
In my Introduction to Red Hat Insights, I briefly outlined what this SaaS application does and how to set up your Red Hat Enterprise Linux (RHEL) systems to use the service. This article is dedicated to the "Advisor" in the Insights dashboard.
The Insights dashboard itself is available here.
Author's note: I'm testing the service as part of my job at the Bielefeld IT Service Center (BITS) at Bielefeld University. This article reflects my personal view of Red Hat Insights. Furthermore, I would like to clarify that I am a member of the Red Hat Accelerators community.
Evaluation of the recommendations
There are five recommendations, which I'll evaluate below for my specific environment. All five have in common that I probably would never have deliberately searched for these configuration settings. And there are at least two that are definitely worth taking a closer look at—we'll talk about those first.
OS boot failure occurs due to uncertain disk discovery order when dev/sdN format device names are used in/etc/fstab
This indicates a configuration that, in the worst case, prevents a host from booting. A classification as "important" is therefore understandable. As a system that does not start will send a sysadmin's pulse and adrenaline levels through the roof.
I call up the knowledge base article linked there from the detailed view. It strikes me that although I only use RHEL 7 systems, there is a link to an article that only applies to RHEL 6. After all, this contains a reference to the corresponding article for RHEL 7. Here, Insights could have linked to the RHEL 7 article right away.
- How can static names be assigned for SCSI devices using udev in Red Hat Enterprise Linux 6?
- How are persistent names assigned for SCSI devices using udev in Red Hat Enterprise Linux 7?
How is this entry rated for us now?
The two affected systems have been in operation for some time and have survived several restarts without problems. The potential problem does not seem to have a negative impact, at least in our environment. So I won't worry about it.
In this case, Insights offers the creation of an Ansible remediation playbook, with which the configuration problem can be solved. But, since I am not the system operator for the two systems listed, I cannot do this without consulting the relevant colleague.
I will notify the system operator of this event, forward them the possible solution, and let them decide how to proceed.
Traffic occurs or services are allowed unexpectedly when firewall zone drifting is enabled
This is really an interesting one, at least for me. Because it points out that communication may be permitted through the local host firewall, although this is not the intention (see Fig. 1).
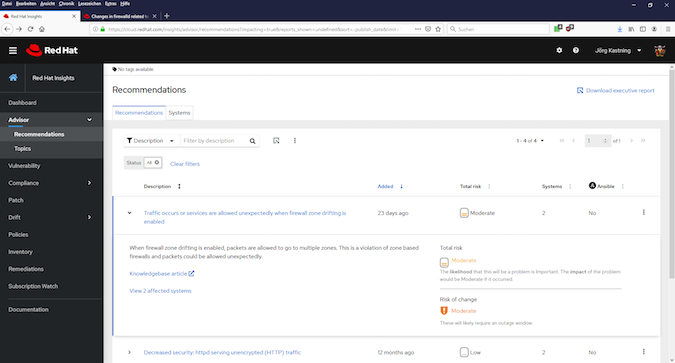
The linked knowledge base article provides detailed information here.
I will definitely address this point with the colleague concerned. I think that a small transfer of knowledge is appropriate here because, in my opinion, other colleagues are also not aware of the specific behavior. I, therefore, rate this advice as good and important.
By the way, one point that I generally like about the Insights dashboard is that I can always see how many systems are affected and, more importantly, which ones they are (see Fig. 2).

Decreased security: httpd serving unencrypted (HTTP) traffic
This is a message that has a low risk rating, and we will treat it accordingly. The affected systems are test systems. The system operator has deliberately decided not to implement TLS / SSL here.
Decreased security: Yum GPG verification disabled (third-party repos)
This point turns out to be interesting, contrary to expectations. We operate our own repositories, which are only used within our facility. In order to minimize the effort, we do not sign the packets using GPG.
However, the fact that GPG signature verification for a mirrored RHEL repo is deactivated for some hosts is surprising. To find out, you don't have to connect to an affected system and examine them; all it takes is a click on the hostname in the list of affected systems (see Fig. 2) to get to a view that offers a detailed description as well as a solution.
Insights not only helps you find out what's wrong but also how to fix the problem. In the course of the test, I will continuously check how often Insights can come up with useful solutions.
Slow system boot when storage devices do not support WRITE SAME command
This indicates a problem that can reduce the performance of the system during the boot process.
Insights recognized this incident after the affected system was restarted, the insights client ran again, and Insights found a corresponding message in /var/log/messages.
The problem itself has been known to us for a long time. However, it falls into the category—"Let's have a look when we have time" (which means never). Fortunately, our VMs boot within a few seconds, and no problem is perceived here.
General aspects of the Dashboard and Advisor
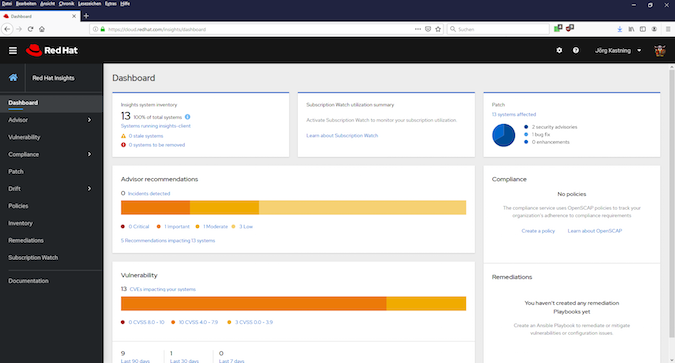
The dashboard gives an overview of how many systems are currently included in Insights, whether there are problems with these systems, the patch status, vulnerabilities, compliance status, implemented remediations, and advisor recommendations.
The dashboard in Fig. 3 shows that Insights has a total of six recommendations for the 13 connected systems with which the system configuration can be improved.
Via the menu on the left-hand side or the link in the field of advisor recommendations, you can get to the Advisor view, which presents the recommendations in an overview (see Fig. 4).
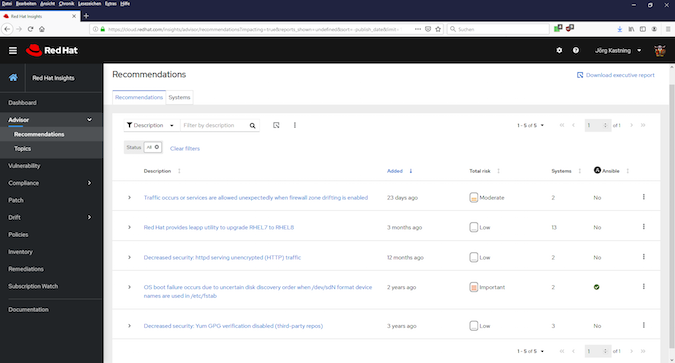
The tabular overview in Fig. 4 shows the recommendations with a brief description of how long this recommendation has existed in Insights, a risk assessment, how many systems are affected, and whether an Ansible Playbook exists with which the described problem can be solved.
The first thing that catches my eye is the second point. With a click on the arrow in front of the description, further details appear (see Fig. 5). Here, you will learn that it is probably not a problem if you are not immediately upgrading to RHEL 8, and that an upgrade will probably require a maintenance window with downtime. The linked knowledge base article provides further information.
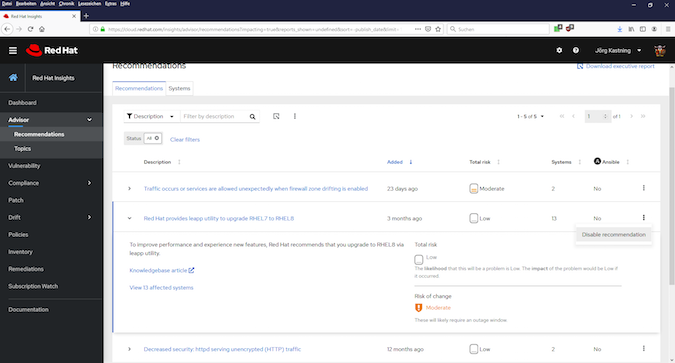
I personally rate the recommendation selected in Fig. 5 as ineffective. RHEL 7 is still under maintenance and receives security updates. It is known that version 8.2 has been released and that it comes with new functions and improvements, but there is no reason for hasty upgrades. In addition, we generally do not run in-place upgrades. Instead, we install a new virtual machine (VM), migrate data and services, and then turn off the old host.
Fortunately, reports such as these don't have to be annoying forever. As can be seen in Fig. 5, Insights offers the option of simply deactivating messages. I find it very helpful that you can give a reason (see Fig. 6), so you can remember after weeks or months why you have deactivated an entry.
The Insights team agreed with my opinion above from Fig. 5 and removed this option to avoid causing customer confusion. This is a great example of how Red Hat values the feedback of its customers.

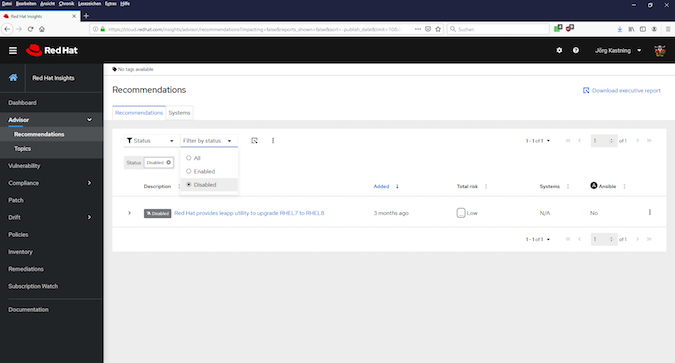
After deactivating, the entry is no longer displayed in the overview (see Fig. 7).

After deactivating an entry, the question immediately came to my mind where I can find it again. This is possible via the filter settings in the upper area of the page (see Fig. 8).
Interim conclusion
I am still at the beginning of our test. The findings to date, therefore, are insufficient to make a a final assessment as to whether a permanent and extensive use of Insights is justified.
My first impression remains that Red Hat Insights is a user-friendly interface that allows intuitive operation. So far, the advisor contains some interesting tips along with some not so important ones.
[ Attend a Red Hat Insights Ask Me Anything with product manager Jerome Marc, focused on comparing systems with Drift, on July 23, 2020. ]
About the author
Jörg has been a Sysadmin for over ten years now. His fields of operation include Virtualization (VMware), Linux System Administration and Automation (RHEL), Firewalling (Forcepoint), and Loadbalancing (F5). He is a member of the Red Hat Accelerators Community and author of his personal blog at https://www.my-it-brain.de.
More like this
How Red Hat solves the toughest challenges in agentless infrastructure scanning
An introduction to the vi editor
Infrastructure At The Edge | Compiler
Operating System Management | Compiler
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds