
My previous article showed how containers communicate within a pod through the same network namespace. This article looks at how pods communicate with each other when those pods exist on different Kubernetes nodes.
Kubernetes defines a network model called the container network interface (CNI), but the actual implementation relies on network plugins. The network plugin is responsible for allocating internet protocol (IP) addresses to pods and enabling pods to communicate with each other within the Kubernetes cluster. There are a variety of network plugins for Kubernetes, but this article will use Flannel. Flannel is very simple and uses a Virtual Extensible LAN (VXLAN) overlay by default.
You often hear about overlay networks in the context of Kubernetes networking. While this may sound complicated, an overlay network simply involves another layer of encapsulation for network traffic. For example, the Flannel network plugin takes traffic from a pod and encapsulates it inside the VXLAN protocol. This article takes a deep dive into how this encapsulation works and how the traffic appears on the wire.
[ Learn how to manage your Linux environment for success. ]
Environment setup
The environment for this article uses a two-node minikube cluster with the Flannel network plugin. You can start the necessary minikube environment using:
$ minikube start --nodes 2 --network-plugin=cni --cni=flannel
😄 minikube v1.25.2 on Ubuntu 20.04
✨ Automatically selected the kvm2 driver. Other choices: virtualbox, ssh
❗ With --network-plugin=cni, you will need to provide your own CNI. See --cni flag as a user-friendly alternative
👍 Starting control plane node minikube in cluster minikube
🔥 Creating kvm2 VM (CPUs=2, Memory=2200MB, Disk=20000MB) ...
🐳 Preparing Kubernetes v1.23.3 on Docker 20.10.12 ...
▪ kubelet.housekeeping-interval=5m
▪ Generating certificates and keys ...
▪ Booting up control plane ...
▪ Configuring RBAC rules ...
🔗 Configuring Flannel (Container Networking Interface) ...
🔎 Verifying Kubernetes components...
▪ Using image gcr.io/k8s-minikube/storage-provisioner:v5
🌟 Enabled addons: storage-provisioner, default-storageclass
👍 Starting worker node minikube-m02 in cluster minikube
🔥 Creating kvm2 VM (CPUs=2, Memory=2200MB, Disk=20000MB) ...
🌐 Found network options:
▪ NO_PROXY=192.168.50.43
🐳 Preparing Kubernetes v1.23.3 on Docker 20.10.12 ...
▪ env NO_PROXY=192.168.50.43
🔎 Verifying Kubernetes components...
🏄 Done! kubectl is now configured to use "minikube" cluster and "default" namespace by default
# Verify that nodes are up and ready
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
minikube Ready control-plane,master 65s v1.23.3
minikube-m02 Ready <none> 34s v1.23.3
The diagram below shows the basic topology for this environment. I will describe each component of this topology in more detail throughout the article.

Below are the Kubernetes manifests that define the fedora-1 and fedora-2 pods. A nodeSelector is used to ensure that each pod runs on a separate host for this experiment.
Here is k8s_flannel_fedora_1_definition.yaml:
apiVersion: v1
kind: Pod
metadata:
name: fedora-1
spec:
nodeSelector:
kubernetes.io/hostname: minikube
containers:
- command:
- sleep
- infinity
image: fedora
name: fedora
And k8s_flannel_fedora_2_definition.yaml:
apiVersion: v1
kind: Pod
metadata:
name: fedora-2
spec:
nodeSelector:
kubernetes.io/hostname: minikube-m02
containers:
- command:
- sleep
- infinity
image: fedora
name: fedora
Note that throughout this article, I enter the pods and execute commands within their namespaces. Many of these commands are not installed by default, but you can install them using DNF. I'm entering pods only for explanatory reasons, and you should avoid "logging in" to pods and directly installing utilities in a production environment.
The OSI model is the major standard for describing communications between computer or telecom systems. The model is divided into seven layers, each covering a different responsibility within the network communication process. This article focuses on Layer 2 (the data link layer) and Layer 3 (the network layer).
The Layer 2 network
This exercise sends a ping from the fedora-1 pod to the fedora-2 pod and traces it through the network stack. Connecting to the fedora-1 pod and inspecting its network stack reveals that it has an eth0@if10 interface. This interface is one side of a virtual Ethernet pair.
A virtual Ethernet pair allows connections between network namespaces, such as between a pod's namespace and the host's default namespace. The @if10 and output of ethtool indicate that the peer interface index on the host is 10.
# Enter the fedora-1 pod
$ kubectl exec -it fedora-1 -- /bin/bash
# Inspect the network configuration within the fedora-1 pod
[root@fedora-1 /]# ip link sh
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: sit0@NONE: <NOARP> mtu 1480 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/sit 0.0.0.0 brd 0.0.0.0
4: eth0@if10: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP mode DEFAULT group default
link/ether 92:73:8f:43:67:1b brd ff:ff:ff:ff:ff:ff link-netnsid 0
[root@fedora-1 /]# ethtool -S eth0
NIC statistics:
peer_ifindex: 10
You can now inspect the network configuration on the minikube host. There are several additional interfaces, but the network configuration within the fedora-1 pod indicates that the interface with index 10 is the remote end of the virtual Ethernet pair. The interface with index 10 on the minikube host is vetheaa97948@if4, and the @if4 and output of ethtool both indicate that the remote peer index is 4. This index corresponds with the eth0 interface from the fedora-1 pod, which has an interface index of 4.
# Inspect the network configuration on the minikube host
$ ip link sh
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether 52:54:00:37:09:5c brd ff:ff:ff:ff:ff:ff
3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether 52:54:00:ea:1b:4a brd ff:ff:ff:ff:ff:ff
4: sit0@NONE: <NOARP> mtu 1480 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/sit 0.0.0.0 brd 0.0.0.0
5: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN mode DEFAULT group default
link/ether 02:42:7e:1b:3c:46 brd ff:ff:ff:ff:ff:ff
6: cni-podman0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN mode DEFAULT group default qlen 1000
link/ether aa:8b:b8:3b:ae:0d brd ff:ff:ff:ff:ff:ff
8: flannel.1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN mode DEFAULT group default
link/ether 3e:7d:76:2a:39:82 brd ff:ff:ff:ff:ff:ff
9: cni0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether c6:ae:d0:e6:66:cc brd ff:ff:ff:ff:ff:ff
$ ethtool -S vetheaa97948
NIC statistics:
peer_ifindex: 4
10: vetheaa97948@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master cni0 state UP mode DEFAULT group default
link/ether 0e:52:e0:c4:14:74 brd ff:ff:ff:ff:ff:ff link-netnsid 0
The virtual Ethernet pair also connects to a bridge on the minikube host. This allows pods on the same host to communicate directly with each other over the bridge. The cni0 bridge interface has an IP address assigned to it, which will be important in the Layer 3 routing process:
# Bridge configuration on minikube host
$ brctl show
bridge name bridge id STP enabled interfaces
cni-podman0 8000.aa8bb83bae0d no
cni0 8000.c6aed0e666cc no vetheaa97948
docker0 8000.02427e1b3c46 no
# Bridge interface IP address on minikube host
$ ip -br addr sh cni0
cni0 UP 10.244.0.1/24
After investigating the network stack within the flannel-1 pod and the minikube host, here is how the network diagram appears:
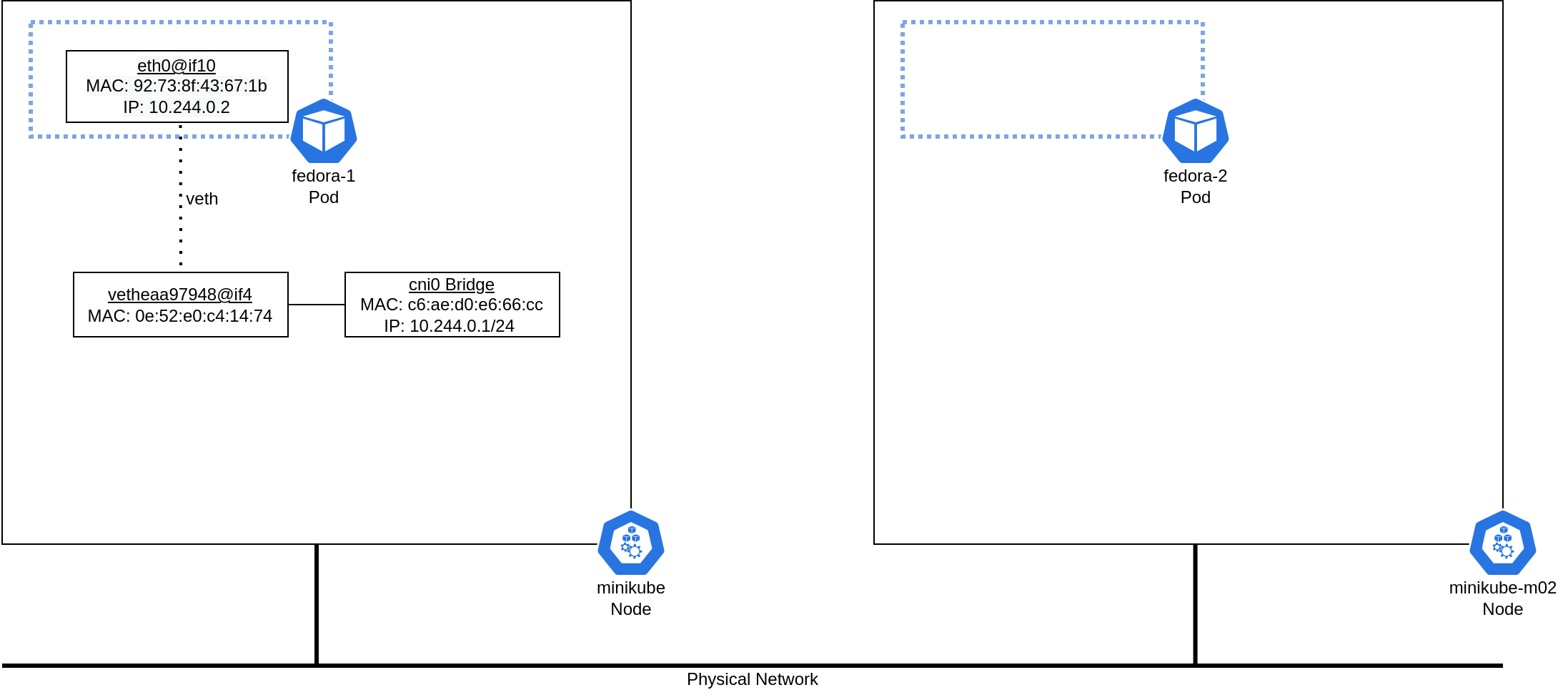
The Layer 3 network
At this point, a good portion of the Layer 2 part of the diagram is filled out. However, this only provides local connectivity for the pod. Next, consider how fedora-1 at 10.244.0.2/24 can communicate with fedora-2 at 10.244.1.3/24, which is in a different Layer 3 network.
[ Get the guide to installing applications on Linux. ]
First, the fedora-1 pod must decide where to send traffic for the remote network. The routing table does not include a specific route containing 10.244.1.3, so fedora-1 will send the traffic to its default gateway. The default gateway is at 10.244.0.1, which is the IP address of the cni0 bridge on the minikube host:
# The default route is 10.244.0.1, which is the cni0 bridge on the Minikube host
[root@fedora-1 /]# ip route sh
default via 10.244.0.1 dev eth0
10.244.0.0/24 dev eth0 proto kernel scope link src 10.244.0.2
10.244.0.0/16 via 10.244.0.1 dev eth0
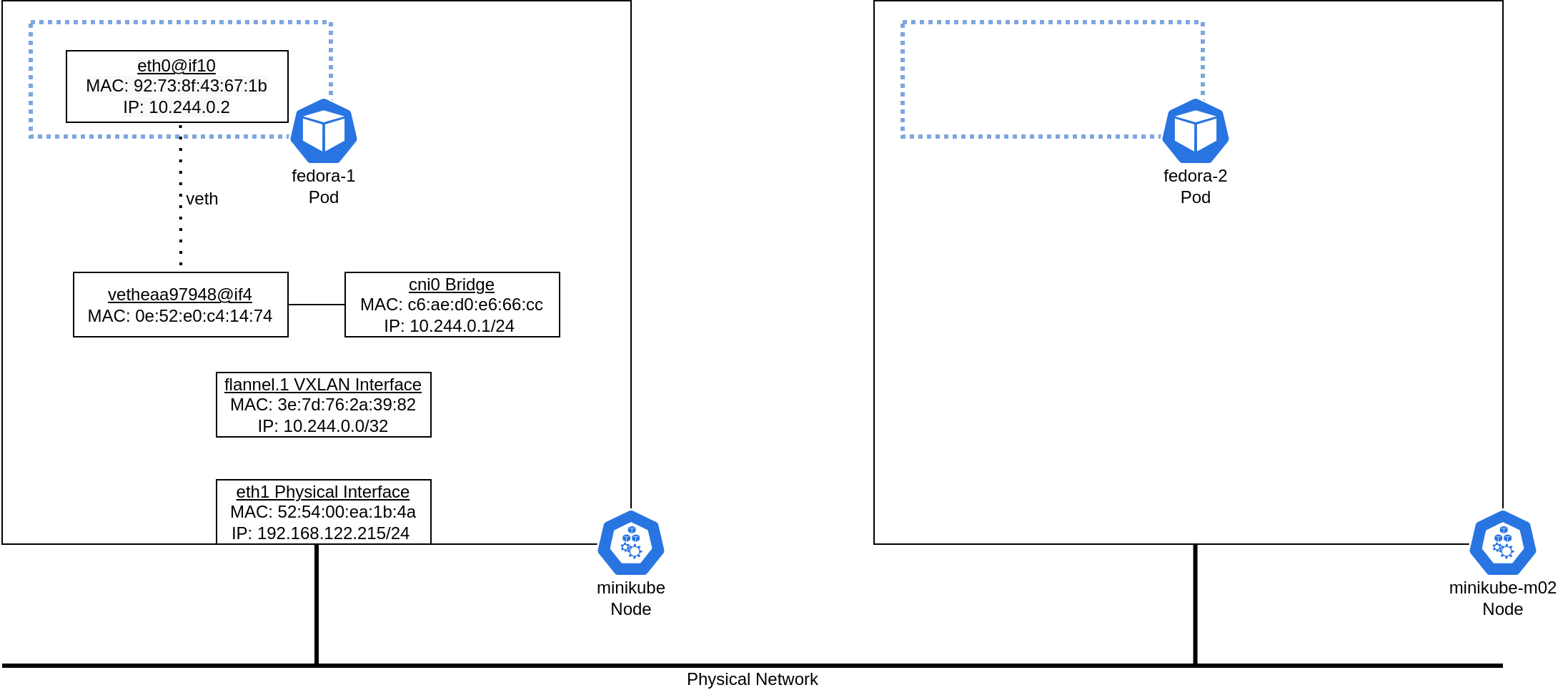
Once the traffic has reached the default gateway, the next routing decision will determine how to forward that traffic to the desired network (10.244.10/24). The host's routing table shows that traffic destined to the 10.244.1.0/24 network will be sent via 10.244.1.0 on the flannel.1 interface:
# Routing table on minikube node
$ ip route sh
default via 192.168.122.1 dev eth1 proto dhcp src 192.168.122.215 metric 1024
10.88.0.0/16 dev cni-podman0 proto kernel scope link src 10.88.0.1 linkdown
10.244.0.0/24 dev cni0 proto kernel scope link src 10.244.0.1
10.244.1.0/24 via 10.244.1.0 dev flannel.1 onlink
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1 linkdown
192.168.61.0/24 dev eth0 proto kernel scope link src 192.168.61.95
192.168.122.0/24 dev eth1 proto kernel scope link src 192.168.122.215
192.168.122.1 dev eth1 proto dhcp scope link src 192.168.122.215 metric 1024
The flannel.1 interface is a VXLAN interface with a VXLAN ID of 1 and an IP address of 10.244.0.0/32:
# flannel.1 interface on minikube host
$ ip -d link sh flannel.1
8: flannel.1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN mode DEFAULT group default
link/ether 3e:7d:76:2a:39:82 brd ff:ff:ff:ff:ff:ff promiscuity 0 minmtu 68 maxmtu 65535
vxlan id 1 local 192.168.122.215 dev eth1 srcport 0 0 dstport 8472 nolearning ttl auto ageing 300 udpcsum noudp6zerocsumtx noudp6zerocsumrx addrgenmode eui64 numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535
$ ip -br addr sh flannel.1
flannel.1 UNKNOWN 10.244.0.0/32
The next hop for a packet from fedora-1 to fedora-2 is 10.244.1.0. However, no interface on the network contains the 10.244.1.0 address. Instead, a static Address Resolution Protocol (ARP) entry exists on the ARP table on the minikube host. This static entry indicates that the MAC address for 10.244.1.0 is d2:d8:a1:85:9e:38. The bridge forwarding database directs traffic for this MAC address to a remote destination of 192.168.122.7. This remote address, which is the physical interface on the minikube-m02 node, is the other side of the VXLAN tunnel.
# ARP table on minikube host. Note that some entries have been removed for brevity.
$ arp -a
? (10.244.1.0) at d2:d8:a1:85:9e:38 [ether] PERM on flannel.1
# Determine the container ID of the Flannel container and obtain a shell within the container.
$ docker ps | grep flannel
ee112410bd61 4e9f801d2217 "/opt/bin/flanneld -…" 8 hours ago Up 8 hours k8s_kube-flannel_kube-flannel-ds-amd64-2qqld_kube-system_bc079a14-d045-44ce-9dc2-fa1369a20c30_0
11eee23ddcb0 k8s.gcr.io/pause:3.6 "/pause" 8 hours ago Up 8 hours k8s_POD_kube-flannel-ds-amd64-2qqld_kube-system_bc079a14-d045-44ce-9dc2-fa1369a20c30_0
$ docker exec -it ee112410bd61 /bin/bash
# Bridge forwarding database information within the Flannel container on the minikube host. Irrelevant entries have been removed for brevity.
bash-5.0# bridge fdb show
d2:d8:a1:85:9e:38 dev flannel.1 dst 192.168.122.7 self permanent
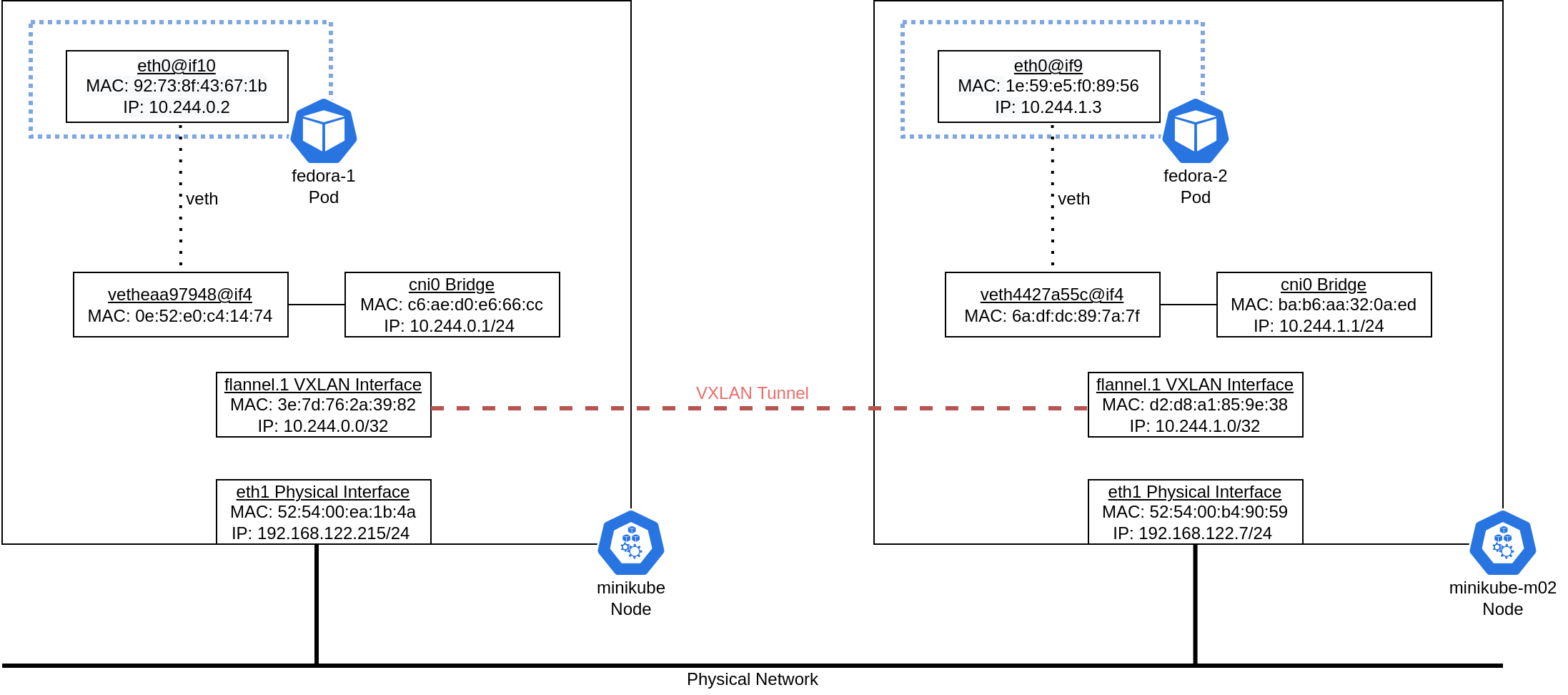
This additional information provides the overall traffic diagram for one side of the topology:
You can see the entire picture by viewing the configuration on the other side of the connection for the fedora-2 pod and the minikube-m02 node:
# MAC and IP addresses within fedora-2 pod
[root@fedora-2 /]# ip -br link sh
lo UNKNOWN 00:00:00:00:00:00 <LOOPBACK,UP,LOWER_UP>
sit0@NONE DOWN 0.0.0.0 <NOARP>
eth0@if9 UP 1e:59:e5:f0:89:56 <BROADCAST,MULTICAST,UP,LOWER_UP>
[root@fedora-2 /]# ip -br addr sh
lo UNKNOWN 127.0.0.1/8
sit0@NONE DOWN
eth0@if9 UP 10.244.1.3/24
# Peer interface within fedora-2 pod for veth
[root@fedora-2 /]# ethtool -S eth0
NIC statistics:
peer_ifindex: 9
# MAC and IP addresses on the minikube-m02 node
$ ip -br link sh
lo UNKNOWN 00:00:00:00:00:00 <LOOPBACK,UP,LOWER_UP>
eth0 UP 52:54:00:4b:22:10 <BROADCAST,MULTICAST,UP,LOWER_UP>
eth1 UP 52:54:00:b4:90:59 <BROADCAST,MULTICAST,UP,LOWER_UP>
sit0@NONE DOWN 0.0.0.0 <NOARP>
docker0 DOWN 02:42:df:f0:b5:92 <NO-CARRIER,BROADCAST,MULTICAST,UP>
flannel.1 UNKNOWN d2:d8:a1:85:9e:38 <BROADCAST,MULTICAST,UP,LOWER_UP>
cni0 UP ba:b6:aa:32:0a:ed <BROADCAST,MULTICAST,UP,LOWER_UP>
vethd63c7e02@if4 UP 96:ba:a1:c6:7c:b8 <BROADCAST,MULTICAST,UP,LOWER_UP>
veth4427a55c@if4 UP 6a:df:dc:89:7a:7f <BROADCAST,MULTICAST,UP,LOWER_UP>
$ ip -br addr sh
lo UNKNOWN 127.0.0.1/8
eth0 UP 192.168.61.149/24
eth1 UP 192.168.122.7/24
sit0@NONE DOWN
docker0 DOWN 172.17.0.1/16
flannel.1 UNKNOWN 10.244.1.0/32
cni0 UP 10.244.1.1/24
vethd63c7e02@if4 UP
veth4427a55c@if4 UP
# Peer interface on host for veth
$ ethtool -S veth4427a55c
NIC statistics:
peer_ifindex: 4
The complete traffic flow can now be understood at a high level: The pod sends traffic to its next hop, which is the CNI bridge on the host. The host forwards this traffic through the local flannel.1 interface to the flannel.1 interface on the remote node. This traffic is encapsulated in a VXLAN tunnel. It is decapsulated and forwarded to the target pod once the remote node receives it:
Communication on the wire
Now that you understand how the network stack works, it's time to see it in action. The best way to take this knowledge from conceptual to concrete is to send traffic between the pods and observe the traffic on the wire.
To do this, I set up a ping between fedora-1 and fedora-2 while running a Wireshark packet capture on the physical network. In my setup, minikube runs on a Linux host, which requires capturing packets on the virtual network interface controllers (NICs) for the minikube VMs. With the packet capture running, I set up a ping from fedora-1 to fedora-2:
[root@fedora-1 /]# ping 10.244.1.3
PING 10.244.1.3 (10.244.1.3) 56(84) bytes of data.
64 bytes from 10.244.1.3: icmp_seq=1 ttl=62 time=0.301 ms
64 bytes from 10.244.1.3: icmp_seq=2 ttl=62 time=0.771 ms
64 bytes from 10.244.1.3: icmp_seq=3 ttl=62 time=0.762 ms
Once I had captured some packets, I used Wireshark to analyze them. Notice that the communication appears as plain User Datagram Protocol (UDP) traffic, not Internet Control Message Protocol (ICMP) traffic. This is because it is encapsulated in the VXLAN tunnel.
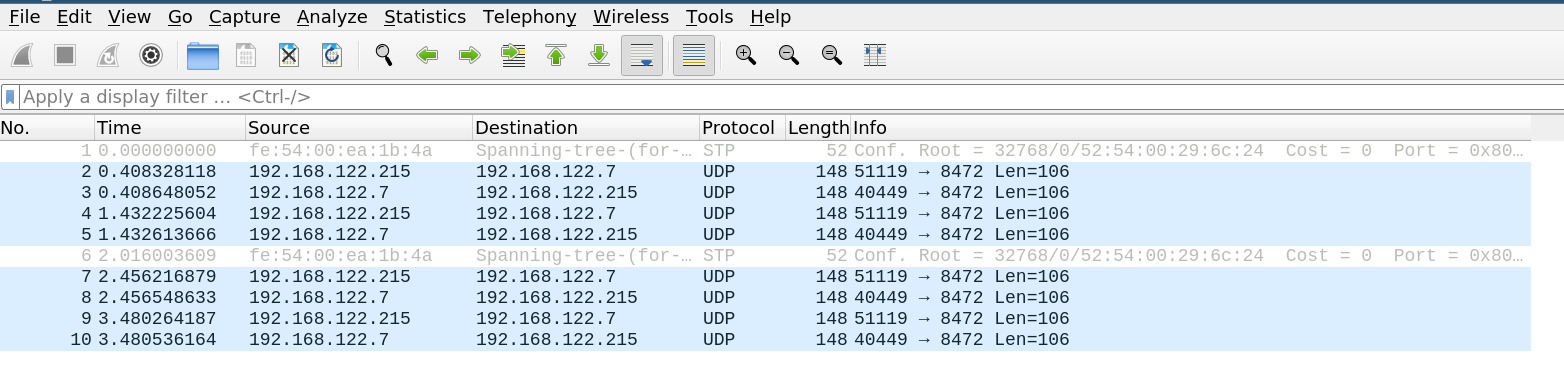
You can tell Wireshark to decode the traffic as VXLAN traffic by right-clicking on any traffic, selecting Decode As…, and specifying VXLAN as the current protocol for UDP port 8472 (the port the VXLAN tunnel uses):
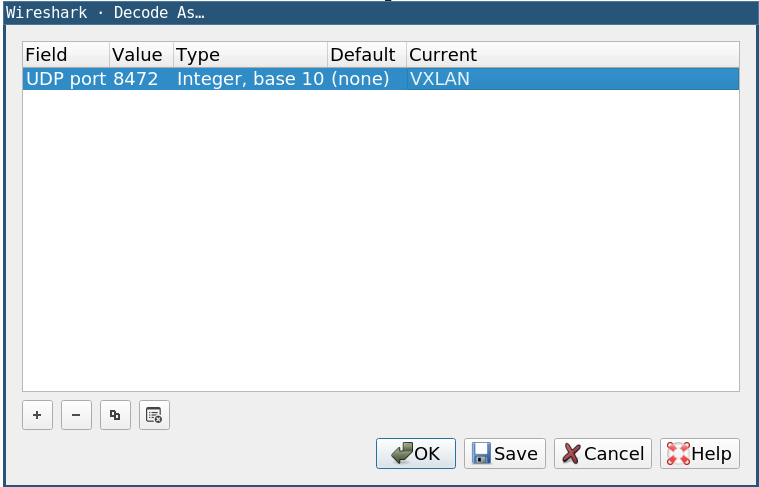
Once you set the decoding correctly, the traffic will appear as ICMP traffic. Expanding a particular packet shows the complete picture:

I will start at the innermost part of the packet. This is an ICMP packet being sent from 10.244.0.2 (fedora-1) to 10.244.1.3 (fedora-2). The innermost Ethernet header specifies a source MAC address of 3e:7d:76:2a:39:82 (flannel.1 on minikube) and a destination MAC address of d2:d8:a1:85:9e:38 (flannel.1 on minikube-m02).
Next, you can see a VXLAN Network Identifier of 1, which corresponds to the configuration you previously saw for the flannel.1 interface. This is the VXLAN header, which enables the overlay part of this network. The inner traffic is encapsulated within this VXLAN header, and the pods that communicate with each other don't know anything about the physical network topology.
Moving up the stack, you can see that this is a UDP packet sent from 192.168.122.215 (eth1 on minikube) to 192.168.122.7 (eth1 on minikube-m02). The MAC addresses are also sent from 52:54:00:ea:1b:4a (eth1 on minikube) to 52:54:00:b4:90:59 (eth1 on minikube-m02) because these minikube nodes are on the same physical network.
These packets demonstrate the entire flow of traffic from the fedora-1 to fedora-2 pods. Traffic is encapsulated with a VXLAN header and then sent directly between the two minikube nodes. When a node receives the traffic, it removes the VXLAN header and then forwards the inner packet to the appropriate pod. This allows full end-to-end communication between the pods without needing them to understand the underlying physical network.
Wrap up
This article showed how a packet travels from one Kubernetes pod to another through a VXLAN overlay network. This process is very complicated, and this article provided the in-depth commands necessary to fully trace this traffic flow. While Flannel is only one example of a Kubernetes network plugin, the general commands and concepts from this article can help you to understand traffic flows in Kubernetes clusters that use different network approaches.
About the author
Anthony Critelli is a Linux systems engineer with interests in automation, containerization, tracing, and performance. He started his professional career as a network engineer and eventually made the switch to the Linux systems side of IT. He holds a B.S. and an M.S. from the Rochester Institute of Technology.
More like this
Can't patch fast enough? Zero trust as a last line of defense
What's new with image builder for Red Hat Enterprise Linux 10.2 and 9.8
Container Roundup | Compiler
The Containers_Derby | Command Line Heroes
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds