
Introduction
Red Hat OpenShift Cluster Manager (OCM) is a managed service where you can install, modify, operate, and upgrade your Red Hat OpenShift clusters. This service allows you to work with all of your organization’s clusters across the hybrid cloud landscape from a single dashboard.
OCM consists of a set of microservices that compose OpenShift Cluster Management. The main two are cluster-service and account-management. Because OCM is a cornerstone of Red Hat’s hybrid cloud strategy, we strive to make sure that it is scalable enough to handle peak traffic and find bottlenecks that can be fixed to present a satisfying experience for our customers.
The Performance & Scale team, whose mission is to establish the performance and scale leadership of Red Hat’s portfolio, regularly scopes out, conducts, and analyzes results from load tests. During this process, we discovered a performance problem that affected a core component of the API. In this blog post, we will discuss how we identified the problem, how we worked as a cross-functional team to identify and fix it, and the measures we implemented to prevent similar incidents from happening in the future.
Testing for issues
To ensure the reliability and stability of the OCM API, we defined a testing procedure to identify the breaking points of several key endpoints of the API. These tests included load-testing those key API endpoints to a certain level to ensure that OCM could handle a burst of requests from our customers and still perform at the expected level.
We developed an open source tool called ocm-api-load, which can take a parameterized configuration telling it what endpoints to test, at which rate, and for how long, even adding a ramping scenario that can test an endpoint with an increasing traffic load during a particular timeframe. The tool constructs the appropriate requests and uses Vegeta under the hood to run the tests, and then collects, parses, and stores the data for analysis.
Finding problems
During our testing process, we found a critical issue in the cluster-authorizations endpoint of the OCM API. The issue involved the amount of data that is stored in the database as a subscription. A subscription is the paid license of the OpenShift platform, and depending on the type of cluster you are deploying, you need a certain amount of subscriptions (read here for more). As the tests increased the numbers of subscriptions, each request became slower to respond, and eventually the API could not keep up with the number of requests. The result of subsequent requests was an empty failed response.
The scenario where we found the problem was running at 30 req/minute: During 30 continuous minutes, we can see on a previous run that the end point was stable and response latencies were under 700 milliseconds.
Scatter plot of the latencies prior to the error:

In subsequent runs of the test framework, without the scenario changing, we started to see a strange behavior as shown on the graphic below, a scatter plot of the latencies. Notice that the times in the graph go higher, to almost 18 seconds. To actually show the problem in the graph, we needed to use a logarithmic scale. At around the four minute mark, the highest latency is reached and the errors start to come back (represented in yellow). If you notice the status code, all the errors are 0, an undefined error, which means the API is not responding correctly.
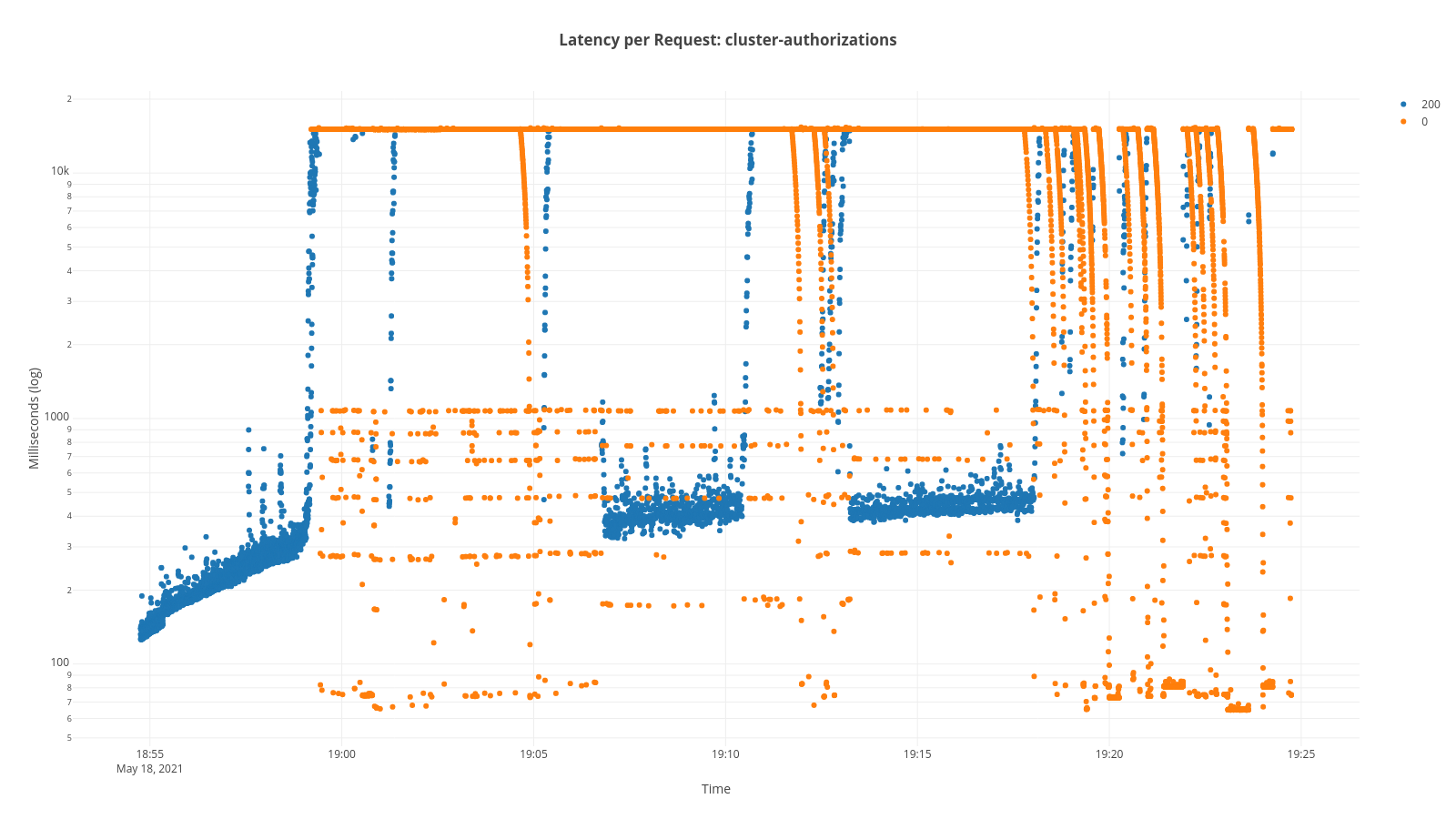
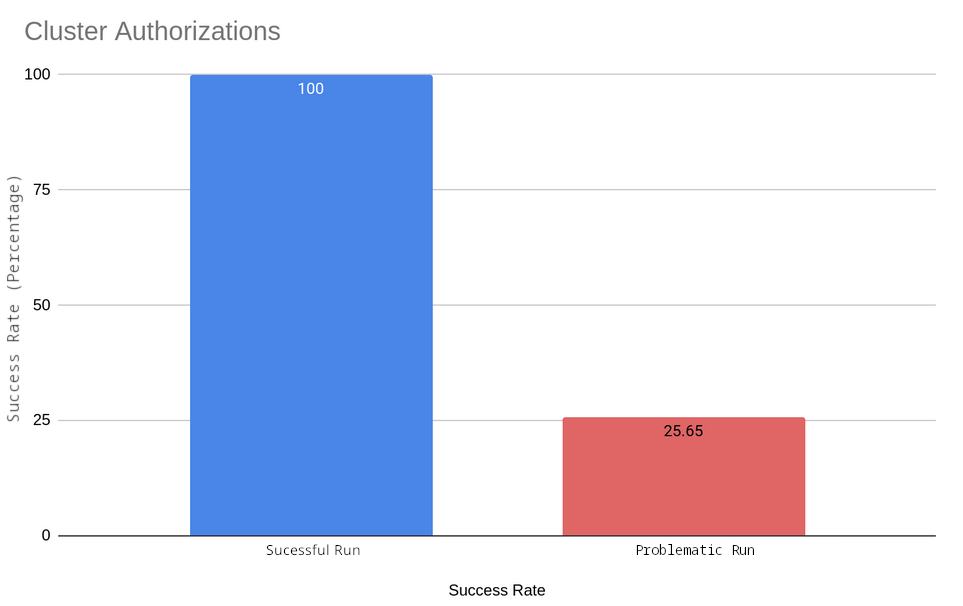
If you compare this to the above-referenced run where there was no problem, you will see two big differences: Max latency has increased by approximately 20 times, and the success rate has decreased, from 100% to 25%.

We communicated this issue with the development team and collaborated on a live debugging session that helped the team pinpoint exactly where that issue was happening. An action item was generated and added to the team's work queue.
As we continued the investigation, we found some high CPU usage on the main service that is in charge of the endpoint that was showing problems.
High CPU usage on acct-mngr service:

The development team worked diligently to identify the root cause and submit a fix. As the tests for the next version of the OCM API were done, we paid special attention to the cluster-authorizations endpoint, as the fix for the issue had been merged and deployed.
After analyzing the test results, we discovered that the test was completely successful. In fact, the team managed to reduce the latency of the test to 25% lower than it was before we noticed the issue.
Once the fix was introduced, we focused on the cluster-authorizations endpoint to check if it provided the expected effect. Here are the results:
This table shows the test we performed. All scenarios were run for 10 minutes:
|
Rate |
Total requests |
Min |
Max |
95% |
99% |
Success Ratio |
|
1 rps |
600 |
147.373ms |
632.612ms |
186.805ms |
195.429ms |
100% |
|
3 rps |
1800 |
159.285ms |
714.322ms |
184.1ms |
233.565ms |
100% |
|
6 rps |
3600 |
88.825ms |
2.055s |
283.429ms |
529.32ms |
100% |
|
9 rps |
5400 |
91.367ms |
5.315s |
111.311ms |
321.775ms |
100% |
If we compare the test we ran against the first run that started failing, the first one was running at 0.5 req/second and now we are able to reach 9 req/second without getting a single error on the requests.
Future tests will attempt to get the limits of the endpoints that we run using ramping.

This shows that we are able to sustain 9 req/second with no problems. Once we pass from 12 req/second to 15 req/second, ,we start getting errors and we get a success rate of 72%.
Preventing future incidents
To prevent similar issues from arising in the future, we have implemented fully automated continuous load testing. This runs on a weekly schedule, generating load on the designated endpoints for an interval of time and indexing the results into an Elasticsearch/OpenSearch back end for us to check. This provides us with enough data to do side-by-side comparisons and determine whether there has been a change that affects the performance of the API.
Conclusion
At Red Hat, we understand the importance of maintaining a reliable, performant, scalable, and more secure platform for our customers. We are committed to discovering and resolving issues quickly and efficiently and to working with other teams to help pinpoint the root cause of problems. We also implement preventive measures, such as continuous performance testing, to ensure a seamless experience for all our customers so that they can continue to trust us with their mission-critical workloads.
About the author
More like this
Why Operational Resilience and Digital Sovereignty Top the CIO Agenda
How Red Hat OpenShift 4.22 impacts enterprise AI’s bottom line
Crack the Cloud_Open | Command Line Heroes
Edge computing covered and diced | Technically Speaking
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds