
Today millions of users can be reading and writing data into applications in near simultaneity. The variety of such applications is broad, well beyond the traditional high volume scenarios typically found in banking and other financial applications. New approaches are needed.
One such approach is the Command Query Responsibility Segregation (CQRS) pattern.
Take the CQRS interactive tutorials on Katacoda
In addition to the information provided in this article, we’ve published a set of three tutorials on the Katacoda interactive learning environment that will help you understand the CQRS pattern at an operational level.
The Katacoda learning environment provides an interactive virtual machine where you can execute the commands and techniques described in the tutorials directly in a terminal window. The Katacoda environment allows you to learn by doing!
You can access the tutorials at the following links:
- Part 1-Examining a Single Source Database Architecture
- Part 2-Implementing the CQRS Pattern
- Part 3-Taking an Event-Driven Approach to CQRS
What is CQRS?
The Command Query Responsibility Segregation pattern is, as the name implies, a software design pattern that separates command activities from query activities. In CQRS parlance, a command writes data to a data source. A query reads data from a data source. CQRS addresses the problem of data access performance degradation when applications running at web-scale have too much burden placed on the physical database and the network on which it resides.
In the old days, before the emergence of ubiquitous computing brought about by the internet, having a single database be the single source for read and write activities in an application was a reasonable approach to data access. (See Figure 1, below.)
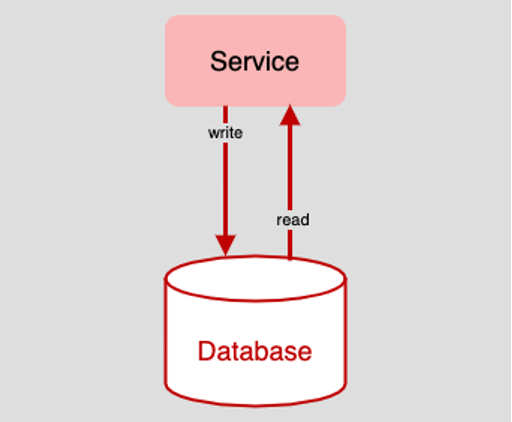
Figure 1: In the days before the commercialized internet, reading and writing data to a single database was commonplace
If performance started to degrade, you could always convert the single database into a database cluster and thus spread access activities across the cluster. However, as long as the cluster was exposed as a single point on the network, there was still the risk of high latency due to the bottleneck around that access point. All read requests (the query) and all write requests (the command) went to the same target.
The benefit that CQRS brings to data design is that it separates read and write behaviors in the application logically and physically. (See Figure 2, below)

Figure 2: The underlying principle of CQRS is to completely separate write activity from read activity within the underlying application architecture
In a single-source data design, one database is the target of both read and write activity. When the CQRS pattern is used, read and write activity is separated among a variety of data sources. Also, each data source can be a database technology that is best suited for the particular need. For example, the best technology for storing write data might be a relational database such as Postgres or even DB2 on a mainframe. On the other hand, should the forces driving read behavior have to do with displaying hierarchical data on an eCommerce site, for example, using a document database such as MongoDB to store read data and view it makes sense.
While following the CQRS pattern to separate write storage from read storage provides a high degree of flexibility and efficiency for applications operating at a web-scale, implementing the pattern comes with a fundamental challenge that needs to be addressed in any situation. The challenge is data synchronization.
Addressing the challenge of data synchronization
As mentioned above, essential to the concept of CQRS is the notion of separating read behavior from write behavior. Under CQRS, an application will save data to one distinct data source and read data from another. However, given that read and write data sources are separate and isolated from each other, CQRS only works if the data is consistent among all data sources. In other words, if I have an eCommerce application that adds an order object to the write database, the information in that order had better show up somewhere in the read database in an accurate and timely manner. If not, the entire application is at risk of offering up inaccurate data and, thus, not being of much value.
Ensuring data consistency among the entire array of database technologies in a CQRS architecture is essential. The questions then become not only, how do you do it but also, how do you do it well?
First, let’s take a look at the way that works but has an undesirable side-effect. Then, let’s look at a more optimal approach.
Avoiding a common mistake
One way to implement data consistency under CQRS is to create intelligence in the application to inspect an incoming request and apply CQRS logic accordingly. Figure 3 below shows an example of this idea.
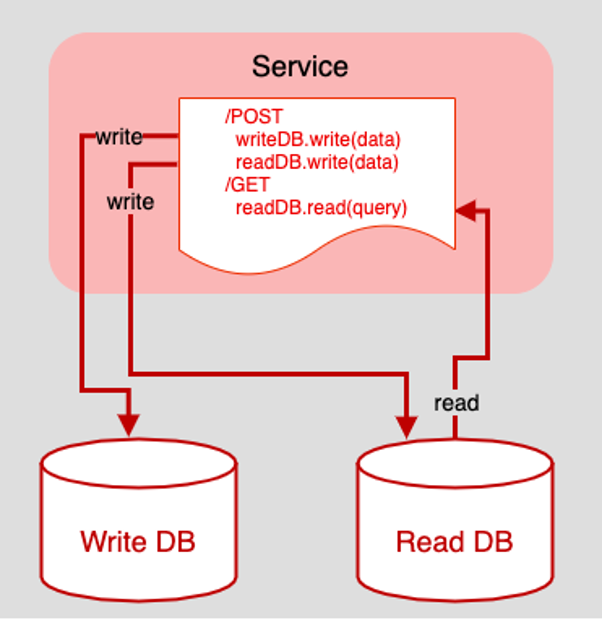
Figure 3: Putting data routing within the scope of an HTTP request creates a tightly bound architecture that will be difficult to refactor
Figure 3 above is an example of a fictitious API that supports read (a.k.a. query) behavior via an HTTP GET request on a single endpoint. Write (a.k.a. command) behavior is supported by an HTTP POST against that same endpoint.
When a read query comes in, the HTTP service retrieves the data from the Read database. However, when write data comes in via the POST request, things get a little more involved. The POST logic makes two writes, one to the Write DB as expected and one to the Read DB. Thus, data consistency among the data sources is achieved. That’s the good news. The bad news is that the technique has incurred risk and technical debt.
The biggest risk is one of transactional failure. There is an underlying assumption in play that the HTTP POST write activities that attempt to add data to both the Write DB and the Read DB are successful. As it stands in the Figure 3 code, there is no failure check on either write and no fallback behavior to save the incoming data on failure. Obviously, this problem needs to be addressed in order to have a viable implementation of CQRS. Yet, there is another problem, and this one is architectural.
Putting the logic for implementing CQRS directly in the web server makes the application brittle. A fundamental principle of application design is the clear separation of concerns. Putting CQRS logic in the web server violates the principle.
The concern of the web server is to accept and route requests onto relevant logic. The concern of CQRS is to separate read and write activities in the application’s data access framework. Mixing these two creates a technical debt level that will be hard to pay back when the time comes.
Thankfully, there is a better way.
Using event-driven data persistence
A better way to implement CQRS is to use the mediator pattern in conjunction with an event-driven data persistence architecture. Let’s start with the latter.
Event-driven data persistence is a technique in which events are raised in accordance with a given application’s purpose, and the data associated with the given event is consumed by interested parties. For example, at the conceptual level, let’s imagine that we have an eCommerce API that accepts orders. A user posts a request that has order information. The API receives the order information and packages it up into a structured message that describes an event, OnNewOrder, as shown below in Listing 1.
{
eventName: "OnNewOrder",
orderId: "8263341f-03e0-4b89-a7b1-81670142383d",
description: "Ceramic coffee cup",
quantity: 1;
firstName: "Bill",
lastName: "Jones",
email: "bill.jones@example.com"
}
Listing 1: An example of an event message
The API publishes that message to a message broker such as Kafka. Those parties interested in information around an OnNewOrder event consume that message and process it according to their purpose.
The value of using event-driven data persistence is that the technique creates a high degree of independence among the various data sources in play in a given application. Each component in an application does only what it’s supposed to do. There is no mixing and matching.
However, to support event-driven data persistence under CQRS, there still needs to be intelligence that can mediate read and write behavior for incoming requests. Also, because data will be dispersed throughout the application in a variety of asynchronous messages that correspond to particular events, there needs to be a mechanism to store all the data for all the events generated. This storage mechanism needs to store the data for a long time, on the order of years. This way, if things go awry and read and write data goes out of sync or the data in a data source is destroyed, a sole point of truth—the event store—can be used to reconstitute the system to the last known, good state.
Let’s take a look at how this works.
Taking an event-driven approach to CQRS
Figure 4 below illustrates a data architecture that implements CQRS using the mediator pattern. The first thing to notice is that all requests, both commands to add data to the application and queries to read data from the application, pass from the application’s web server onto a component named Mediator.
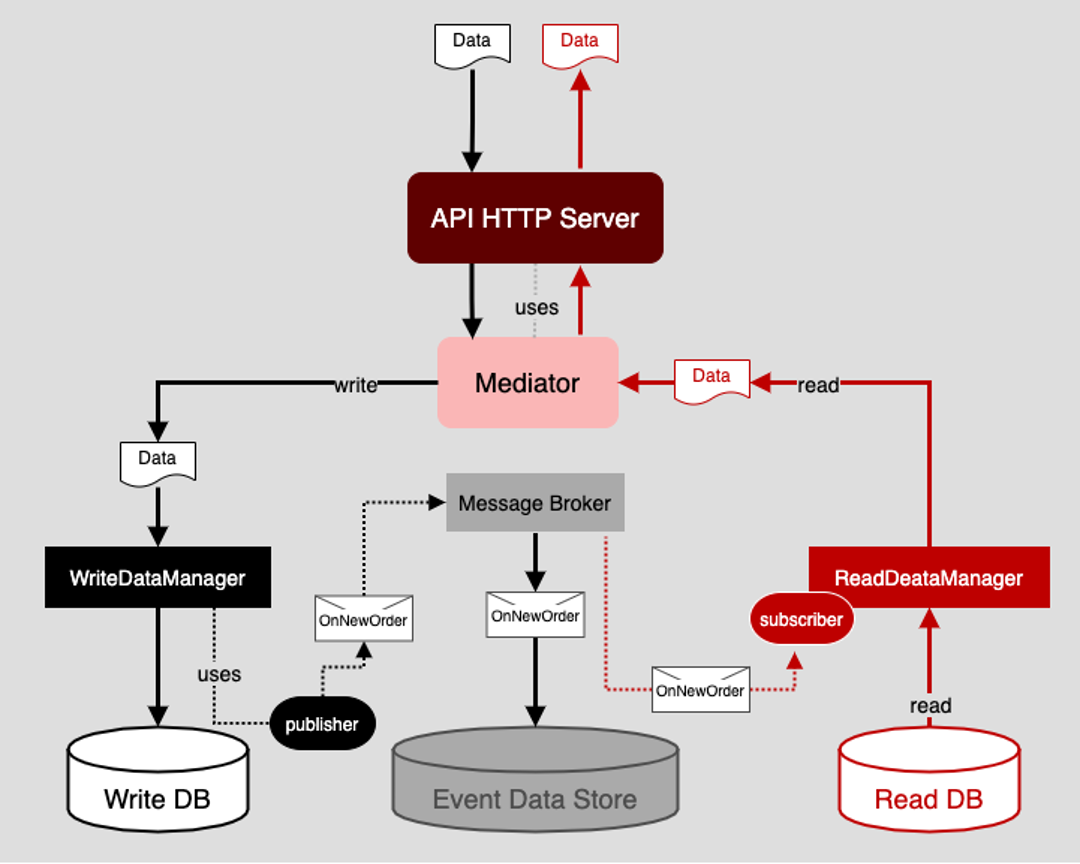
Figure 4: Using a Mediator in an event-driven architecture provides independence and flexibility
The purpose of the Mediator is to distinguish read and write requests and then route the request accordingly. If the request is a write command, that data is forwarded onto a component called a WriteDataManager. If the request is a read query, it is retrieved from a component called ReadDataManager.
The purpose of WriteDataManager is to connect to a write database and add the data in the request. Also, upon adding data to the write database, the WriteDataManager will publish an event, OnNewOrder, to a message broker to which it is bound. At this point, WriteDataManager has done its work. The actual consumption of the data associated with the OnNewOrder event is of no concern to WriteDataManager. Its job is to add data to its data store and generate an event when data is added.
When the message broker receives an OnNewOrder event message, it does two things. First, the message broker stores the data associated with the event in its internal event data store. This creates a permanent record of the event that can be used for audit and failure recovery purposes.
Second, the message broker passes the message to a message queue to which interested parties are subscribed. Interested parties consume the message and act on it according to their purpose.
In the case of the read data source, as mentioned previously, that functionality is represented by the component named ReadDataManager. ReadDataManager subscribes to a queue on the message broker to receive OnNewOrder event messages. When an OnNewOrder message is received, ReadDataManager saves the relevant information in the event message to its data store. At this point, both data as represented by both WriteDataManager and ReadDataManager is consistent. Thus, the intention of CQRS has been fulfilled in a way that is loosely coupled yet reliable and verifying between data sources.
Putting it all together
The Command Query Responsibility Segregation pattern is a valuable design technique that is well suited to applications that need to support a high volume of requests made against very big data sources. Separating read from write behavior improves system performance overall. And, it allows systems to scale up quickly when functionality or data structures need to be added. When used in conjunction with the mediator pattern, CQRS makes the system more flexible and easier to refactor.
However, while CQRS is powerful, it is not simple. Separating data according to purpose means that there is always a risk of compromised data consistency either due to varying degrees of latency on the network or episodic system failure. Thus, implementing CQRS using an event-driven data persistence architecture in which the system’s message broker can store every message received for a very long time is a sensible way to go.
CQRS can increase system performance and efficiency. The trick is to make sure that the underlying application architecture in which it is implemented is loosely coupled and can be reconstituted to the last known good state in the event of catastrophic failure.
About the author
Bob Reselman is a nationally known software developer, system architect, industry analyst, and technical writer/journalist. Over a career that spans 30 years, Bob has worked for companies such as Gateway, Cap Gemini, The Los Angeles Weekly, Edmunds.com and the Academy of Recording Arts and Sciences, to name a few. He has held roles with significant responsibility, including but not limited to, Platform Architect (Consumer) at Gateway, Principal Consultant with Cap Gemini and CTO at the international trade finance company, ItFex.
More like this
The value of unconventional experience: From sweeping hair to shaping careers
Meet the latest Red Hat OpenShift Superheroes
Container Roundup | Compiler
Untangling Networks | Compiler
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds