



In our group's previous articles, we presented the 5G Open HyperCore architecture, using Kubernetes for edge applications, improving container observability with a service mesh, and comparing init containers in Istio CNI. In this article, we're focusing on the 5G technology stack's scalability.
We are using Kubernetes constructs (ReplicaSets, metrics-driven pod autoscaling, and more) together with multicluster management facilities introduced through the Kubernetes API and the Open Cluster Management project from the Cloud-Native Computing Foundation (CNCF).
We have tested and verified the solution architecture and design paradigms presented in this article in our testbed running on hyperscaler infrastructure with Kubernetes as a default 5G platform. We've also leveraged a market-available 5G toolbox to load the test deployment to observe our scalability design's outcomes.
Finally, we've recorded a walkthrough of this project, which you can view at the bottom of this article.
[ Learn why open source and 5G are a perfect partnership. ]
The architecture
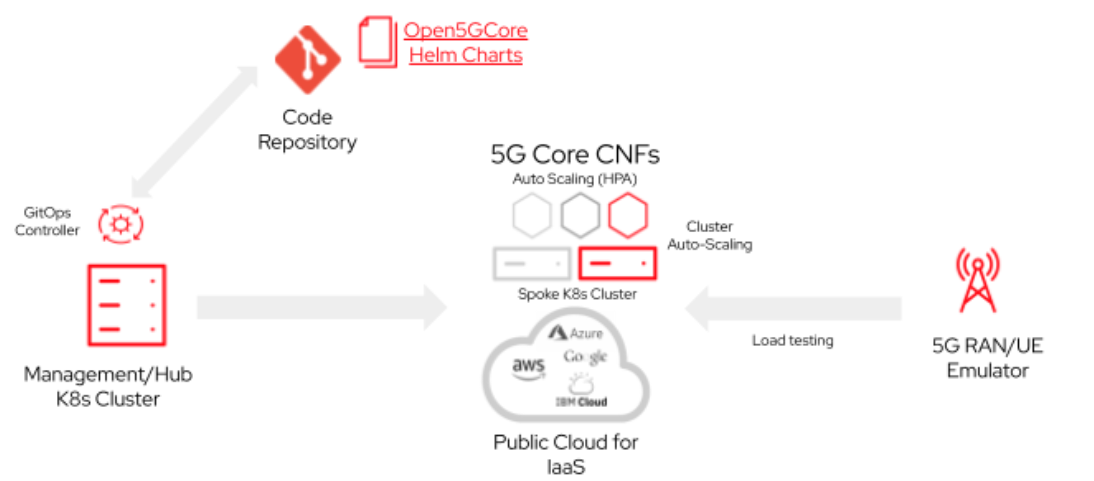
The solution and verification architecture is comprised of:
- Source repo: This repository serves as a single source of truth for the 5G software stack. We leveraged the Open5GS project with a custom Git repository to automatically deploy, sync, and prevent deployment and configuration drift.
- Management and hub cluster: This is the platform where cluster management facilities are hosted to create, edit, maintain, and delete the targets and spokes of Kubernetes clusters. This is broadly called cluster lifecycle management.
- Public cloud: In our testbed, we used a hyperscaler's infrastructure-as-a-service (IaaS). This is automatically created, configured, and used by a Kubernetes cluster manager from the hub-cluster.
- Managed cluster: This is a 5G application platform where a 5G cloud-native network function (CNF) is deployed. This is also called the "spoke" Kubernetes cluster.
- 5G CNF with service mesh: We leveraged an Istio-based open source service mesh for observability and to direct traffic.
- 5G RAN/UE emulator: We leveraged a market-available toolbox for the radio access network (RAN) and user plane (UP) of the testbed setup.
Design and verification paradigms
Resource usage metrics, such as container CPU and memory usage, are available in Kubernetes through the metrics API. They can be used externally as well as internally through Kubernetes' capabilities including pod autoscaling.
- Average CPU usage is reported in CPU cores over a period of time. This value is derived by taking a rate over a cumulative CPU counter, which is provided by the kernel. The kubelet chooses the window for the rate calculation.
- Memory is reported in bytes as a working set at the moment the metric was collected. In an ideal world, the "working set" is the amount of memory in use that cannot be freed under memory pressure. However, calculating the working set varies by host operating system (OS) and generally makes heavy use of heuristics to produce an estimate. The metric includes all anonymous (non-file-backed) memory because Kubernetes does not support swap. The metric typically also includes some cached (file-backed) memory, because the host OS can't always reclaim those pages.
HorizontalPodAutoscaler
According to the Kubernetes docs:
"In Kubernetes, a HorizontalPodAutoscaler (HPA) automatically updates a workload resource (such as a Deployment or StatefulSet), with the aim of automatically scaling the workload to match demand.
"Horizontal scaling means that the response to increased load is to deploy more pods. This is different from vertical scaling, which for Kubernetes would mean assigning more resources (for example, memory or CPU) to pods that are already running the workload.
"If the load decreases, and the number of pods are above the configured minimum, the HorizontalPodAutoscaler instructs the workload resource (the Deployment, StatefulSet, or other similar resource) to scale back down."
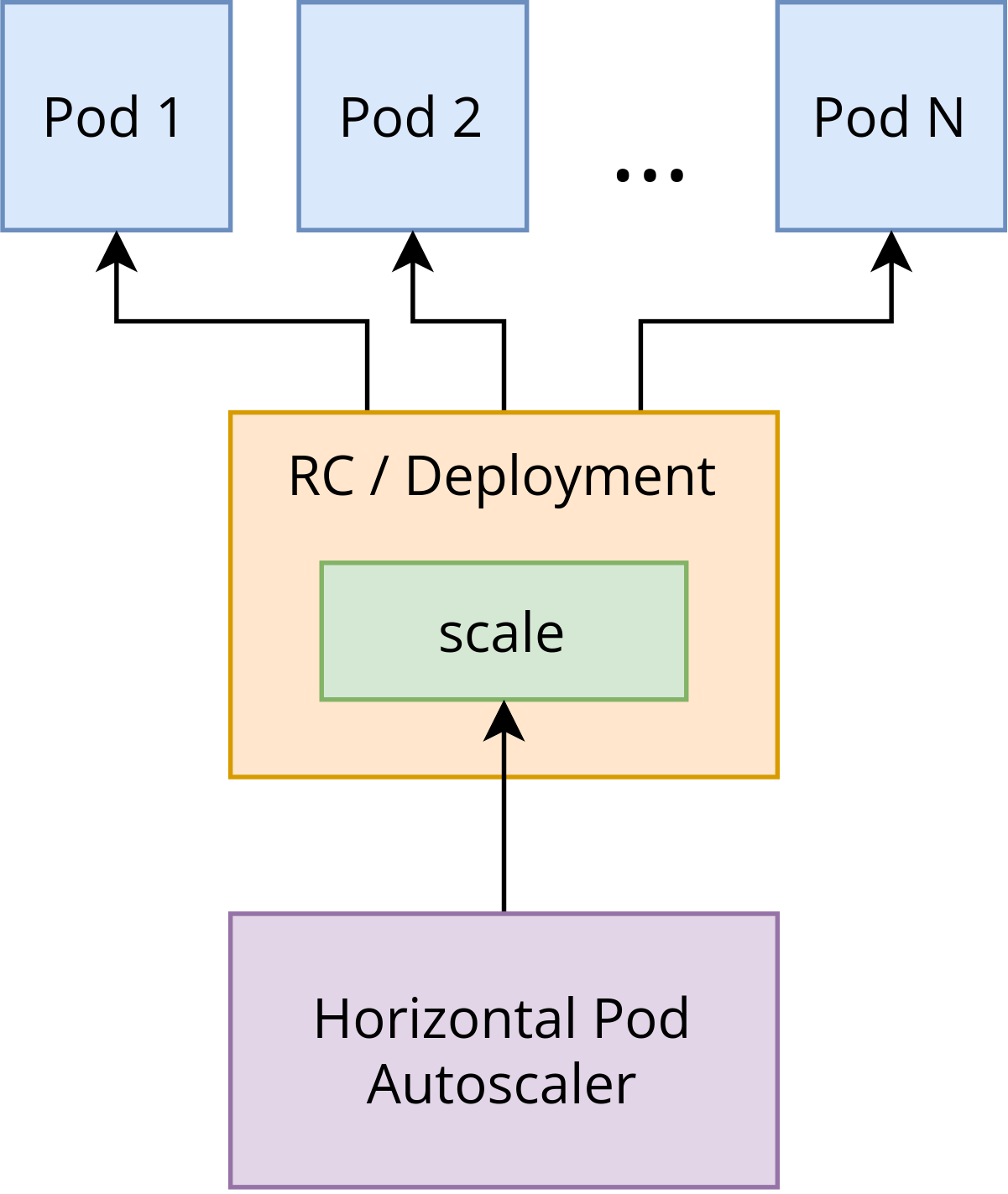
The HPA is implemented as a Kubernetes API resource and a controller. The resource determines the behavior of the controller. The HPA controller running within the Kubernetes control plane periodically adjusts the desired scale of its target (for example, a Deployment) to match observed metrics. This includes average CPU utilization, average memory utilization, or any other custom metric you specify from the metrics API.
[ Boost security, flexibility, and scale at the edge with Red Hat Enterprise Linux. ]
Vertical Pod Autoscaler
According to the Kubernetes Autoscaler docs:
"Vertical Pod Autoscaler (VPA) frees the users from necessity of setting up-to-date resource limits and requests for the containers in their pods. When configured, it will set the requests automatically based on usage and thus allow proper scheduling onto nodes so that appropriate resource amount is available for each pod. It will also maintain ratios between limits and requests that were specified in initial containers configuration.
"It can both down-scale pods that are over-requesting resources, and also up-scale pods that are under-requesting resources based on their usage over time."
Cluster Autoscaler (CA)
According to the Kubernetes Cluster Autoscaler docs:
"Cluster Autoscaler is a standalone program that adjusts the size of a Kubernetes cluster to meet the current needs.
"Cluster Autoscaler increases the size of the cluster when:
- There are pods that failed to schedule on any of the current nodes due to insufficient resources.
- Adding a node similar to the nodes currently present in the cluster would help.
"Cluster Autoscaler decreases the size of the cluster when some nodes are consistently unneeded for a significant amount of time. A node is unneeded when it has low utilization and all of its important pods can be moved elsewhere."
The last statement depends on whether pod placement allows the pods to be moved.
Test approaches: 5G control plane (CP) and 5G user plane (UP)
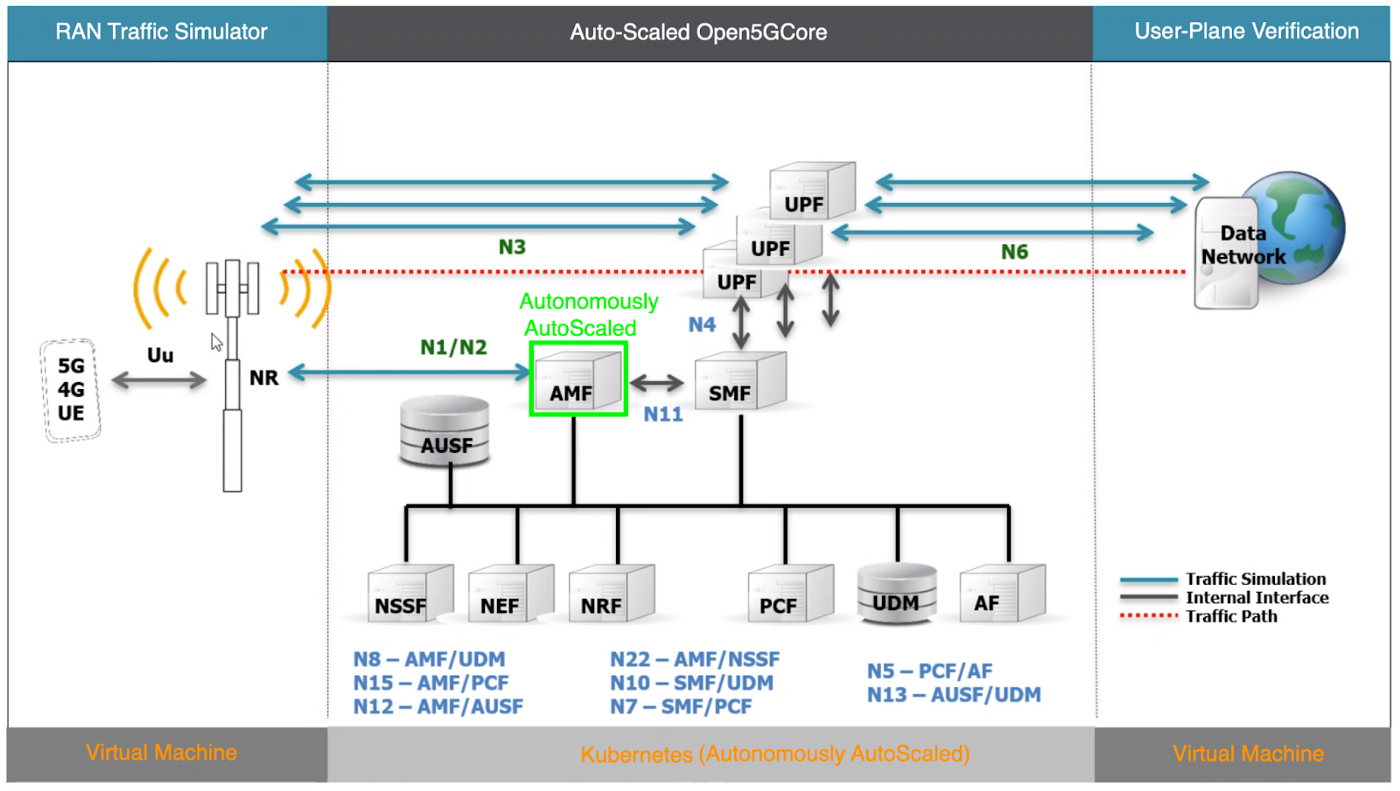
As shown in the figure above, we emulated the RAN side as well as used a user-plane verification for the system-under-test (SUT) verifications.
- RAN-side emulation generates a 5G next-generation NodeB (gNB) attachment as well as user equipment (UE) registration traffic towards 5G Core CNFs deployed on the Kubernetes platform that runs on the hyperscaler infrastructure.
- The user plane-side verification ensures that the attached UEs have an internet break-out over 5G Core and also creates additional load and stress for CNFs.
Note: The Emblasoft evolver product is used to emulate 5G devices and radio access gNBs, and to generate load traffic to trigger the cluster autoscaler functionality. We are grateful to Emblasoft for their partnership and collaboration in this work.
Verification results
We leveraged an open source service mesh, not only because it is really cool, but it also allows us to visualize the traffic distribution in near real time. We can see how north-south 5G traffic creates an impact on east-west backend traffic with associated 5G CNFs.
The snapshot below was taken from the initial 5G gNB registrations phase and presents 5G CNF interactions among themselves. It also shows the ingress and egress to and from the Kubernetes cluster where the deployment domain is an Open5G Core namespace.
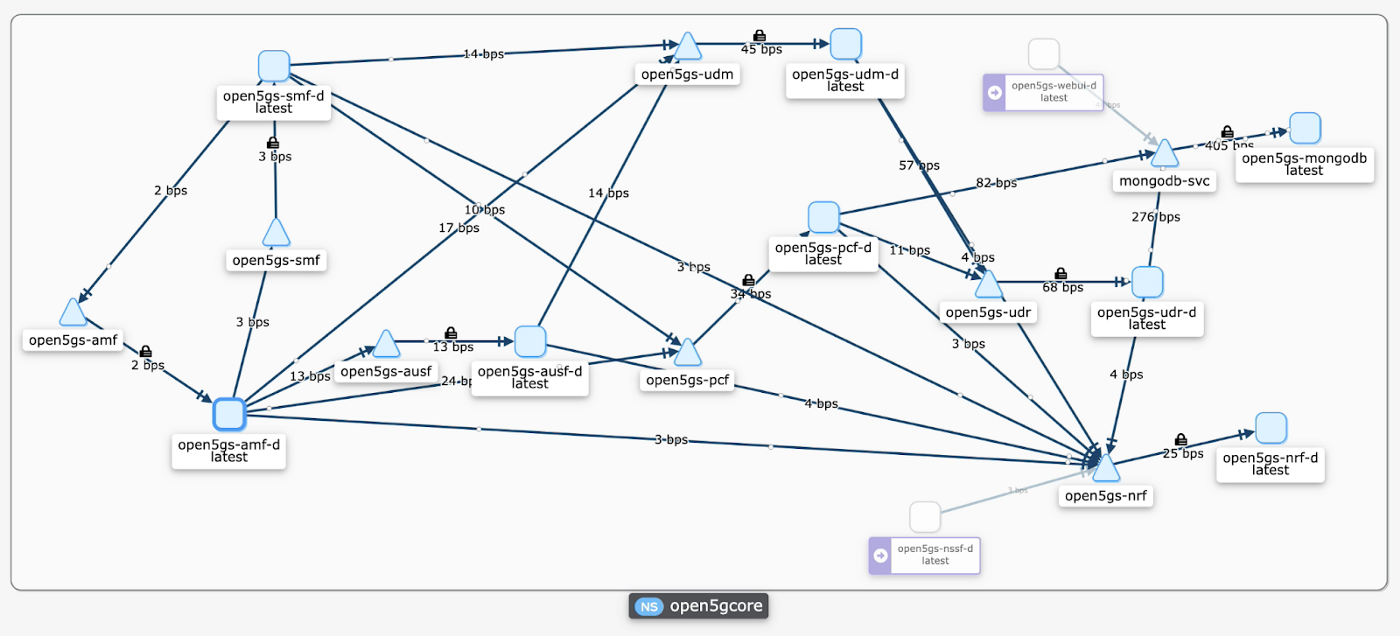
When we loaded the RAN side traffic on 5G, CNFs and CPU utilization reached and passed the configured scaling threshold. HPA triggered an autoscale of the Access and Mobility Management Function (AMF) pod count from one to two.
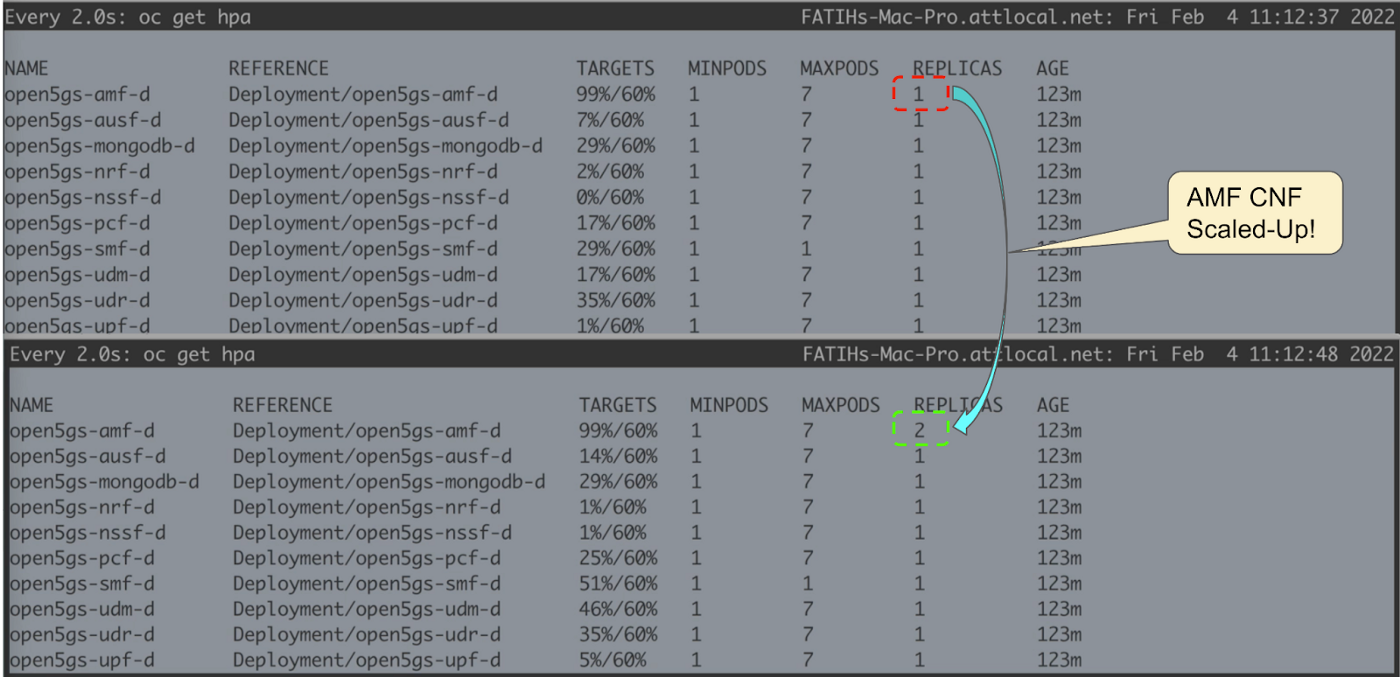
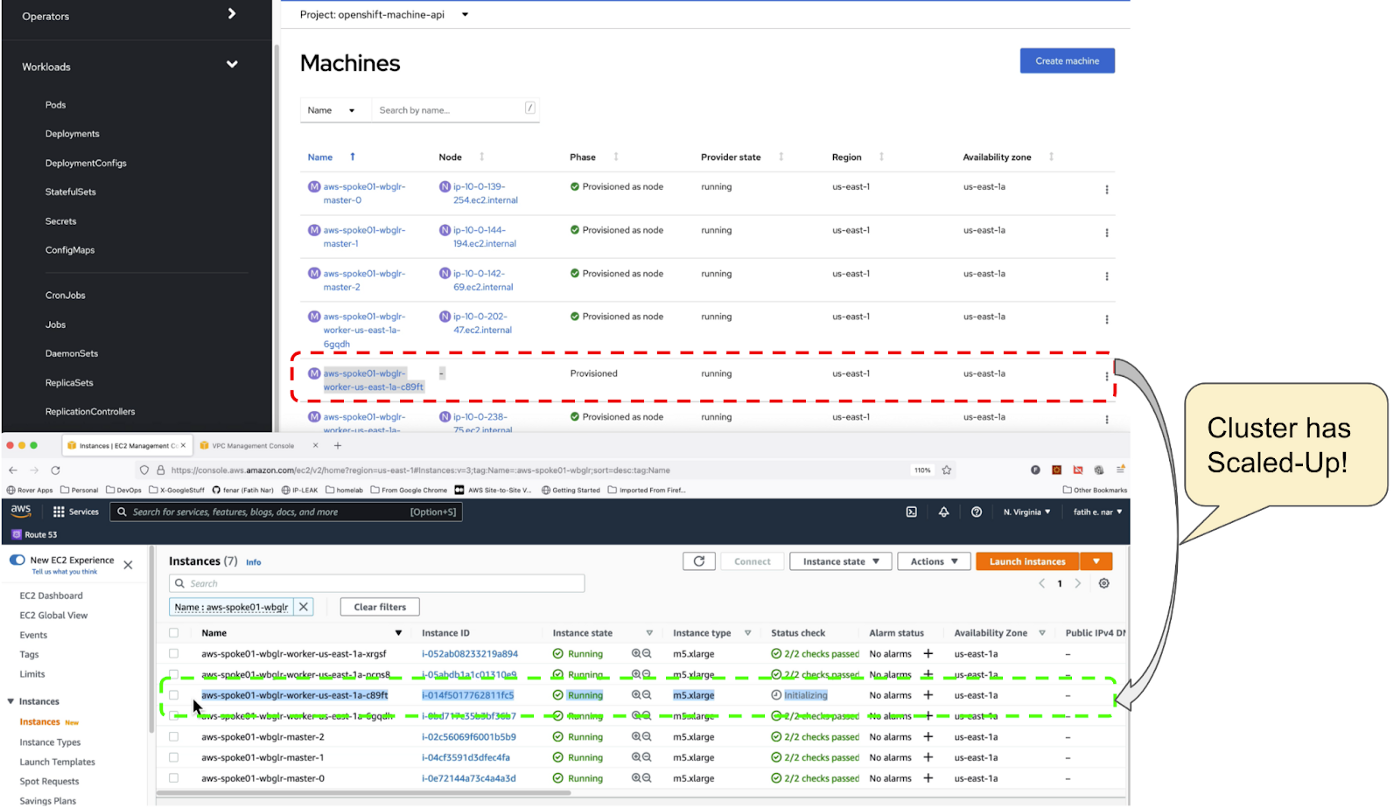
However, as the cluster was under heavy load and usage, a new AMF CNF pod had to wait for the cluster worker pool to scale up, after which a new AMF CNF pod came into service through NodePort service exposure.
Challenges and solutions
Here are four challenges we've seen in deployments and how we manage them:
1. Choosing HPA or VPA for the 5G stack
Updating running pods is an experimental VPA feature. Whenever VPA updates a pod resource, the pod is recreated. This causes all running containers to restart. A pod might be recreated on a different node, potentially resulting in a 5G service outage. By itself, this was enough for us to choose HPA.
2 Cluster scaling the 5G workload
HPA changes the Deployment's or ReplicaSet's number of replicas based on the current CPU load. Should the load increase, HPA creates new replicas, for which there may not be enough space in the cluster. If there are not enough resources, then the CA tries to bring up some nodes so that the HPA-created pods have a place to run. Should the load decrease, HPA stops some of the replicas. As a result, some nodes may be underutilized or become completely empty, prompting CA to delete unneeded nodes.
Best practices for running CA include:
- Do not modify nodes manually. Doing so causes configuration drifts and breaks uniform resource availability. All nodes within the same node group should have the same capacity, labels, and system pods running on them.
- Explicitly specify requests for your pods and use PodDisruptionBudgets to prevent pods from being deleted.
- Verify that your cloud provider's quota is big enough before specifying minimum and maximum settings for your node pools.
- Avoid running additional node group autoscalers (especially those from your cloud provider) that would cause your quota to be exhausted for no good reason.
3. Smart workload scheduling and disaster-free scaling
Leveraging GitOps on Day 0, and even Day 1 and 2, can help prevent drifted configuration (or "snowflake") cases in your workload deployment and configuration.
Management-Hub accommodates Cluster-Management and also provides a GitOps operator from where you can initiate workload deployments and configuration management centrally. Here is a handy Gist to add spoke clusters to a central ArgoCD deployment.

While your workload accommodates variable traffic patterns, your CA adopts the cluster size based on utilization levels. However, you need to make sure that there is no 5G service degradation due to moving critical CNFs to other nodes. This is also true with pod termination and recreation.
[ For a practical guide to modern development with Kubernetes, download the eBook Getting GitOps. ]
In this example YAML, the cluster-autoscaler.kubernetes.io/safe-to-evict property is set to false to prevent scale-down for nodes hosting critical pods:
apiVersion: apps/v1
Kind: Deployment
metadata:
name: open5gs-amf-d
labels:
epc-mode: amf
spec:
selector:
matchLabels:
Epc-mode: amf
template:
metadata:
annotations:
cluster-autoscaler.kubernetes.io/safe-to-evict: "false"4. Arrange and form Kubernetes networking for 5G
Telco workloads are rather special in the sense that they network among themselves (east-west) as well as to and from consumers (north-south). One of the inherited legacy communication protocols is stream control transmission protocol (SCTP), which needs to be added to the firewall and security group rules so that SCTP traffic can reach destined pods.
In our initial tests, we noticed that the Kubernetes NodePort service exposure was not working well with SCTP:
[2022-02-11 21:12:01.976] [sctp] [info] Trying to establish SCTP connection...
(10.0.152.182:30412) terminate called after throwing an instance of 'sctp::SctpError'
what(): SCTP socket could not be createdWe had to pinpoint the exact node where the AMF CNF landed so that gNB and UE registrations coming from outside could reach AMF and receive a response.
Later, we found that the issue's root cause was a missing explicit network policy for SCTP. This was necessary for traffic to be distributed between worker nodes and nodes with AMF CNF:
apiVersion: v1
kind: Service
metadata:
name: amf-open5gs-sctp
labels:
epc-mode: amf
spec:
type: NodePort
selector:
epc-mode: amf
ports:
- protocol: SCTP
port: {{ .Values.cnf.amf.sctp.port }}
targetPort: 38412
nodePort: {{ .Values.cnf.amf.sctp.nodeport }}Notice the SCTP specifications in the ports section. These are echoed in the NetworkPolicy:
---
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
name: allow-sctp
spec:
podSelector:
matchLabels:
epc-mode: amf
ingress:
- ports:
- protocol: SCTP
port: {{ .Values.cnf.amf.sctp.port }}|If you have issues with traffic distribution within Kubernetes with service exposures, this Gist may guide you to find some clues.
Conclusion
We wanted an autonomous 5G Core platform that scales up or down under traffic based on user demand. We found that this also optimizes operating expenses for infrastructure costs with no sacrifice to user experience.
Although Kubernetes is a mature application platform, there are many knobs and controls to consider based on the workload and complexity of what you're setting up. Especially on the networking side of things, the IaaS platform brings even more knobs and dials into the solution configuration, making an ops team's work more complex.
We sincerely believe that purpose-built and verified industrial solution blueprints can accelerate industry adoption of microservices and cloud computing as a whole. This can accelerate the time for new ideas to reach the market and lower the risk of cloud adoption. Platform software companies working closely with hyperscalers are making this a reality.
Watch a demo of this project:
About the authors
Anca Pavel is a results-oriented Technical Account Manager with experience in telecom, support, and software development. Over the course of her career, she has demonstrated a strong ability to interface with key business units to assess business needs and develop solutions that further corporate goals. Her professional background includes the ability to build solid, long-term client relationships.
Fatih E. Nar, has built a career by solving complex challenges in various domains including telecom, entertainment, media, and others.
With experiences at Google, Verizon Wireless, Canonical Ubuntu, Ericsson, and now Red Hat, he specializes in cloud native and data- and AI-driven solutions for enterprises and service providers.
His work blends AI, cloud, and high performance networked computing to create efficient and scalable software-driven solutions.
He holds an MSc in Information Technology and a BSc in Electronics Engineering, along with completed AI studies at MIT and Stanford, and has been admitted to Purdue University for a doctorate program for Spring 2026.
Fatih is also a recognized writer, sharing insights through his Open xG HyperCore series on Medium and contributing to AI/ML projects on GitHub and Hugging Face.
In 2025, Fatih was elected as a subject matter expert on AI/ML within Linux Foundation Networking (LFN) organization to steer and lead AI initiatives.
When not working, he’s likely exploring new datasets and AI models, ctl’ing with k8s, or sneaking dad jokes into tech discussions.
Federico Rossi is a Sr. Specialist Solutions Architect at Red Hat, with professional experience in the design, development, integration, delivery, and maintenance of carrier-grade voice/data networks and services for Telco operators worldwide. Federico focuses on helping partners and customers architect 5G RAN, O-RAN, 5G Core, and Edge/MEC solutions on hybrid clouds leveraging Red Hat Open Source technologies.
Mathias is a passionate and results-oriented leader. In his role as chief architect at Emblasoft, a global provider of service enablement, active monitoring, load and functional test solutions for 5G, VoLTE, 4G, 3G, and IMS infrastructure, he has been involved in larger customer projects in the area of software and test development and automation, as well as analysis of Mobile Core Networks leveraging virtualization technology, OpenStack, and Kubernetes.
At Emblasoft, Mathias helps customers innovate and drive the evolution of their networks. Prior to becoming a partner at Emblasoft, Mathias held positions at PureLoad and Ericsson as well as senior consultancy engagements with top Tier One operators. Mathias holds a BSc in Computer Engineering.
More like this
The value of unconventional experience: From sweeping hair to shaping careers
Can't patch fast enough? Zero trust as a last line of defense
Container Roundup | Compiler
Untangling Networks | Compiler
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds