


As modern digital infrastructure evolves towards cloud-native deployments and the hybrid multi-cloud, there is a growing need to simplify the operational complexity that results from the various layers of technology used in the process.
Modernizing the digital infrastructure presents significant challenges to operations (Ops) teams. In the old days, an Ops team used to be able to identify problems occurring in a given datacenter—and easily narrow it down to one box running mainly one application—with the whole infrastructure/application stack typically sourced through one vendor (sometimes two if the hardware is purchased separately).
Today, with the evolution into the hybrid multi-cloud environment, infrastructure is sourced through multiple vendors (on-premise private cloud), and applications typically live in multi-tenant environments (public or private clouds). So while the cloud-native infrastructure itself provides better redundancy and high availability capabilities, applications and services are still subject to all types of failures and hence the need for closed-loop automation solutions, both at the application and infrastructure levels.
Before we explain the notion of service assurance and closed-loop automation, let’s briefly describe orchestration and automation in the telco world.
Orchestration and automation
Whether it is software-based infrastructure, applications, or hardware equipment, there are typically a lot of steps involved in deploying and managing their lifecycle, hence the need for automation and orchestration.
Automation is the act of taking a manual, domain-specific step and making it repeatable in order to achieve predictability and abstract the underlying components. The goal of automation is to expose consumable interfaces for a given domain by providing higher-level capabilities.
Orchestration is about stiching together automation steps. Generally, the goal of an orchestrator is to control end-to-end services. It is also common to have domain-specific orchestrators and a service orchestrator acting as the main engine. The orchestrator's topology varies based on the vertical, but in telco, it is common to have an orchestrator for the core, the RAN, and the cloud and have them all stitched together with the service orchestrator to provide an end-to-end business centric flow.
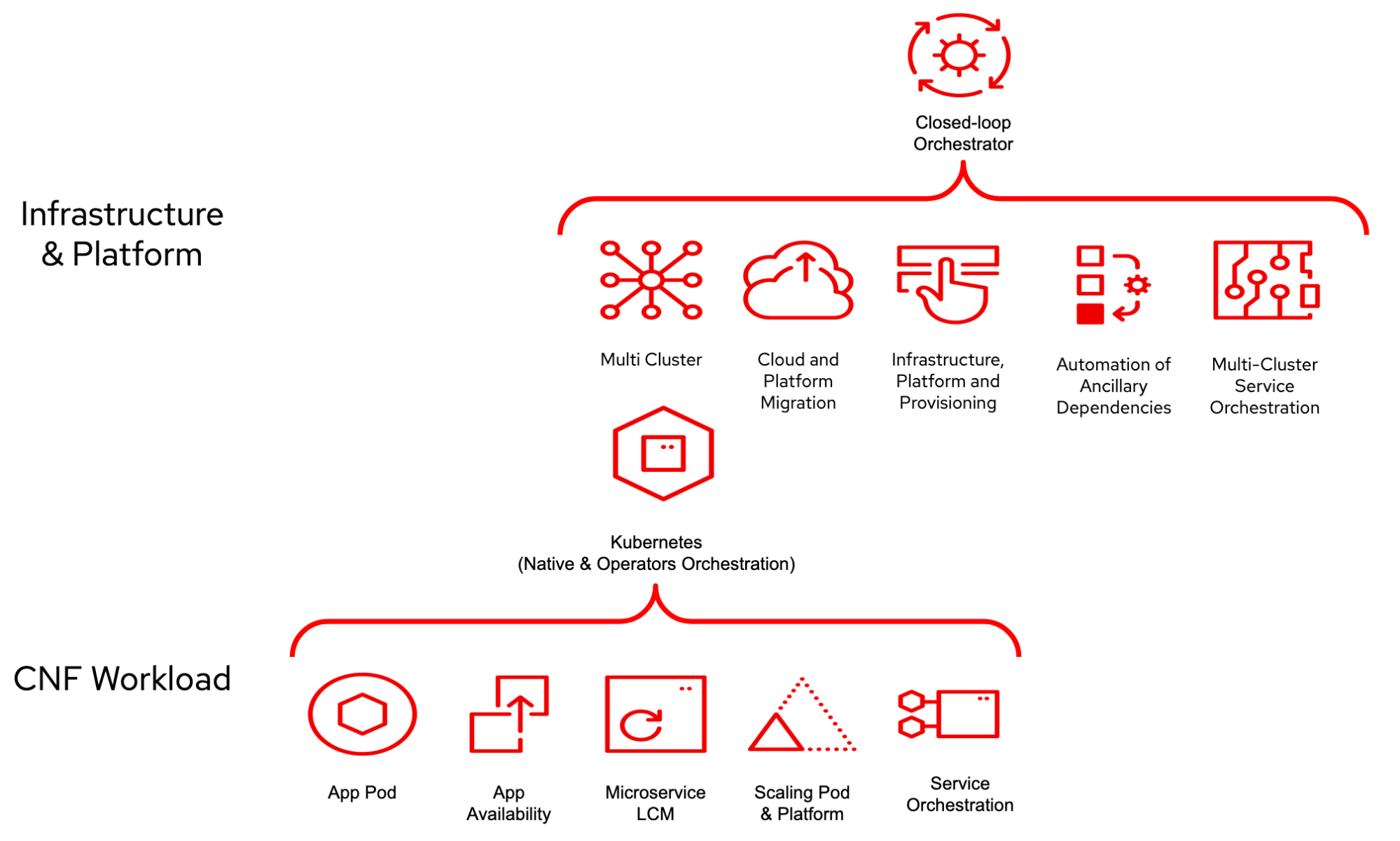
For example the deployment of a 5G core service is usually called orchestration. There are a lot of orchestration tools available, and some of these are provided by the software vendors themselves.
Overall, automation and orchestration can make deployments faster and reduce the chance of human error. There are various ways to do so. At Red Hat, our favorite approach is using the Red Hat Ansible Automation Platform.
Also, there is a growing trend to adopt GitOps methodology to manage and deploy content, whether it is hardware configuration, software deployment manifests or infrastructure descriptors (for infrastructure as code). It utilizes the concept of automation and orchestration, and leverages some built-in capabilities of Kubernetes.
Learn more about how GitOps can help achieve automation and orchestration of operations by reading The role of the Orchestrator in GitOps-driven operations.
Open-loop vs. closed-loop (automation)

This duality is from control systems theory.
Open-loop automation is when deploying an application in a cloud environment without necessarily receiving feedback after the deployment is complete; and if a feedback is received, an Open-loop will not take action on it, rather, it will require a human to look into it and take action; i.e. the loop is open for human intervention.
Closed-loop automation is when feedback is received and is taken into account for further action to be taken “automatically” by the controller; that automatic action is often referred to as “remediation” and “reconciliation." The system will close the feedback loop.
There is a growing demand for open/closed-loop automation, which combined with AIOps can provide an intelligent and efficient way of auto-remediating a detected problem. One of the main advantages of a close loop is its “self-healing” capability leading to an important reduction in the operations.
But, it is not always possible to find a proper remediation solution. Sometimes, the number of factors to account for are too broad, or the environment in which the problem occurs is too dynamic; this is very true in the telecommunication domain.
Telco expectation, and reality
There have been many initiatives to implement a comprehensive closed-loop automation platform in the telco world, and one of these is Open Network Automation Platform (ONAP). ONAP is an open source network automation platform that defines an architecture to orchestrate and manage multi-cloud deployments of network services. Closed-loop automation is a part of this initiative.
Given CSPs investment in systems to operate their network and their business, trying to displace them through something like ONAP is challenging for the following reasons:
-
Business continuity
-
Compliance
-
Cost
-
New expertise
Standing up a completely new way of operating means replacing entire organizations, therefore it is critical to be able to integrate with existing systems, leverage as much as possible from the current solutions, and transition/evolve operations in a less intrusive manner.
In this post, we propose a model that leverages familiar technologies to implement service assurance in a hybrid cloud environment, with the ability to integrate into existing CSP business systems and solutions.
Architecture blueprint for closed-loop automation
We present below an architectural blueprint for closed-loop automation. Consider an application (example: 5G core network function, RAN vCU, etc.) running on a Kubernetes-based platform like Red Hat OpenShift, in a hybrid cloud environment. Assume the application deployment has been orchestrated by Ansible or any other orchestration/automation platform. The application consists of multiple microservices that need to be monitored.
Dynatrace is an AI-powered observability platform that does exactly that. It integrates with the major cloud platforms and technologies so we decided to leverage it in this scenario.

Now let’s go over the event-based architecture implemented by the Red Hat Application Services portfolio using a simple use case.
Assume we have the application “app” running on OpenShift (OCP) and exposed by an OCP route. When a problem occurs (in this case, someone from an Operations team deletes the route for example), Dynatrace identifies the issue, and is integrated with Red Hat AMQ (a Kafka-based messaging platform) through a webhook. Dynatrace sends a notification on a given message queue. Red Hat Fuse is listening on the queue, it picks up the event and it’s time to process it.
Red Hat Fuse is an integration platform based on Apache Camel. It facilitates the integration of multiple services and components of this solution. In this case, it integrates with the cloud-based service ServiceNow and creates a ticket as soon as the event is detected.
As part of processing the event, Fuse leverages Red Hat Decision Manager, a Drools-based middleware solution that acts as the decision maker (but not alone). Red Hat Process Automation Manager is a BPM tool that can implement more complex business workflows, and in this case, it integrates (through Fuse) with other third-party products (example: inventory databases) and/or Red Hat tools like OpenShift Data Science to figure out the remedy action.
Going back to our use case, Red Hat Decision Manager identifies the action to take, based on the problem ID just detected. In this case, it’s an Ansible playbook that will restore the deleted route for “app.”
Once the remedial action has been determined, Fuse picks up the “action” from Decision Manager and invokes the automation/orchestration platform (in this case Red Hat Ansible Automation Platform) to deploy the fix. Ansible Automation Platform restores the route and the application is now accessible. Problem solved.
In the next step, Dynatrace detects that the problem has been resolved and clears the issue. That information also gets posted on the AMQ message bus through the Dynatrace webhook, where Fuse picks it up using the same mechanism described earlier and updates the Service Now ticket accordingly first, then the Dynatrace comments.
This completes the cycle. We have now implemented a self healing infrastructure solution using closed-loop automation and an event-based architecture.
This solution provides a variety of capabilities such as
-
Single pane of glass to review application status
-
Detect and resolve incidents without or with manual intervention
-
Flexible integration into your environment
-
Enable self healing applications with Red Hat and Dynatrace working together
Here are some benefits of the solution:
-
Faster MTTR
-
Improved availability
-
Reduction of and less costly outages
-
Reduced Operator engagement/error
-
Consistent operations
-
Less manual intervention
-
Highly flexible and extensible
-
Cloud Ready
-
SLA/SLO compliance
-
Unified view of entire environment
-
Automated
-
Auto-scalable
Implementation summary
To summarize, a simple implementation of this architecture, here are the steps:
-
Deploy OpenShift (example: 3-node cluster on public cloud)
-
Install Ansible Automation (example: automation controller on OpenShift or from Operator Hub)
-
Configure Dynatrace for the OpenShift cluster (using Dynatrace Operator)
-
Deploy AMQ Streams on OpenShift cluster from Operator Hub
-
Deploy Decision Manager (as an OpenShift pod)
-
Integrate/configure ServiceNow
-
Deploy Red Hat Fuse (as an OpenShift pod)
-
Install a sample application and configure Dynatrace webhook
Closing remarks
As the infrastructure and business processes transform to leverage a more on-demand and self-service approach, it is important to provide Ops teams with solutions enabling proactive remediation of errors. As we implement the proposed blueprint in the context of a cloud-native environment, we will share details on how to proceed and the observed outcome.
On a similar note, read now how Self-healing infrastructure with Red Hat Insights and Ansible Automation Platform makes IT operations simpler and more reliable. It leverages similar concepts as presented in this blog, with a different implementation and context.
Another contribution showcasing how automation can facilitate and accelerate consumer, business, and mobile service delivery has been published here.
To conclude, Red Hat is committed to help the Telecommunication industry by providing the horizontal platform enabling the deployment of components such as 5G networks. Looking ahead, as we start harvesting the edge, such architecture blueprint will be dissected to be more distributed.
About the authors
Rony Haddad is a Senior Solutions Architect at Red Hat, supporting North American Service Providers. Haddad has extensive experience in the areas of infrastructure design, cloud deployments, large scale systems integration and hybrid multi-cloud design in addition to network automation and orchestration.
Alexis de Talhouët is a Telco Solutions Architect at Red Hat, supporting North America telecommunication companies. He has extensive experience in the areas of software architecture and development, release engineering and deployment strategy, hybrid multi-cloud governance, and network automation and orchestration.
Rohit Ralhan is a Senior Specialist Solutions Architect at Red Hat, supporting North American service providers. Ralhan has extensive experience in creating solutions for customers in multiple domains across the globe. He has strong background in enterprise integration, messaging, business process and decision management solutions involving architecture, design, development and deployment across industries.
More like this
The evolution of infrastructure automation in the age of AI: 4 key takeaways from Red Hat Summit 2026
Govern privileged workload boundaries with Red Hat OpenShift, Ansible Automation Platform, and Identity Management
Untangling Networks | Compiler
Operating System Management | Compiler
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds