
As AI workloads move from experimentation to production, enterprises are consolidating GPU infrastructure into shared platforms. However, organizations that take this road face several tradeoffs. For instance, instead of dedicating entire accelerator nodes to a single workload, organizations are increasingly aiming to support multiple tenants per node. This boosts overall efficiency, because underutilizing GPUs by dedicating them to individual workloads increases infrastructure cost. But in such multitenant GPU environments, poor isolation can lead to serious issues, including performance interference, unpredictable latency, and even unintended data exposure between workloads.
Enterprises need to find a way to maintain strong isolation guarantees while preserving performance. Striking the right balance between isolation and utilization is critical for production AI platforms. Designing multitenant GPU environments that meet these requirements is more complex than simply assigning devices to virtual machines or containers. Isolation must be intentionally designed across hardware, virtualization, and orchestration layers. Red Hat platforms such as Red Hat OpenShift Virtualization and Red Hat OpenStack Services on OpenShift provide the foundation to implement these isolation layers by combining Kubernetes-native orchestration with proven virtualization and hardware integration capabilities.
This blog post examines how to safely design multitenant GPU infrastructure without jeopardizing performance or security, whether workloads run on virtualization-based platforms or in Kubernetes environments.
4 layers of GPU isolation
Multitenant GPU isolation must be enforced across multiple independent layers:
- Hardware isolation layer: Which tenant owns each physical GPU? This layer determines exclusive ownership of GPU hardware through mechanisms like PCI device assignment and IOMMU (Input-Output Memory Management Unit) enforcement.
- Fabric isolation layer: How do GPUs communicate with each other? This layer controls whether GPUs can exchange data across high-speed interconnects like NVLink, xGMI, or PCIe switches.
- Scheduler isolation layer: How does the orchestrator allocate GPU resources to tenants? This layer prevents the scheduler from accidentally mixing GPUs across isolation boundaries.
- Virtualization isolation layer: How are resources allocated to tenants? How are GPU resources partitioned and presented to workloads? This layer determines whether tenants receive full GPUs, hardware-partitioned instances (like NVIDIA Multi-Instance GPU, or MIG), or time-sliced shares.
In practice, most production failures in shared GPU environments are not caused by hardware limitations, but by misalignment between these isolation layers. For example, even if each tenant receives a dedicated GPU (hardware isolation), a misconfigured scheduler might assign GPUs from different fabric domains to the same workload, breaking isolation assumptions. True isolation demands intentional design across all 4 layers.
Figure 1 illustrates the concept of multilayer GPU isolation by depicting the separation across 4 critical layers: hardware, fabric, virtualization, and scheduler isolation. This visualization demonstrates how each layer contributes distinct boundaries that together enforce comprehensive isolation in multitenant GPU environments.
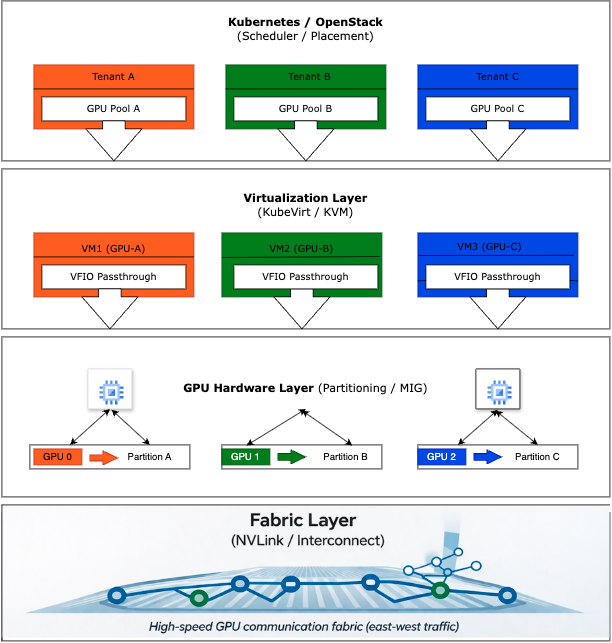
Figure 1. Layers of isolation in multitenant environments
Hardware isolation layer: Full device separation
In virtualization environments, full GPU passthrough assigns 1 or more entire physical GPUs to a single workload. Technologies such as Virtual Function I/O (VFIO) ensure exclusive device ownership at the hypervisor level. When a GPU is assigned to a virtual machine, the hypervisor uses the IOMMU to create hardware-enforced memory boundaries. The GPU can only access that specific VM's memory—not memory belonging to other VMs or the host. The hypervisor also places the VM on the same NUMA node as its GPU to avoid cross-socket performance penalties on multi-CPU systems.
This provides strong isolation at the device level: 1 GPU (or pool of GPUs), 1 tenant. However, device isolation alone does not automatically isolate high-speed GPU interconnect fabrics.
Fabric connectivity isolation: The hidden complexity
By default, GPUs may participate in a shared communication fabric. Modern GPU platforms usually connect GPUs via high-bandwidth fabrics such as NVLink, xGMI, PCIe, or emerging standards like CXL. No matter the type of fabric, the key design principle is consistent: device isolation alone is insufficient, as accelerators could potentially communicate across shared interconnects.
Figure 2 illustrates 2 different models for GPU fabric isolation: shared, which is the default, and partitioned.
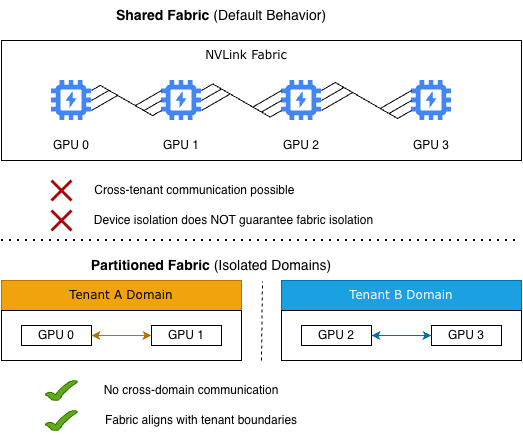
Figure 2. A shared fabric allows cross-tenant communication, while a partitioned fabric enforces stringent isolation between tenant domains
In a shared fabric model, GPUs can communicate freely across the interconnect, enabling cross-tenant communication. In this model, device-level isolation alone does not guarantee complete isolation when high-speed fabrics are involved. In contrast, a partitioned fabric groups GPUs into isolated domains aligned with tenant boundaries, restricting communication within each domain and effectively eliminating cross-tenant interactions.
This distinction emphasizes a critical design principle: by itself, the assignment of GPUs to specific tenants is insufficient to guarantee isolation. Fabric-level isolation must also be explicitly enforced.
Scheduler-level isolation: Preventing cross-domain allocation
Once hardware and fabric partitions are defined, the scheduler must respect those boundaries. Without proper scheduler alignment, GPUs from different hardware domains may be inadvertently mixed, leading to cross-tenant allocations that break isolation assumptions.
Why does scheduler alignment matter? Consider a system with 2 fabric domains, each containing 4 GPUs:
- Domain A: GPUs 0-3 (connected via NVLink)
- Domain B: GPUs 4-7 (connected via NVLink)
If the scheduler is unaware of these domains, it might assign GPU 1 (from Domain A) and GPU 5 (from Domain B) to the same workload. Even though both GPUs are isolated at the hardware layer, they cannot communicate efficiently because they're in different fabric domains, resulting in severe performance degradation.
Best practices include:
- Using topology aware labeling. Label GPUs with their fabric domain membership (e.g., fabric-domain=A, numa-node=0) so the scheduler understands topology relationships.
- Preventing cross-partition mixing. Configure affinity rules so that workloads receive GPUs from a single fabric domain.
- Monitor allocation correctness. Track whether workloads receive GPUs from expected domains—misallocation often appears as unexplained performance regressions.
Isolation is only as strong as its weakest layer. Even perfect hardware and fabric isolation can be undermined by a misconfigured scheduler.
Virtualization isolation layer: Resource partitioning and presentation
The virtualization layer sits between the hardware and the workload, controlling how GPU resources are partitioned and presented to tenants. This layer enforces isolation by determining whether a tenant receives exclusive access to an entire physical GPU, a hardware-partitioned slice of a GPU, or time-shared access.
Unlike hardware isolation (which prevents device-level access) or fabric isolation (which prevents interconnect communication), virtualization isolation controls resource allocation within a GPU. It answers: does this tenant get all the GPU's memory and compute, or do they share it with others?
Choosing the right deployment model
Deployment models describe how you assign GPU resources to tenants, while isolation layers describe where you enforce boundaries. Organizations choose a deployment model based on workload requirements, then enforce isolation across the 4 layers described earlier (hardware, fabric, virtualization, and scheduler).
- Full GPU passthrough: An entire physical GPU is dedicated to 1 workload, providing the strongest isolation and most predictable performance. This approach is ideal for training workloads and compliance-sensitive environments where exclusive access to resources is critical. You get maximum performance and isolation, but the tradeoff is lower utilization and higher cost per tenant.
- Hardware partitioning: The GPU is divided into isolated hardware instances, each with guaranteed memory and compute resources. Technologies like NVIDIA MIG or SR-IOV on AMD Instinct GPUs create hardware-enforced partitions within a single physical GPU. This model is well-suited for inference workloads that benefit from shared hardware while maintaining defined isolation boundaries. You get better utilization with hardware-level isolation, but the tradeoff is reduced per-instance performance and limited flexibility. Note that MIG provides strong compute and memory isolation but shares the GPU driver, while SR-IOV provides more complete driver-level isolation at the cost of higher overhead.
- Time-sliced or shared models: Multiple workloads share a GPU in this configuration. This enables high processor utilization, but processes cannot be guaranteed to be fully isolated from one another. This approach is suitable for development or burst cases where maximum resource sharing is prioritized over strict boundaries. You get maximum hardware utilization and the lowest cost per workload, but the tradeoff is that you lose resource guarantees, and there is potential for performance interference
All 3 deployment models still require isolation enforcement across the 4 layers (hardware, fabric, virtualization, and scheduler). The model you choose affects GPU utilization and performance, but isolation must be maintained across all layers regardless of the deployment model you select.
Operational considerations
Designing isolation is not only a hardware decision. Software lifecycle management introduces its own isolation risks that can break multitenant boundaries even when hardware is properly configured. The following operational concerns are critical for production deployments:
- Driver and kernel updates: In Kubernetes environments where tenants share the host kernel, a driver upgrade affects all tenants simultaneously. Consider a scenario where Tenant A needs driver 560.x for new features but Tenant B requires 550.x for compatibility. If they share a host kernel, both are forced to use the same version, breaking isolation and causing problems for the tenant who finds themselves running on the wrong version. Use containerized GPU drivers (like the NVIDIA GPU operator) or VM-based isolation to give each tenant independent driver stacks.
- Firmware and secure boot: GPU firmware updates affect all tenants on the same hardware. Buggy firmware can cause crashes or performance issues across tenant boundaries. In secure boot environments (a requirement for FIPS compliance), loading unsigned drivers for 1 tenant's custom needs can violate compliance requirements for other tenants.
- Resource discovery drift: As clusters scale, inconsistent GPU topology labels can cause the scheduler to allocate GPUs from different fabric domains to the same workload, breaking fabric isolation and causing severe performance degradation.
The key takeaway: Software lifecycle management is an isolation layer itself. Poor lifecycle governance allows changes in 1 tenant's stack to impact other tenants' workloads.
From lab to production
Many GPU deployments begin in controlled lab environments, where isolation concerns are minimal. However, once you transition your workloads onto shared enterprise platforms, you must take isolation boundaries into consideration and define tenant trust models, hardware domain boundaries, scheduler policies, and lifecycle governance processes. Isolation design should occur early, not after scaling begins.
Looking ahead
As AI infrastructure matures, the integration between hardware partitioning and orchestration frameworks will tighten. Emerging resource assignment frameworks are exploring more declarative and policy-driven models for accelerator management.
But until those models mature, organizations need a clear architectural understanding across the hardware, virtualization, and orchestration layers.
Conclusion
Multitenant GPU infrastructure can deliver both performance and efficiency, but only when isolation is intentionally designed across all layers of the stack.
By aligning hardware partitions, coordinating scheduler groupings, and implementing comprehensive lifecycle governance, organizations can establish robust isolation at every layer and thereby build AI platforms that are secure, predictable, and high-performing. These measures enable enterprises to minimize cross-tenant interference, ensure operational stability, and reliably scale shared GPU infrastructure to meet evolving workload demands.
As GPUs become foundational to enterprise workloads, isolation design will no longer be just an implementation detail; it will become a defining factor for the reliability, security, and scalability of modern AI platforms.
Build multitenant GPU platforms on Red Hat
Ready to design your own multitenant GPU infrastructure? The following resources can help you put these design principles into practice on Red Hat platforms.
- OpenShift Virtualization—GPU enablement: Learn how to configure NVIDIA vGPU, GPU passthrough, and the GPU operator for virtual machines on OpenShift
- Red Hat OpenStack Services on OpenShift—virtual GPUs: Step‑by‑step guide to exposing virtual GPUs (vGPU) to OpenStack instances
- NVIDIA GPU operator with OpenShift Virtualization: Official NVIDIA guide for deploying the NVIDIA GPU operator in a KubeVirt environment.
- OpenShift Virtualization overview: A high‑level introduction to running virtual machines on Red Hat OpenShift.
Resource
The adaptable enterprise: Why AI readiness is disruption readiness
About the author
Sudhakar Molli is a Principal Product Manager at Red Hat, where he leads hardware accelerator strategy across Red Hat Enterprise Linux, OpenShift, OpenShift Virtualization, and Red Hat OpenStack. He focuses on GPU enablement, virtualization, and next-generation accelerator infrastructure for enterprise AI and high-performance workloads.
Sudhakar works at the intersection of operating systems, virtualization, and Kubernetes to align kernel, hypervisor, and orchestration layers for production-grade accelerator support. His areas of interest include GPU virtualization models, multi-tenant isolation, dynamic resource allocation, and the evolving architecture of AI infrastructure across hybrid cloud platforms.
He is passionate about simplifying complex infrastructure concepts and helping organizations design scalable, secure, and high-performance AI environments.
More like this
The evolution of infrastructure automation in the age of AI: 4 key takeaways from Red Hat Summit 2026
Agentic AI on Red Hat OpenShift: What enterprises are doing right now
Technically Speaking | Defining sovereign AI with open source
Technically Speaking | Inside open source AI strategy
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds