
Our IBM CIO Hybrid Cloud team released a new hybrid cloud infrastructure that uses state-of-the-art features. We're running Red Hat OpenShift, we are leveraging public cloud services, and we streamlined connections between environments and platforms to allow teams to apply these hybrid cloud benefits to their applications.
[ Ask these 4 essential cloud project questions to put your current cloud results to work on planning your next cloud project. ]
Quality testing is done, the platform is released for general availability to our application teams, and everything is looking great—or so we thought.
Migration isn't necessarily adoption
Now that the platform was available for use, it was time to start getting teams thinking about migrating from legacy environments to our hybrid cloud. There is documentation available about the platform, features, and how applications can be run in the new environment. Application teams showed interest and teams began looking at what they needed to do to migrate to the new environment.
Many began to containerize their applications—some were taking advantage of Source-to-Image (S2I), some were using Dockerfiles, and others were uploading their image with their own continuous integration/continuous development (CI/CD) pipeline directly to the platform. This is what we were hoping for—we were getting modernization along with migration and setting ourselves up for a great future.
But we started noticing something that needed to be addressed. Teams were modernizing their applications, they were moving to the new platform, but they were not taking full advantage of the platform's capabilities. Their applications were modernized, running in stateless containers, but they were only running one copy of their application—in one zone, in one region.
[ Learn how to build a flexible foundation for your organization. Download An architect's guide to multicloud infrastructure. ]
Old habits die hard
We noticed that for some applications that don't need a high level of uptime or can tolerate an outage, teams were using the architecture as they had in their legacy environment: one instance of their application in one location. When their application went down, the support team fixed it within their service level agreement (SLA) window. However, the new hybrid cloud platform is designed to run multiple copies of the application in multiple zones and multiple regions, which provides the following benefits:
- Multizone capability allows us to run multiple copies of the applications across different datacenters spread across a single region. For example, in the US-South region, the platform is spread across three separate datacenters. This protects against a single datacenter's failure.
- Multiregion capability allows us to run multiple copies of the applications across multiple regions. For example, running the applications in the US-South region and in the US-East region protects against failure in an entire region due to a natural disaster.
Even though these application teams know about these possibilities, they saw no need to leverage them. They had operated this way before, and they brought that thinking with them to the new environment. It was time to provide some opinionated guidance on how applications should be run in the new platform.
[ Modernize your IT with managed cloud services. ]
Architectural guidelines as learning tools
We began thinking of ways to influence the application teams so that they could take advantage of the hybrid cloud's built-in load balancing and multizone design.
We started looking at application data and use cases and came up with guidelines that would apply to the majority of applications they were migrating and modernizing.
We started with the basic design of a three-tier architecture (presentation, logic, data) and built on that. We laid out exactly how application teams could take advantage of the platform's multizone capabilities. Our minimal recommendation was for the application teams to deploy an active-active frontend of their application and an active-passive backend (databases), all within a single region. You can see an example of this pattern in the diagram below.
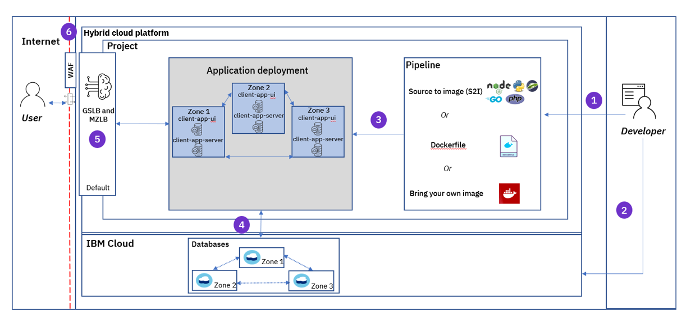
We wanted to enable a mindshift for the application developers who were deploying applications in the legacy platforms but are now migrating to a more modern platform with additional capabilities. The capability of deploying an application in multiple zones is a classic example. A failure of one instance of the application will not cause a total failure of the application with extended downtime; instead, another instance of the application will continue to provide the service.
We provide an easy way for an application developer to choose the number of application instances to deploy. If the number selected is more than one, then the platform automatically deploys a separate instance of the containerized application in different zones within the region and automatically provides a load balancer in front of it. This platform capability provides business continuity for the application in a manner that is not possible in legacy platforms, and we enable the application developers to leverage it.
The next guideline we created to build on top of this scenario was a high availability/disaster recovery (HA/DR) implementation. By explaining how it could be achieved, application teams weren't creating it from scratch when they began the migration process.
Our most complete guide contained multizone, multiregion, data backups and offsite replication, and environments that could be used for disaster recovery (shown in the diagram below).
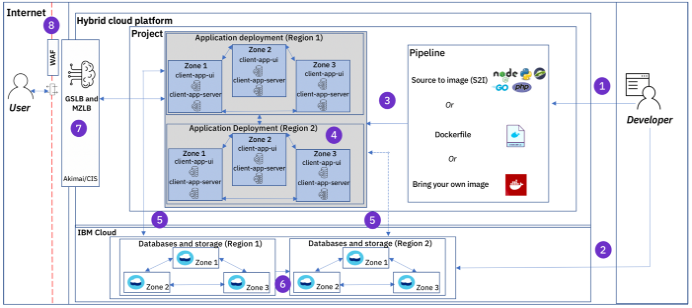
The goal with this guideline was to prove what is achievable on the new platform and how even the applications with the strictest requirements can build and run on our new platform.
Opportunities and options, not mandates
One important thing regarding these guidelines is that application teams do not have to follow our recommendations; they can do whatever they need for their requirements. But what the guidelines do offer is ease of transition, a method to help teams take a step back and reevaluate how they are deploying their current application, and what could be done in the platform.
[ Learn best practices for implementing automation across your organization. Download The automation architect's handbook. ]
Having the documentation is great, but once we put it all together with visual representations, along with links to guides on how it was implemented, what to watch out for, and where to go, the migration process became a lot smoother for teams.
The scenarios listed above may not work for every team and every application, but they do help alleviate some pressure on the platform team and the Center of Excellence (CoE) for a majority of cases. Most importantly, the application teams are now learning how to take advantage of the benefits when using a modern hybrid cloud infrastructure.
This article is based on Producing architectural guidelines to help teams make their migration plans co-authored with Kevin O'Shea on Hybrid Cloud How-tos and is republished with the CIO Hybrid Cloud team's permission.
About the author
Gina is a hybrid cloud program manager that's passionate about innovation, customer collaboration, and problem-solving.
More like this
Red Hat Learning Subscription Course reimagines virtual training
Red Hat Learning Subscription Course: Skills for the future
Untangling Networks | Compiler
What Are Tech Hiring Managers Looking For? | Compiler
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds