Disaster recovery (DR) is the ability to recover and continue business-critical applications from natural or human-created disasters. It is a component of the overall business continuance strategy of any major organization, designed to preserve the continuity of business operations during major adverse events.
Region failure is usually expressed using the terms Recovery Point Objective (RPO) and Recovery Time Objective (RTO).
- RPO is a measure of how frequently you take backups or snapshots of persistent data. In practice, the RPO indicates the amount of data that will be lost or need to be reentered after an outage.
- RTO is the amount of downtime a business can tolerate. The RTO answers the question, “How long can it take for our system to recover after we are notified of a business disruption?”
There are several possible approaches to disaster recovery. As with everything in life, each option comes with its own set of advantages and disadvantages, and we must carefully choose and adapt the most suitable solution.
In this article, I will explain a number of approaches to a DR solution, outline the preliminary requirements for each, and discuss essential considerations across various layers:
- Applications and services — both on the developer and user sides
- Red Hat OpenShift/Kubernetes cluster
- Infrastructure
- Storage
- Network
So, let’s get started.
First option: separate clusters
DR solution based on layer 3 network connectivity

Assumptions
- Network: The Data Center Interconnect (DCI) between the sites is a layer 3 (OSI model) network connectivity.
- OpenShift cluster: Separate OpenShift cluster for the secondary site.
- Secondary cluster: Must provide a replacement for the production cluster that manages the applications (e.g. same cluster version, architecture, security, data loads, network, resources, nodes etc.).
- Load balancer (LB): As part of infrastructure services, each site is planned to have a separate LB, and among them is the use of the global server load balancing (GSLB) module. Based on this solution, which is the responsibility of the network layer, a redirect to the secondary site will be made if necessary.
- Application: The application is deployed and updated in the main and secondary clusters in exactly the same way.
- Storage: A solution for data replication is needed; for example for stateful applications/pods with persistent volume claim (PVC), the container storage interface (CSI) should handle the transfer of information to the secondary site (for example Red Hat CSI OpenShift Data Foundation has two options: Regional-DR or Metro DR). In addition, we can adopt a COLD disaster recovery approach and implement a backup and recovery solution such as Red Hat OpenShift Application Data Protection (OADP) based on the OpenShift API. However, it’s essential to factor in RTO, RPO and the data loss possible. Our goal is to be sure that during a disaster and when transitioning to the secondary site the switch is transparent to the user.
- Infrastructure services: The infrastructure components (e.g. container registry, domain name service (DNS), load balancer, firewall (FW), continuous integration/continuous delivery (CI/CD) tools, etc.) on which the OpenShift/Kubernetes cluster is based should be redundant and with a high-availability (HA) architecture. In order to avoid a dependence between the main site and the secondary site, the infrastructure components should also be separate and capable of self-management at each site.
User experience
Applications can use the fixed fully-qualified domain name (FQDN) of the cluster, and switching between clusters requires a DNS change from the user. If the FQDN is in the application code, refactoring the source code of the application is needed. To provide a more seamless experience for users when accessing the application, we can use GSLB or implement a manual solution, such as a canonical name (CNAME) record.
In an OpenShift cluster, HTTP/HTTPS ingress traffic uses the configured domain for all applications (*.apps.<domain>). To achieve a solution where the application’s DNS names are independent of the cluster name, you can follow these steps:
- Start by implementing a new "global" applications domain in the DNS server.
- Next, be sure that the applications’ routes are associated with the new domain.
- Direct ingress traffic through an external GSLB.
This approach simplifies the process of migrating applications between clusters, making it more user friendly for clients and users.
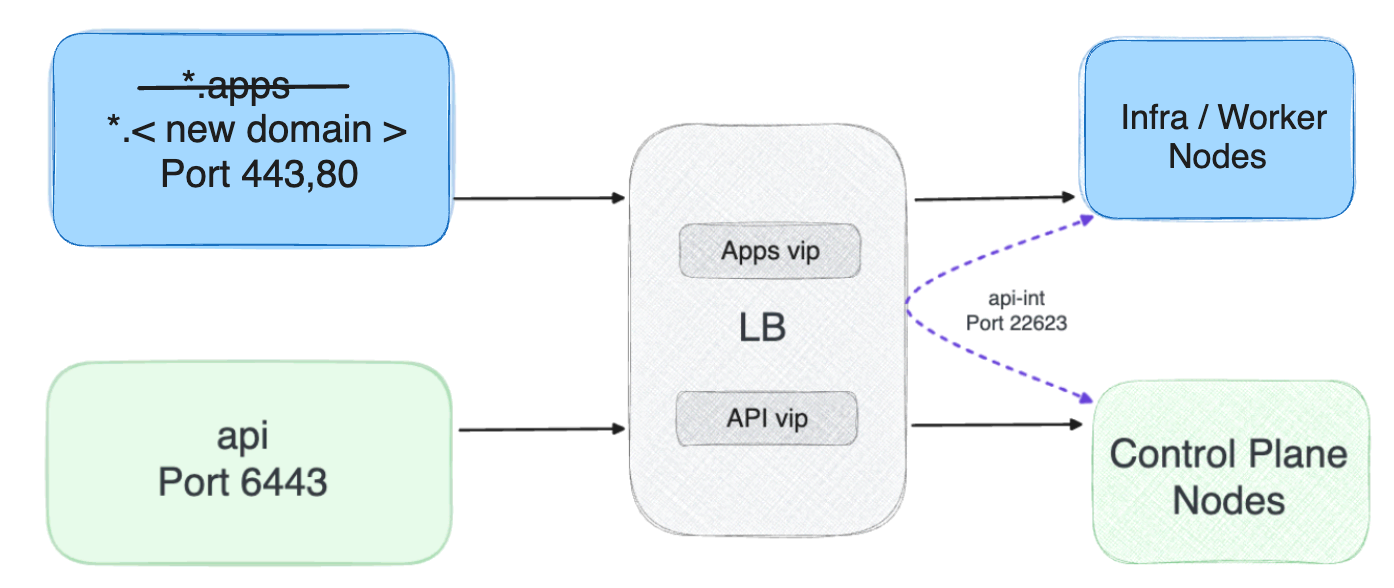
NOTE: This doesn't remove the default *.apps domain, which means you can still use it.
Pros and cons
I would like to emphasize that in the event of a disaster our primary goal is to seamlessly transition users to the secondary site. When it comes to managing two separate OpenShift clusters, several important considerations come into play:
- Application deployments: It’s crucial that applications are deployed both on the main site and the secondary site simultaneously. This synchronization can be achieved through CI/CD processes, which enables consistent deployment on each site. Alternatively, if this isn’t feasible, we can adopt a COLD disaster recovery approach and implement a backup and recovery solution such as OADP based on OpenShift API. Again, however, it’s essential to factor in RTO, RPO and possible data loss.
- User experience (HTTP/HTTPS ingress traffic): To create a seamless experience for users when accessing the application, we can use GSLB or implement a manual solution, such as a CNAME record.
- OpenShift cluster: The secondary cluster needs to be able to replace the production cluster that manages the applications. (e.g. same cluster version, architecture, security, data loads, network, resources, nodes, etc.)
- Network: Separate default gateway (DG), virtual local area networks (VLANs), firewall rules, etc.
- Storage: Implement a data replication solution as described above, either through the CSI, by the application, or by the COLD disaster recovery approach based on OpenShift API.
- Verify changes: Thanks to the complete separation between the sites, we can systematically and more securely verify infrastructure changes, such as upgrades, security adjustments, new operators and more.
- Independence: While I’ve discussed some complex implementation points, it’s crucial to remember a key advantage in this scenario: there is absolutely no dependency between the sites.
Second option: stretch cluster
DR solution based on layer 2 network connectivity
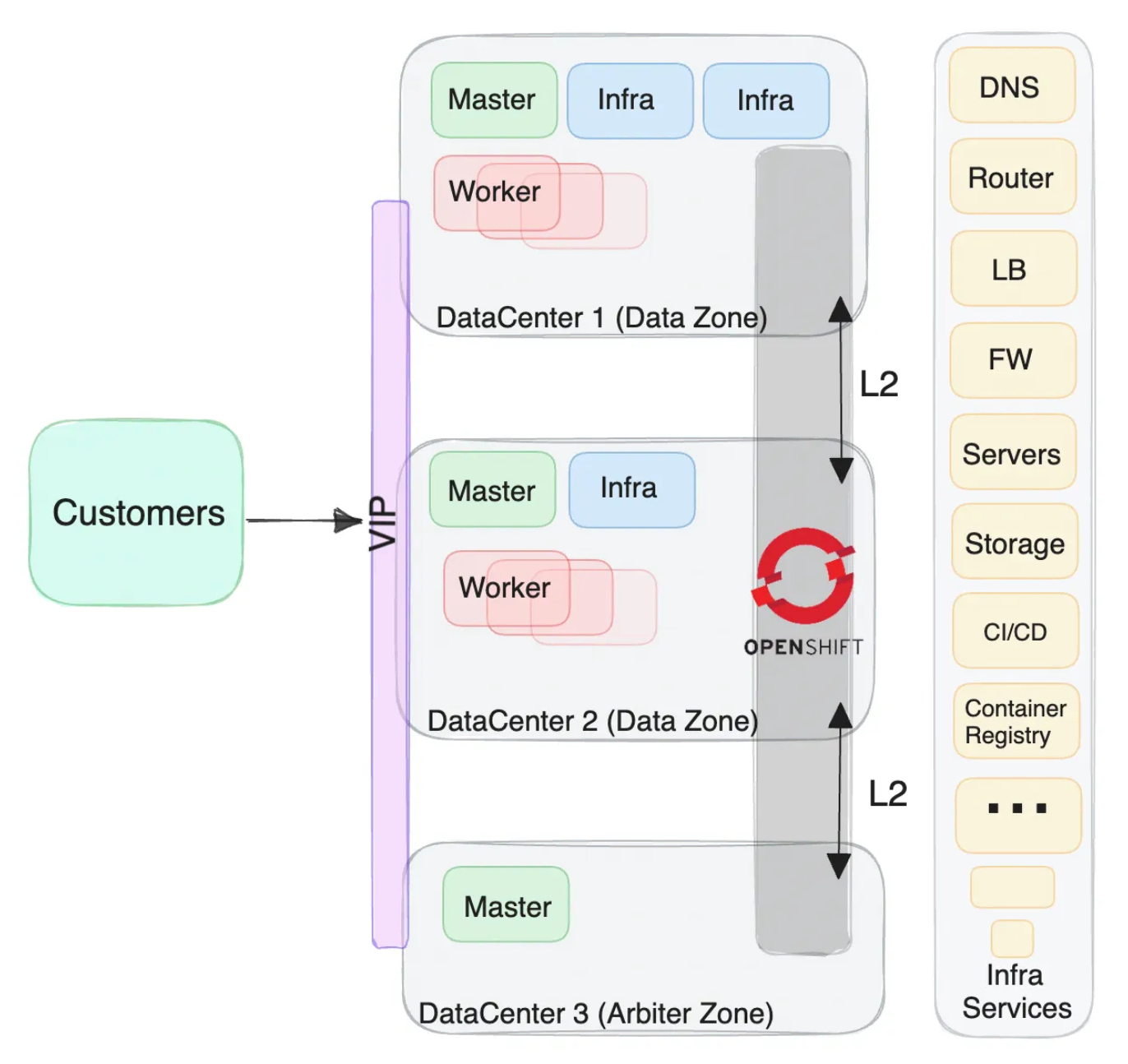
Assumptions
- Network: The Data Center Interconnect (DCI) between the sites is a layer 2 (OSI model) network connectivity with low latency.
- OpenShift cluster: The OpenShift cluster deployment is stretched between different geographical locations.
- User experience (HTTP/HTTPS ingress traffic): Applications can use the fixed FQDN of the cluster, without the need for DNS change in a disaster.
- Infrastructure services: The infrastructure components (e.g. container registry, DNS, LB, FW, CI/CD tools, etc.) on which the OpenShift/Kubernetes cluster is based should be redundant and with a HA architecture and DR solution.
Pros and cons
When using a stretch cluster, several important considerations come into play:
- Application deployments: The same OpenShift cluster deployment is stretched between different geographical locations so that applications will be deployed automatically on all sites.
- User experience: Applications can use the fixed FQDN of the cluster, without the need for DNS change in a disaster.
- OpenShift cluster: There is less need to be concerned about compatibility issues between regions because it’s a single stretched cluster.
- Verify changes: It isn’t advisable to test central changes directly on a production cluster. To verify infrastructure changes such as upgrades, security adjustments, new operators, etc., it is necessary to maintain a separate cluster for testing purposes. It’s important to note that this cluster may not be entirely compatible with the production cluster, especially in terms of size, so testing and verification could be flawed.
- Dependency: In this scenario, there is a dependency between the sites because it's really just a single cluster.
- Low latency: Low latency is required between geographic sites, as the etcd is very sensitive to storage and network latency.
- Arbiter zone: The stretch cluster solution provides business continuity with less chance for data loss, as it is stretched across two data centers with low latency and one arbiter zone. In a disconnected infrastructure, enabling an arbiter zone can be challenging because it effectively represents another separate data center site. While a stretched cluster can be implemented across two sites, it’s important to consider that one of the sites will have two masters. In the event of a disaster affecting the site with the two masters, the cluster will switch to read-only mode, and recovery time to read-write must be taken into account. The purpose of the arbiter zone is to prevent this scenario and always provide a majority. (The chance of both sites failing simultaneously is extremely unlikely).
Backup recommendations
Regardless of the chosen DR solution, it’s always advisable to have a backup (the concept of COLD DR that I mentioned earlier). Here are three examples of backup options:
- A backup of etcd (e.g. daily) for each cluster to enable cluster recovery if necessary.
- COLD DR — a backup and recovery solution based on OpenShift API for Data Protection (OADP).
- Using Git to manage and save applications, deployments, configuration, etc.
Conclusion
Disaster recovery is a matter of the utmost importance as it directly influences an organization’s operational continuity and business resilience.
As discussed here, there are numerous methods and approaches to DR implementation. When designing an architecture, numerous factors must be taken into consideration, including infrastructure, organizational requirements and the associated advantages and disadvantages of the various options. The ultimate objective is to construct an architecture aligned with the organization’s needs, with technology serving as a vital tool in your business continuity strategy.
Learn more
執筆者紹介

Almog Elfassy is a highly skilled Cloud Architect at Red Hat, leading strategic projects across diverse sectors. He brings a wealth of experience in designing and implementing cutting-edge distributed cloud services. His expertise spans a cloud-native approach, hands-on experience with various cloud services, network configurations, AI, data management, Kubernetes and more. Almog is particularly interested in understanding how businesses leverage Red Hat OpenShift and technologies to solve complex problems.
チャンネル別に見る

自動化
テクノロジー、チームおよび環境に関する IT 自動化の最新情報

AI (人工知能)
お客様が AI ワークロードをどこでも自由に実行することを可能にするプラットフォームについてのアップデート

オープン・ハイブリッドクラウド
ハイブリッドクラウドで柔軟に未来を築く方法をご確認ください。

セキュリティ
環境やテクノロジー全体に及ぶリスクを軽減する方法に関する最新情報

エッジコンピューティング
エッジでの運用を単純化するプラットフォームのアップデート

インフラストラクチャ
世界有数のエンタープライズ向け Linux プラットフォームの最新情報

アプリケーション
アプリケーションの最も困難な課題に対する Red Hat ソリューションの詳細
仮想化
オンプレミスまたは複数クラウドでのワークロードに対応するエンタープライズ仮想化の将来についてご覧ください