift AI を使用して、AI モデルとアプリケーションを構築し、調整し、デプロイし、管理することができます。これは中枢神経系として機能し、3 つの重要な統合機能を調整します。この 3 つの機能とは、高性能トレーニングエンジン、精密なデータ管理レイヤー、および最適化されたモデル提供フレームワークです。
統合されたコンピューティング:Kubeflow Trainer
ソブリン AI ファクトリーの場合、管理とデータレジデンシーの厳しい要件により、多くの場合、パブリッククラウドのインフラストラクチャに依存するというオプションはありません。真の主権を維持するには、ハードウェアを所有し、運用する必要があります。ただし、この独立性には、複雑な分散ジョブのスケジュール、ノード障害の処理、および高価値のスーパーコンピューティング資産の効率的な使用などを含む、効果的に管理する責任が伴います。
Kubeflow Trainer (OpenShift AI のコンポーネント) は、この運用上のパラドックスを解決します。これは、クラウドネイティブの使いやすさをプライベート・インフラストラクチャにもたらし、Kubernetes 上の分散トレーニングを効率化する高性能エンジンとして機能します。断片化されたワークフローを統合された TrainJob API に置き換えることで、データサイエンティストが複雑なインフラストラクチャ・コードを書き換えなくても、PyTorch や TensorFlow などのフレームワークを拡張できるようにします。
- 単純化:基盤となるソブリン・インフラストラクチャを抽象化することで、大規模な分散トレーニング・タスク向けに、単一の整合性のあるインターフェースを提供します。
- 信頼性:Kubernetes JobSet API に基づいて構築されているため、分散トレーニング・クラスタ内の 1 つのノードで障害が発生した場合でも、グループ全体が正しく管理 (すべてが正常に実行されるか、または 1 つも実行されないかの「全部かゼロか」のスケジューリング) されるようにします。これにより、大規模なトレーニング・ジョブが完全に実行されるか、または正常に再起動されるかのいずれかになるため、リソースの浪費が削減されます。
- 統合:Kueue (OpenShift AI のスケジューリング・スタックの一部) とネイティブに統合してジョブのクォータとキューの作成を管理し、基盤となる OpenShift ノードプールから GPU リソースを動的に割り当てることで、国内のコンピューティング資産を最も効率的に使用できるようにします。
ソブリンデータ:Feast Feature Store
真のデータ主権を実現するには包括的なデータ戦略が必要ですが、未加工データとモデル消費間のギャップを埋めるには、特殊なコンポーネントが必要です。コンピューティング・エンジンを補完する Feast は、ソリューションの「メモリー」として機能します。OpenShift 上で実行される Feast は、モデルを未加工データのインフラストラクチャから分離し、コンプライアンスと再現性を強化します。
Feast は「特定の時点」での正確性を管理するため、モデルは特定の過去の時点で利用可能なデータに基づいてトレーニングされます。これにより、データ漏洩を防ぎ、完全な監査可能性を実現します。
- オフラインストア (MinIO など):エアギャップされた S3 互換のオブジェクトストアに安全に接続し、トレーニング用に高スループットの履歴データを処理します。
- オンラインストア (Redis など):推論用に低レイテンシーの機能を管理するため、リアルタイムの意思決定が主権の境界内で行われます。
- 特徴量レジストリ:特徴量の定義に関する信頼できる唯一の情報源を提供するため、重要な指標 (「患者の年齢」など) はプラットフォーム全体ですべてのデータサイエンティストによって同様に計算され、主権ある知能 (sovereign intelligence) の整合性が維持されます。
ライフサイクルの完了:ソブリンモデルの提供
真の主権はトレーニングにとどまらず、MLOps ライフサイクル全体を包含する必要があります。Kubeflow によってモデルがトレーニングされたら、セキュアな境界を離れることなく、ライブデータを処理するためにデプロイする必要があります。
OpenShift AI は、その統合されたモデル提供機能によりこのプロセスを完結させます。KServe、vLLM、llm-d サポートなどのツールを活用してプラットフォーム内で分散推論を行うことで、組織はモデルのアーティファクトを、トレーニング元の同じエアギャップされたソブリン・クラスタに即座にデプロイできます。つまり、次のことを意味します。
- 推論は社内出行われる:vLLM と llm-d を使用すると、ユーザーのクエリ (医師の診断要求など) とライブ・データストリームはローカルで処理され、パブリック API を通過することはありません。これらのテクノロジーは、PagedAttention を介して GPU メモリーの使用量を最適化し、大規模な基盤モデルを複数の小型 GPU にシャーディングできます。この最適化された機能により、企業は高性能の生成 AI (gen AI) を既存のインフラストラクチャ上でホストすることが、財務的および技術的に可能になり、高価で非主権型のクラウド API をレンタルする必要がなくなります。
- 統合された主権:ハードウェアアクセラレーションからモデルのモニタリングまで、収集 (Feast) → トレーニング (Kubeflow) → 提供 (OpenShift AI) のフロー全体が、ユーザーの制御下にあるソブリン・インフラストラクチャ上で実行されます。
この機能は「開発」フェーズを「統合」および「監視」フェーズに直接つなぎます。つまり、規制対象の企業は、エンドツーエンドの世界水準の AI ファクトリーを完全に自社内で実行できます。
アーキテクチャ
以下の図は、OpenShift AI がどのようにソブリン・プラットフォームレイヤーとして機能し、Kubeflow と Feast をエアギャップ環境で実行するために必要なオーケストレーション、セキュリティおよびハードウェア管理をカプセル化するかを示しています。
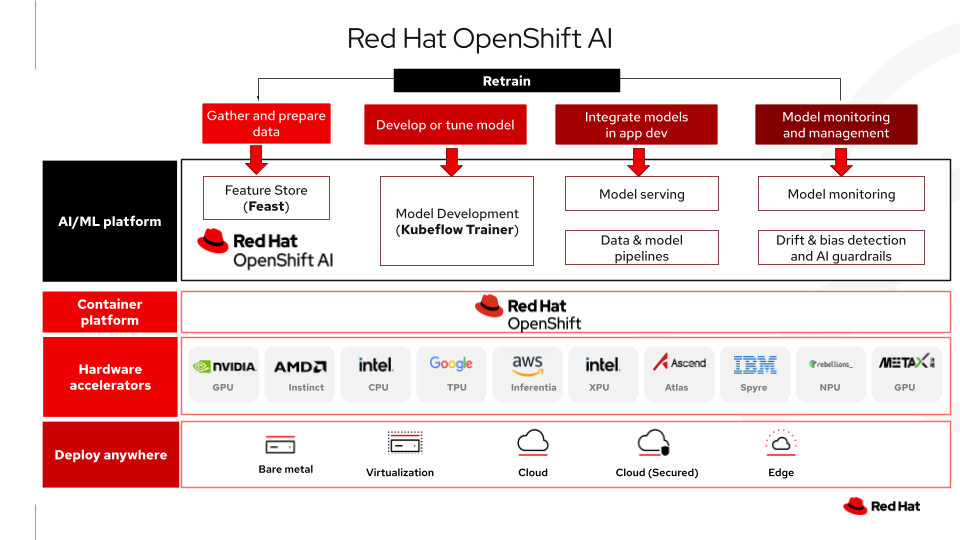
まとめ
ソブリン AI を実現するには、ローカルハードウェアだけでは不十分であり、データの重要性を考慮に入れ、最新の AI ワークフローの複雑さに対応するソフトウェアのアーキテクチャが必要です。
OpenShift AI 内で Kubeflow Trainer や Feast などのテクノロジーを使用することで、組織は次のようなソブリン AI ファクトリーを構築できます。
- 設計上の強さ:データは、保護された境界内でストレージからコンピューティングへ直接流れ、Red Hat のエンタープライズグレードのロールベースアクセス制御 (RBAC) およびオプションの連邦情報処理規格 (FIPS) 準拠で管理されます。
- 拡張性:OpenShift AI と Kubeflow Trainer によって提供される自動化されたハードウェア管理で、Kubernetes 上の分散トレーニングの能力を活用します。
- 再現性:監査可能なデータリネージをサポートするために特徴量ストアを使用します。
このソリューションは、国や企業が独立性を損なうことなく AI の力を活用できるようにし、主権の課題を競争上の優位性に変えます。
独自のソブリン AI ファクトリーを構築する準備はできていますか?
- 技術情報を入手:アーキテクチャの背後にあるコードを確認してみませんか?Red Hat Developer ブログの詳細な技術チュートリアル (Feast と Kubeflow Trainer を使用して RAG 検索を改善) をご覧ください。
- プラットフォームを探す:概要レベルの情報が必要な場合は、Red Hat OpenShift AI にアクセスし、エンタープライズグレードのプラットフォームが、主権型の保護された AI アプリケーションを大規模に構築、デプロイ、管理するのにどのように役立つかを確認してください。
リソース
適応力のある企業:AI への対応力が破壊的革新への対応力となる理由
執筆者紹介

Umberto Manganiello is a Staff Engineer at Red Hat since 2025. Prior to this, he spent over 15 years as a Principal Architect and Engineer in the Financial and Telecommunications sectors. He specializes in designing high-availability systems that operate at massive scale, leveraging deep expertise in Kubernetes, Kafka, and Cloud modernization. Currently, he applies this architectural discipline to the challenges of MLOps, with a focus on GenAI, OpenShift AI, and Kubeflow, blending cloud-native resilience with AI model training workflows.
類似検索
エージェント型のパラドックスとハイブリッド AI の事例
過去を管理するのをやめて、IT の未来を構築しましょう
Technically Speaking | Build a production-ready AI toolbox
Technically Speaking | Platform engineering for AI agents
チャンネル別に見る

自動化
テクノロジー、チームおよび環境に関する IT 自動化の最新情報

AI (人工知能)
お客様が AI ワークロードをどこでも自由に実行することを可能にするプラットフォームについてのアップデート

オープン・ハイブリッドクラウド
ハイブリッドクラウドで柔軟に未来を築く方法をご確認ください。

セキュリティ
環境やテクノロジー全体に及ぶリスクを軽減する方法に関する最新情報

エッジコンピューティング
エッジでの運用を単純化するプラットフォームのアップデート

インフラストラクチャ
世界有数のエンタープライズ向け Linux プラットフォームの最新情報

アプリケーション
アプリケーションの最も困難な課題に対する Red Hat ソリューションの詳細
仮想化
オンプレミスまたは複数クラウドでのワークロードに対応するエンタープライズ仮想化の将来についてご覧ください