
At first glance, the idea of a self-healing IT infrastructure may seem intimidating. Can any infrastructure be simple and straightforward enough to fit into a cookie-cutter format? When you have a complex infrastructure, how can you think about software fixing other software by introducing self-healing?
I'll break down the self-healing concept into a simple form and try to decrease some of the intimidation. Then I'll build upon that example to show how it scales.
The four key components of a self-healing infrastructure are:
- Current state: How do you monitor or stream the environment's current state?
- Baseline: How do you compare your current state against a certain set of standards (such as risk, vulnerability, or compliance)?
- Remedy: If the current state does not match the baseline standards, what remediates the drift or vulnerable state?
- Automate: How do you automate the remediation process? It wouldn't be self-healing if there weren't an automated remediation, now would it?
A simple self-healing infrastructure
With those pieces defined, I'll provide a simple example of a self-healing infrastructure using a Red Hat architecture.
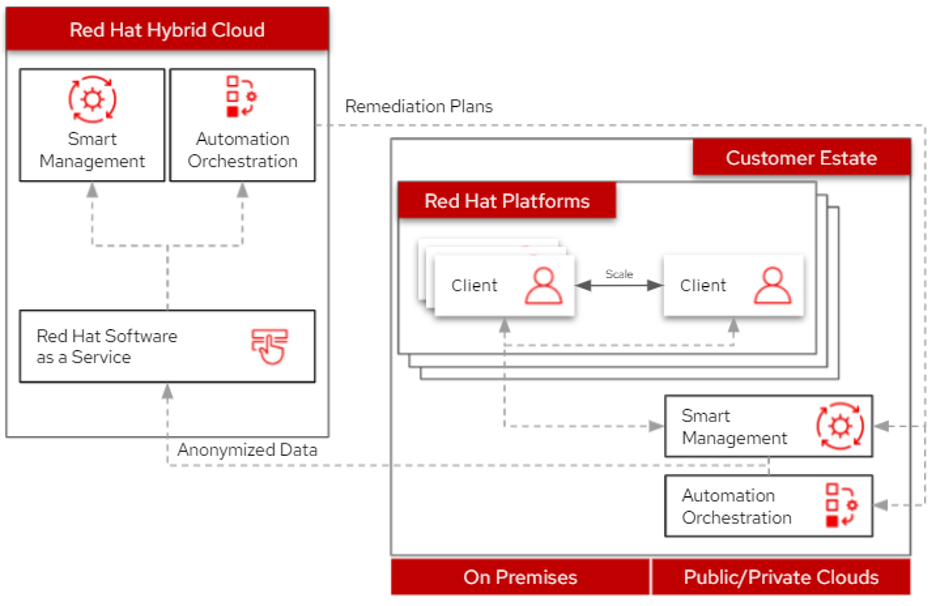
I'll walk through this simplified example architecture, starting at the Red Hat platforms component, which includes a Red Hat Enterprise Linux (RHEL) client system. These systems are active, so I can monitor their current state using Red Hat Smart Management (which you may know as Red Hat Satellite). It gathers running data using the Red Hat Insights client on each system.
After anonymizing the data, it's sent to the hosted Red Hat Insights software, which compares the data against the baselines. These baselines are designed around rules established using Red Hat's knowledgebase and a set of user-defined policies. Comparing the baselines to the current state can determine if there are any red flags, such as active vulnerabilities, compliance gaps, or incomplete patches.
If Insights finds any concerns, the hosted services determine a remediation strategy and design solutions for the discovered issues. It returns the solutions as Ansible playbooks, enabling an automated recovery to equalize the current state with the set baselines.
[ Learn how to modernize your IT with managed cloud services in this free eBook. ]
Can it scale?
OK, not so bad up to this point, right? But that scenario is simple, generic, and static. It's not very realistic, as systems can be hosted in different locations and may change dynamically.
For example, most organizations today spread development, quality engineering, and production environments across a hybrid cloud environment, with some systems on-premises while others are in the cloud. Not just that, but business fluctuates, and peak seasons require large deployments fast. Once a peak season ends, infrastructure needs to scale down quickly to the typical level to manage costs and resources.
Fortunately, the same architecture I described above also manages scaling environments across a hybrid cloud estate. Whether you have systems on-premises, geographically far away (maybe in the public or private cloud), or any combination, you can achieve this elasticity.
This self-healing architecture can handle the demands of a complex, scaling environment like it did in the simple example above, as everything flows through that same channel. You can also leverage Insights' Drift service, which runs a system comparison to keep systems in sync, even if they're running in different environments.
Wrap up
I hope this simple, generalizable example makes the idea of a self-healing infrastructure less intimidating. If you can achieve all four components of a self-healing infrastructure in a simple environment, there's no reason you can't scale the solution to meet your needs, regardless of the infrastructure's complexity.
If you would like to learn more, check out Red Hat's Portfolio Architecture Center, where you can find our architectures on self-healing architectures and other use cases. Our team's goal is to take complex customer deployments, simplify them so they are easily digestible, and share them back out with the community to continue the innovation chain. If you'd like to learn more or have some ideas of your own, reach out to us; we'd love your feedback!
About the author
Camry Fedei joined Red Hat in 2015, starting in Red Hat's support organization as a Support Engineer before transitioning to the Customer Success team as a Technical Account Manager. He then joined the Management Business Unit in Technical Marketing to help deliver a number of direct solutions most relevant to Red Hat's customers.
More like this
The value of unconventional experience: From sweeping hair to shaping careers
How Red Hat solves the toughest challenges in agentless infrastructure scanning
Container Roundup | Compiler
Untangling Networks | Compiler
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds