
Introduction
Over the past decade, there has been an industry-wide surge to begin integrating machine learning into future strategies. Whether to create a new service or enhance existing services to customers, an internal tool to improve their infrastructure, or anything in between, there is no denying the value of machine learning. It has an endless variety of applications and is not limited to any specific industry. Adapting AI/ML has become a key to innovation, and it’s important to understand what goes into making this innovation possible by examining the model lifecycle.
The data science model lifecycle demonstrates the end-to-end process for creating machine learning models and deploying them in production. This requires many hands on the back end and isn’t a straight forward path. In this blog, we’ll walk through the ML model lifecycle with an example use case created by a few data scientists at Red Hat.
Overview
Machine learning is a subset of the larger field called artificial intelligence and employs the use of computer algorithms to learn from historical data in order to make future predictions. In a typical workflow, a data scientist will train a machine learning model and then deploy the model for inferencing. During training, a computer algorithm is applied to a training data set that produces a machine learning model. During inferencing, a model returns predicted results when given live input data.
A Data Science project contains data as its main element. Without any data, we are not able to do any analysis or predict any outcome as we are looking at something unknown. Hence, before starting any data science project that we have been given from either our clients or stakeholder we must first understand the underlying business problem statement. Once we understand the business problem, we can dive into the different phases of development and implementation.
A data science lifecycle is an iterative set of data science steps you take to deliver a project and conduct analysis to achieve a business outcome. Because every data science project and team are different, every specific data science lifecycle is different. However, most data science projects tend to flow through the same general lifecycle of data science steps. Some data science lifecycles narrowly focus on just the data, modeling, and assessment steps. Others are more comprehensive and start with business understanding and end with deployment of intelligent applications into production. And the one we’ll walk through is even more extensive to include operations. It also emphasizes agility as a key characteristic across the lifecycle.
This lifecycle has five steps:
- Problem Definition - Just like any good business or IT-focused lifecycle, a good data science lifecycle starts with “why”. In this phase, we state clearly the problem to be solved and why.
- Data Engineering - The next step after problem understanding is to collect the right set of data. In this phase, we gather relevant data needed to solve the problem, store the data and perform exploratory analysis to prepare the data for ML model training.
- Model Development - In this phase, we build the ML algorithm to solve the problem. We train the model on the data set and evaluate the model’s performance on the unseen data points (test set).
- Model Deployment - Once the stakeholders are pleased with the model’s results, the next step is to deploy the model within an intelligent application. The purpose of deploying your model is so that you can make the predictions from a trained ML model available to others, whether that be users, management, or other systems.
- Model Monitoring and Management - Once the model is deployed we need to continuously monitor the model to ensure that its performance is optimized and the business objectives are not compromised.
Data Science Model Lifecycle Architecture and Personas
In practice, there are actually quite a few players/personas involved. Let’s take a close look at the personas involved in this ML lifecycle and the major categories of managed services that would be required for model delivery. Please note that it's possible that different organizations may not have all of the following job titles involved and the description provided below is to mainly help generalize the tasks during each step of the lifecycle.
- Business Leadership
- The role of the business leadership is to define the use case, business requirements for the AI/ML project and business outcome goals to be achieved such as improving customer experience, reducing costs, shortening build times etc.
- Data Engineer
- The role of the data engineer is to take in raw data and curate (clean, prepare and organize) it for the data scientist to consume. Data engineers therefore need the ability to produce and reproduce data pipelines on demand. They need services that will be able to automate the tasks of pulling in raw data and curating it. Note the data engineers have to be able to monitor the raw and curated data to make certain it is of high quality. And it is imperative that they detect and fix any issues with the data before the data scientist receives and starts work on it. Additionally, the data engineer should be the point of contact for data security and access control for audit purposes and ensuring that no unknown data sources are used.
- Data Scientists
- The role of a data scientist is to analyze a data science problem and through repeatable experiments produce an analysis using algorithms and models along with a variety of programming languages (such as Python or R) and their associated libraries. Common tools include using PyCharm, Anaconda or JupyterLab Integrated Development Environments (IDEs) with Jupyter notebooks for experimentation, and having a reproducible and shareable work environment to deliver their solutions on. Data scientists are often not concerned with underlying infrastructure, code repositories, and model deployment and delivery methods. Instead, their focus should be on experimenting and generating high quality models for the use case.
- App Developer / ML Engineer
- The focus of the application developer is to run and integrate the model serving microservice and possibly other applications that use the model serving microservice into an intelligent application in a production environment. They spend a great deal of effort in building and maintaining the serving pipelines which automate the model rollout process into production. This step is crucial as it takes the model from the data scientist and developer workspace to a code repository and then ensures a secure and smooth delivery (usually via containerization) into the production environment. In some cases, application developers may not have the machine learning know-how to streamline the delivery of a model and can get help from the data scientist or ML Engineer.
- IT Operations
- IT operations is concerned with the overall usability of the platform. They are also responsible for infrastructure monitoring (that is, compute, networking and storage), platform maintenance (for example, Kubernetes), platform security, and hardware acceleration (for example, Nvidia GPUs). It is vital that the other roles work with IT Operations to ensure that anything nonstandard in the environment is vetted before use.
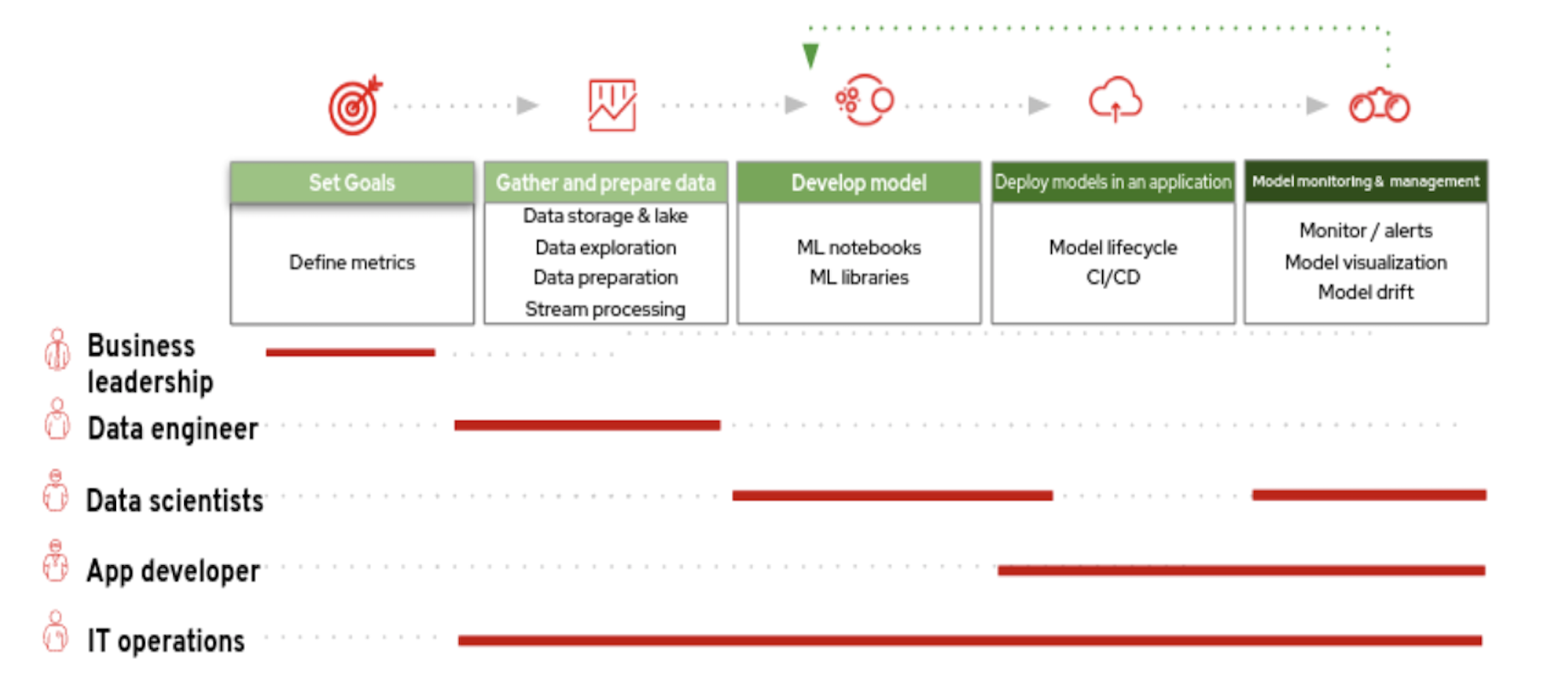
Figure 1: Data Science Model Lifecycle
Figure 1, above, shows the different phases in the lifecycle and the key personas involved throughout the different phases.
Model Lifecycle in Detail
Now, let's look at the model lifecycle in detail with an example use case/project that some of the data scientists at Red Hat worked on. AI for Continuous Integration is a project focusing on developing AI tools for developers by leveraging the data made openly available by OpenShift and Kubernetes CI platforms.
Problem Definition
One major component of the software development and operations workflow is Continuous Integration (CI), which involves running automated builds and tests of software before it is merged into a production code base. For example, if you are developing a container orchestration platform like Kubernetes or OpenShift, these are huge code bases with large builds and many tests that will produce a lot of data that can be difficult to parse if you are trying to figure out why a build is failing or why a certain set of tests aren’t passing.
OpenShift, Kubernetes and a few other platforms have made their CI data public. This is real world multimodal production operations data, a rarity for public data sets today. This presents a great starting point and a first initial area of investigation for the AI Operations (AIOps) community to tackle. The aim is to cultivate open source projects by developing, integrating and operating AI tools for CI by leveraging the open data that has been made available by OpenShift, Kubernetes and others.
Figure 2: AI4CI
Data Engineering
Before we attempt to apply any AI or machine learning techniques to improve the CI workflow, it is important that we know how to both quantify and evaluate the current state of the CI workflow. In order to do this we must establish and collect the relevant metrics and key performance indicators (KPIs) needed to measure it. This is a critical first step as it allows us to quantify the state of CI operations, as well as apply the KPIs we will need to evaluate the impact of our AI tools in the future.
There are currently five open datasets that can be used to help us fully describe the CI process: Testgrid, Prow, Github, Telemetry and Bugzilla. This data is currently stored in disparate locations and does not exist in a data science friendly format ready for analysis. In the data engineering phase, we focus on collecting the data from these different sources and storing them in Ceph, exploring the data, creating tables in Trino database and visualizing the data using Apache Superset and preparing the data for model development.
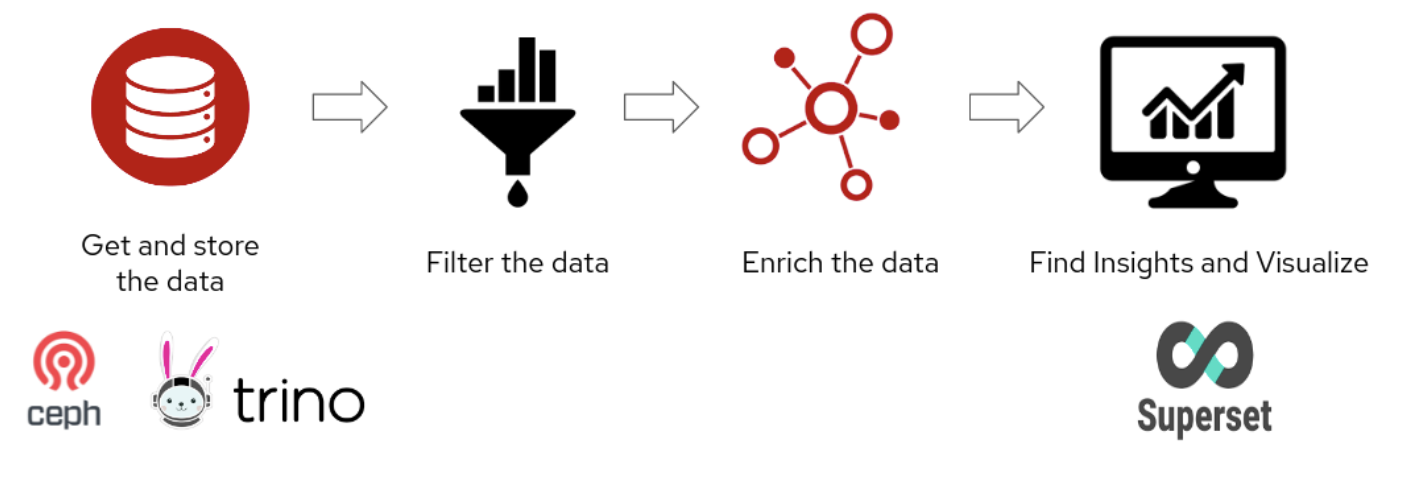
Figure 3: Data Engineering Phase
Model Development
With the data sources made easily accessible and with the necessary metrics and KPIs available to quantify and evaluate the CI workflow we can start to apply some AI and machine learning techniques to help improve the CI workflow. There are many ways in which this could be done given the multimodal, multi-source nature of our data. Instead of defining a single specific problem to solve, our current aim is to curate a hub for multiple machine learning and analytics models centered around this data focused on improving CI workflows. Below is a list of the current ML and analytics models.
GitHub Time to Merge Prediction
To quantify critical metrics within a software development workflow, we can start by calculating metrics related to code contributions. One such metric which can help identify bottlenecks within the development process can be the time taken to merge an open pull request. By predicting the time that it could take to merge a PR, we can better allocate development resources.
We would like to create a GitHub bot that ingests information from a PR (Pull Request), including the written description, author, number of files, etc, in addition to the diff, and returns a prediction for how long it will take to be merged. For that, we train a model which can predict the time taken to merge a PR and classify it into one of a few predefined time ranges. To train this model, we use the features engineered from the raw PR data. We explored various vanilla classifiers, like Naive Bayes, SVM, Random Forests, and XGBoost. We use Jupyter notebooks to train the model. You can take a look at our model training notebook in our project repository for more details.
TestGrid Failure Type Classification
Currently, human subject matter experts are able to identify different types of failures by looking at the test grids. This is, however, a manual process. This project aims to automate the manual identification process for individual Test Grids. This can be thought of as a classification problem aimed at classifying errors on the test grids as either flakey tests, infra flakes, install flakes or new test failures. We use Jupyter notebooks to train the model. You can take a look at our model training notebook in our project repository for more details.
Prow Log Classification
Logs represent a rich source of information for automated triaging and root cause analysis. Unfortunately, logs are very noisy data types, i.e, two logs that are of the same type but from two different sources may be different enough at a character level that traditional comparison methods are insufficient to capture this similarity. To overcome this issue, we will use the Prow logs made available to us by this project to identify useful methods for learning log templates that denoise log data and help improve performance on downstream ML tasks.
We start by applying a clustering algorithm to job runs based on the term frequency within their build logs to group job runs according to their type of failure. We use Jupyter notebooks to train the model. You can take a look at our model training notebook in our project repository for more details.
Optimal Stopping Point Prediction
Every new Pull Request to a repository with new code changes is subjected to an automated set of builds and tests before being merged. Some tests may run for longer durations for various reasons such as unoptimized algorithms, slow networks, or the simple fact that many different independent services are part of a single test. Longer running tests are often painful as they can block the CI/CD process for longer periods of time. By predicting the optimal stopping point for the test, we can better allocate development resources.
TestGrid is a platform that is used to aggregate and visually represent the results of all these automated tests. Based on test and build time duration data available on testgrid, we can predict and suggest a stopping point, beyond which a given test is likely to result in a failure. We use Jupyter notebooks to train the model. You can take a look at our model training notebook in our project repository for more details.
Model Deployment
Now that we have all our models implemented we can deploy them into a production environment. To make these machine learning models available at an interactive endpoint, we serve the model yielding the best results into a Seldon Core service. Seldon Core is an open-source framework that makes it easier and faster to deploy your machine learning models and experiments at scale on Kubernetes. Seldon Core serves models built in any open-source or commercial model building framework. You can make use of powerful Kubernetes features like custom resource definitions to manage model graphs. And then connect your continuous integration and deployment (CI/CD) tools to scale and update your deployment.
To make the machine learning model available at an interactive endpoint, we serve the model yielding the best results into a Seldon service. You can take a look at one of our Seldon deployment configurations created to serve one of our models. We create a sklearn pipeline consisting of 2 steps, scaling of the input features and the model itself. The interactive model endpoints of some of the models can be viewed here:
We have also created model inference Jupyter notebooks to check whether the Seldon service is running as intended, and more specifically to ensure that the model performance is what we expect it to be. Some of the model inference notebooks can be found here:
- GitHub Time to Merge Model Inference Notebook
- Optimal Stopping Point Model Inference Notebook
Model Monitoring and Management
Model monitoring collects and stores data about the ML model behavior for data scientists so they can learn how models behave with real production data. With this information, data scientists can evaluate the models and take appropriate actions. Model monitoring and management involves:
Monitoring the Data - The data coming from the “real world” is beyond our control and presents unique challenges. Therefore, we need to validate that the incoming data sets are of expected format and that the data comes in acceptable ranges.
Monitor Model Performance - Software functionality tends to be binary — it works or it doesn’t. However, models are probabilistic. So you often can’t say definitively whether the model “is working”. However, you can get a good feel by monitoring model performance to check against unacceptable swings in core metrics such as standard deviation or mean average percent error.
Run A/B Tests - Models can drift to become worse than random noise. They can also (nearly) always be improved. Therefore, during operations, we should continue to routinely hold-out small portions of our population as a control group to test performance against the running model. Occasionally, we can develop and deploy new test models to measure their performance against the incumbent production model.
Ensure Proper Model Governance - Regulations in certain industries require organizations to be able to explain why a model made certain decisions. And even if you’re not in one of these regulated industries, you will want to be able to trace the specific set of data and the specific model used to evaluate specific outcomes.
Some of the open source tools we use at Red Hat for model monitoring include Seldon Core and Kubeflow. Seldon Core is an open source MLOps framework designed to streamline machine learning workflows with logging, advanced metrics, testing, scaling, and conversion of models into production microservices. Kubeflow is a full-fledged open source MLOps tool that makes the orchestration and deployment of machine learning workflows easier. Kubeflow provides dedicated services and integration for various phases of machine learning, including training, pipeline creation, and management of Jupyter notebooks.
Next Steps
There are a variety of different methods to solve a machine learning challenge. The model lifecycle, we have explained, illustrates the development of a model from identifying a need to taking a solution to deployment. To explain the model lifecycle in practice, AI for Continuous Integration is a direction that data scientists at Red Hat chose to tackle developing more intelligent CI/CD monitoring. Having good CI practices creates better communication and collaboration, more efficiency to identify bugs or errors, reduced meticulous and repetitive tasks, and many more.
To learn more about the model lifecycles, read the blog: Enterprise MLOps Reference Design. If you have questions, we would be happy to answer them. Please reach out to Kaitlyn Abdo and/or Hema Veeradhi.
About the authors
More like this
Why your AI agent framework isn't enough: 7 platform capabilities missing from production
Why Operational Resilience and Digital Sovereignty Top the CIO Agenda
Technically Speaking | Defining sovereign AI with open source
Technically Speaking | Inside open source AI strategy
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds