


There has been a huge increase in demand for running complex systems with tens to hundreds of microservices at massive scale. End users expect 24/7 availability of services they depend on, so even a few minutes of downtime matters. A proactive chaos engineer helps meet user expectations by identifying bottlenecks, hardening services before downtime occurs in a production environment. Chaos engineering is vital to avoid losing trust with your end users.
To help address the need for a resilient Kubernetes platform and provide improved user experiences, Red Hat collaborates with the open source community and end users to build and maintain open source tools and chaos engineering frameworks such as Krkn. To get a sense of Krkn's capabilities, here are a few additional resources for insights and findings from chaos test runs.
With the increase in adoption of Krkn for a large number of products by the community and customers, we were facing challenges where artificial intelligence (AI) proved useful:
- Adding and updating test cases as products get new features and fixes.
- Adding and maintaining chaos test coverage for multiple products, which involves tracking them closely.
- Running hundreds of test cases, instead of just the ones with a perceived high probability of disruption.
Red Hat Chaos Engineering and IBM Research teams are collaborating to integrate AI in Krkn for improved and automated test coverage that can help scale chaos testing efforts for multiple products running different architectures, node scale and traffic patterns.
AI integration in Krkn use case
With the increase in adoption of Krkn for chaos testing various products and configurations, test cases for good coverage have become complex. For instance, suppose you have an application stack with numerous deployments and pods must coordinate to serve user requests. To chaos test it, you must understand the architecture and design test cases depending on the nature of the service (dependency patterns of one microservice on one or more other services or resource intensive/CPU, memory, input/output operations per second, network or traffic patterns and so on).
To cover this, you'd need to run hundreds of test case iterations, requiring extensive human hours and potential cloud costs. Even with that effort, constant monitoring is necessary to look for missing edge cases, and to adapt test cases as the application stack evolves (feature additions, architecture changes and so on). It’s hard to predict the combination of scenarios when run against multiple pods, which can lead to missed Service Level Objectives (SLO) and degradation in performance, ultimately impacting the service.
Imagine doing this for a large number of products and applications. You can solve this with Chaos AI integration in Krkn. This is a classic example of how AI can adapt and assist in increasing the capabilities and solving complex problems.
The goal is for the deployed Chaos AI and Krkn framework to automatically discover and run scenarios impacting the service, and use reinforcement machine learning to adapt to changes in the product stack.
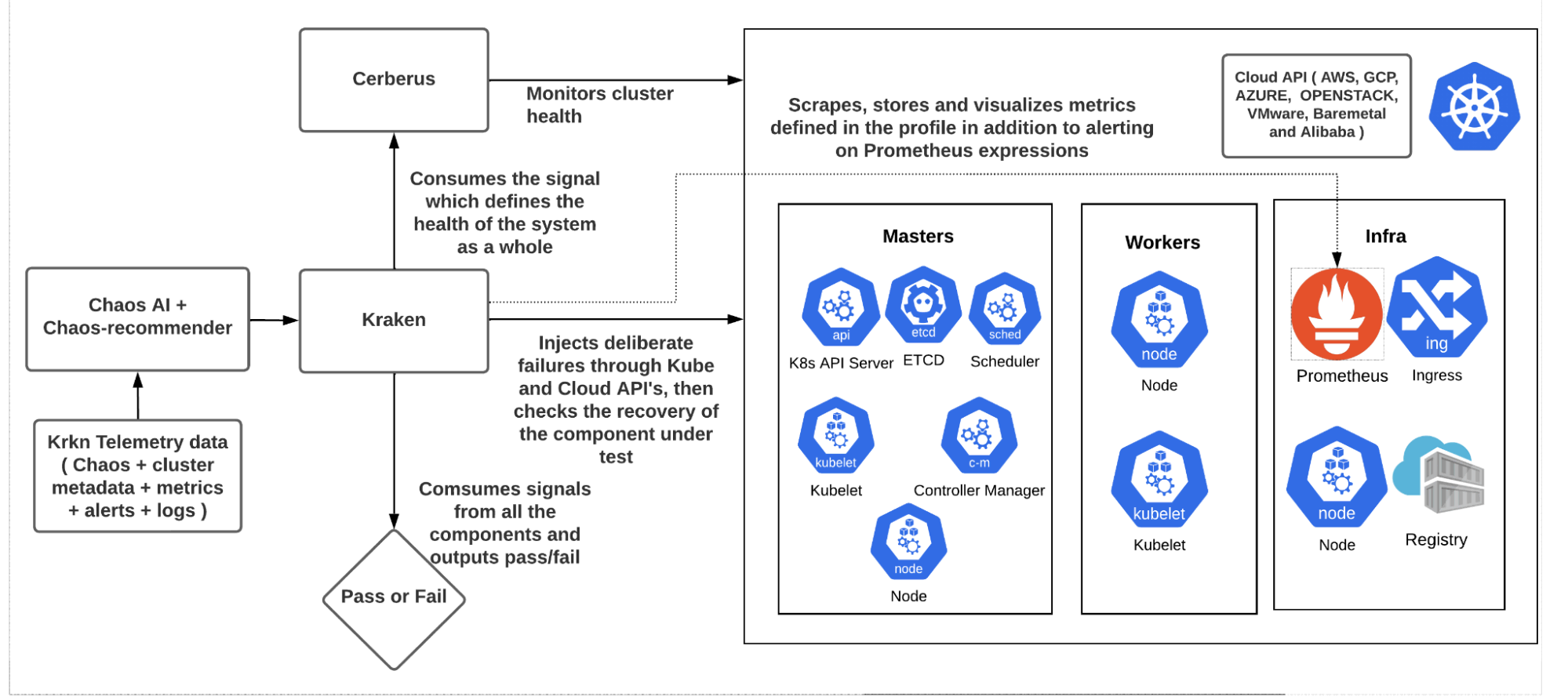
Krkn
Krkn is a chaos engine that can target cloud, Kubernetes and OpenShift APIs to inject failure conditions and track recovery of the targeted component, overall health of the cluster and performance SLOs.
Chaos-recommender
Given pointers to a service, chaos-recommender profiles each pod using Prometheus to understand whether they are network intensive or related to CPU, memory or I/O, and suggests to Krkn scenarios that have the highest probability of causing disruption.
Krkn Telemetry
When enabled, Krkn Telemetry captures and stores metrics, alerts, chaos parameters, test pass/fail and logs, in addition to environment details such as scale (number of nodes, pods, routes and so on), architecture (AMD, ARM, X86_64), network plugin (SDN, OVN) and more. This data is used for training the AI/ML model to understand what components are failing often so that they can be tested more.
Chaos AI workflow
This is the end-to-end framework that takes Krkn scenarios and SLOs as input and, with help from chaos-recommender and Krkn-telemetry, assigns weight to components requiring testing and runs different combinations of scenarios against the application stack.
Here's an example workflow for Etcd and ApiServer:
Step 1
A user provides Etcd and ApiServer namespaces as targets and SLOs for the AI to check and reward on misses. For example:
openshift-etcdandopenshift-apiserverare the namespace inputs- API server has 99% latency < 1 sec
- SLO is that Etcd has leader elections < 0
Step 2
Chaos-AI triggers chaos-recommender. It profiles the Etcd and ApiServer namespaces to identify chaos scenarios that have high probability of getting disrupted based on resource usage metrics in prometheus.
Step 3
The Chaos-AI model is trained using reinforcement learning. Krkn-telemetry data on Etcd and ApiServer components is gathered to determine which pods and containers are failing often.
Step 4
Chaos-AI assigns weight based on Step 2 and Step 3 and runs Krkn scenarios. The reinforcement learning is based on a system where the framework rewards itself on missed SLOs. In this example, that happens when API latency is > 1 sec and Etcd goes through leader elections.
It also runs other areas that are least expected to be disrupted, but with fewer iterations. Suppose it finds a new component or combination failing often. This would get recorded in Krkn-telemetry and fed back to the model to be considered for the next iterations.
Step 5
Failures are output for you so you can address them.
This is a continuous process that adapts as the product evolves and identifies areas to improve without human intervention when there are potential missing edge cases.
Use cases
Instead of manually identifying and adding test cases in your product release CI, you can use this framework to automatically identify and run test cases, and even automatically adjust not only the components to target, but newly introduced components.
Better yet, you can easily add, scale and expand test coverage not only for Red Hat OpenShift but for the entire portfolio including Red Hat OpenShift Service on AWS, Red Hat OpenShift AI and more.
What’s next?
Krkn and Chaos AI integration helps you improve test coverage. It boosts confidence in your products and environment, and enables users to scale faster by increasing the number of products and application stacks they can test.
Stay tuned for results from the integration and findings in the coming blogs. As you can see, some of the pieces including Krkn, chaos-recommender and Krkn-telemetry are already open sourced and can be leveraged to test and harden your environment. We are actively working to open source the entire Chaos AI + Krkn framework.
Feedback and contributions are welcome. The code is on Github and of course we're more than happy to discuss and collaborate on your use cases.
About the authors
Naga Ravi Chaitanya Elluri leads the Chaos Engineering efforts at Red Hat with a focus on improving the resilience, performance and scalability of Kubernetes and making sure the platform and the applications running on it perform well under turbulent conditions. His interest lies in the cloud and distributed computing space and he has contributed to various open source projects.
Mudit Verma is a Senior Research Engineer at Cloud Operations Dept., IBM Research. He possesses over 8 years of research experience. His areas of expertise and interest encompass Distributed Systems and Cloud. In recent years, he has been active in the area of intelligence-driven Cloud Operations and enabling self-* properties including Closed-Loop Management and assurance, AI based Chaos and effective Observability. He has also been a co-inventor of more than 20 United States patents (at various stages of filing), and been a co-author of multiple research papers accepted at top-tier conferences. Additionally, he has actively mentored multiple students and collaborated with professors of various eminent academic institutions such as Boston University, IISc, IITs, IIITs, etc. He is also an ACM Eminent Speaker. He holds bachelors and masters degree from BITS-Pilani and KTH Sweden respectively.
Sandeep Hans is working as a Research Scientist at IBM Research Lab – India. He has extensive experience in Distributed Systems and Artificial Intelligence. He is a co-inventor of multiple patents and co-author of more than 15 research papers in top tier conferences. He received his Ph.D. in Computer Science from Technion - Israel Institute of Technology under the guidance of Prof. Hagit Attiya. Prior to joining IBM Research, he was a post-doc at Virginia Tech in USA and has also worked with Mindtree Consulting Ltd. in Bangalore. He is currently working on building dependable systems using adversarial AI testing.
More like this
Why Operational Resilience and Digital Sovereignty Top the CIO Agenda
Demystifying agentic AI: How to build production-ready AIOps with open source models
Technically Speaking | Defining sovereign AI with open source
Technically Speaking | Inside open source AI strategy
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds