

In a previous article, How to measure and use network latency data to improve 5G user experience, we demonstrated the importance of latency for network service performance and user experience and its impact on business and the economy.

This article presents the engineering development for latency-driven service and application orchestration. The goal is to address the challenges with a well-crafted technical solution and harvest its benefits. It leverages the partnership between Red Hat and Ddosify.
[ Read Hybrid cloud and Kubernetes: A guide to successful architecture ]
Background
Kubernetes is the standard application platform used across industries. Using Kubernetes in a cloud-native way (reasonably sized, distributed, up-to-date ephemeral clusters) requires extensive cluster management capabilities to perform tasks, including:
- Lifecycle management (LCM) of Kubernetes cluster(s) on different infrastructure types with end-to-end visibility and control.
- Distribution, placement, and management of workloads (wherever, whenever, and however needed) from a single-pane view with the lifecycle, security, and compliance information required by legal and industry specifications.
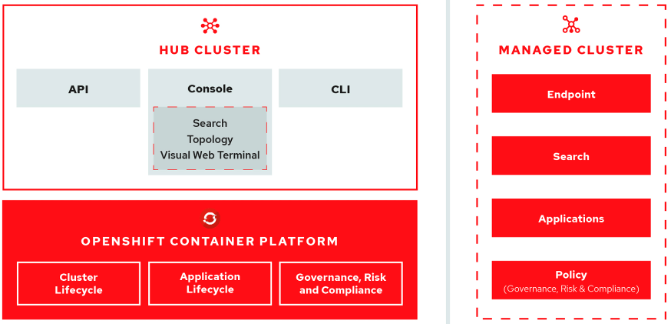
The open-cluster-management project addresses the challenges above with the following capabilities:
- Works across various application environments, including multiple data centers, private clouds, and public clouds that run Kubernetes clusters.
- Simplifies creating Kubernetes clusters and offering lifecycle management using a single pane.
- Enforces policies at the managed clusters using Kubernetes-supported custom resource definitions (CRD).
- Deploys and maintains Day 2 operations of applications distributed or placed across a fleet of clusters.
Red Hat develops and maintains these capabilities with an open source mindset and methodology. It also packages and hardens them for enterprise needs under the Red Hat Advanced Cluster Management (RH-ACM) product umbrella.
Solution and testing
Our solution blueprint leverages RH-ACM and basic Kubernetes constructs (such as label selectors) to implement latency-driven workload lifecycle management (scheduling, placement, continuous monitoring, and auto-migration) across multiple managed Kubernetes clusters.
[ Learn the basics; download the Kubernetes cheat sheet. ]
We created a new latency application placement operator to work with RH-ACM that performs three tasks:
- Integrates with the Ddosify latency API
- Automates latency measurement operations seamlessly
- Uses collected latency data for application scheduling
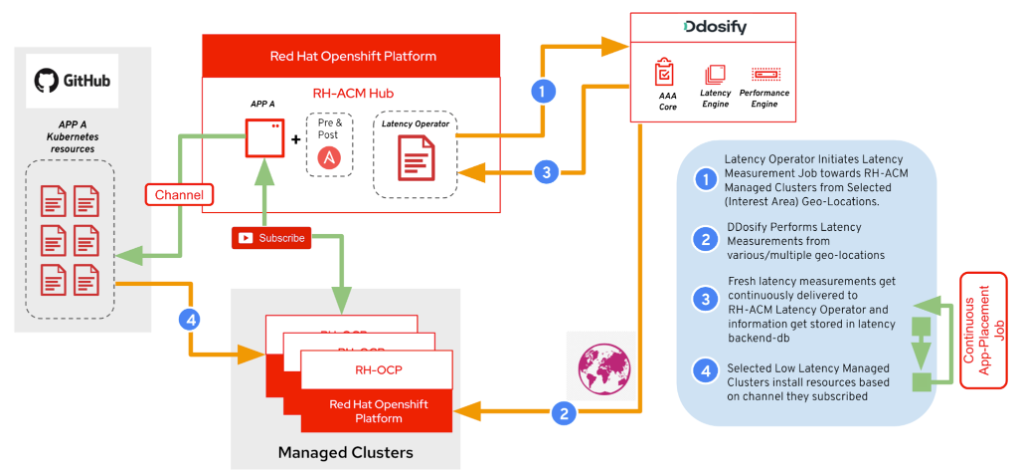
Breaking down the latency operator workflow depicted above:
- Install the latency operator on the RH-ACM Hub cluster and configure it with the desired point of origin per workload using location labels. The latency operator creates a latency measurement job on the Ddosify cloud (using the Ddosify Latency API).
- Ddosify cloud performs latency measurements from marked-down geolocation granularity (global, continent, country, state, city).
- Collected fresh latency data gets pushed or pulled from the Ddosify cloud to RH-ACM, and Latency Operator and Placement Rule lifecycle management run as depicted in the figure below.
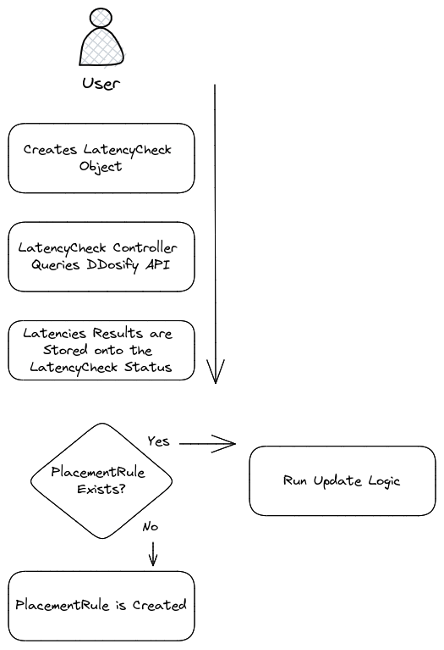
- Suppose the Placement Rule gets updated and the new destination is another cluster. RH-ACM schedules the application on the new low-latency cluster and removes the workload from the previously selected cluster.
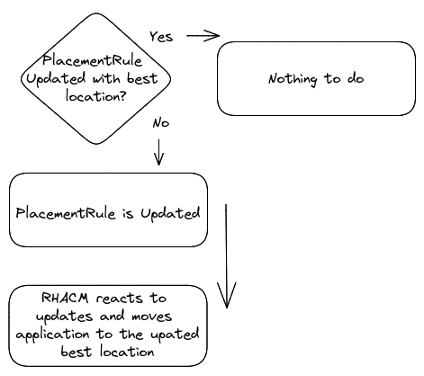
The solution blueprint covers continuous auto-application migration based on current latency metrics collected on interest origin locations where an application or service and users or consumers reside.
Testbed and demonstration
We recorded a demo in our testbed consisting of a hub cluster (name:local-cluster) and a managed cluster (name:sandbox01). These clusters are labeled (label:ddosify) with geolocation values (EU.ES.MA, EU.ES.BCN) on RH-ACM. The test bed allows you to experience:
- A latency comparison: At the demo application's initial orchestration time (first deployment), the cluster in EU.ES.BCN was observed with the lowest latency (41ms) versus EU.ES.MA with higher latency (43ms), and hence the application was deployed and tagged with EU.ES.BCN label -> sandbox01.
- A latency-based adjustment: We enforced (added fake latency overhead) an override on latency measurements on the external latency API integration side. The EU.ES.BCN (cluster:sandbox01) climbed to 45ms latency and the EU.ES.MA (cluster:local-cluster) stayed at 43ms. Hence, the local-cluster became the lowest latency cluster available for nearby service consumers.
- An application migration: RH-ACM autonomously initiated an application migration from sandbox01 (EU.ES.BCN) to the local-cluster (EU.ES.MA) cluster.
Wrapping up
Using an overseeing platform and service orchestrator (RH-ACM) with programmable capabilities (Kubernetes Operator framework) allows us to implement dynamic application management that leverages continuously measured latency (with user experience the key factor).
Per an agreement with the CNCF's Open Cluster Management (OCM) Working Group (WG), we will be working closely with the OCM WG to revise this custom latency operator to be part of the scoring framework.
This originally appeared on Medium and is republished with permission.
About the authors
Fatih E. Nar, has built a career by solving complex challenges in various domains including telecom, entertainment, media, and others.
With experiences at Google, Verizon Wireless, Canonical Ubuntu, Ericsson, and now Red Hat, he specializes in cloud native and data- and AI-driven solutions for enterprises and service providers.
His work blends AI, cloud, and high performance networked computing to create efficient and scalable software-driven solutions.
He holds an MSc in Information Technology and a BSc in Electronics Engineering, along with completed AI studies at MIT and Stanford, and has been admitted to Purdue University for a doctorate program for Spring 2026.
Fatih is also a recognized writer, sharing insights through his Open xG HyperCore series on Medium and contributing to AI/ML projects on GitHub and Hugging Face.
In 2025, Fatih was elected as a subject matter expert on AI/ML within Linux Foundation Networking (LFN) organization to steer and lead AI initiatives.
When not working, he’s likely exploring new datasets and AI models, ctl’ing with k8s, or sneaking dad jokes into tech discussions.
More like this
Can't patch fast enough? Zero trust as a last line of defense
What's new with image builder for Red Hat Enterprise Linux 10.2 and 9.8
Container Roundup | Compiler
The Containers_Derby | Command Line Heroes
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds