
Introduction
A highly-available deployment of OpenShift needs at least two load balancers: One to load balance the control plane (the master API endpoints) and one for the data plane (the application routers). In most on-premise deployments, we use appliance-based load balancers (such as F5 or Netscaler).
The architecture looks like the following:

In this architecture, we have two Virtual IP Addresses (VIP) (one for the masters and one for the routers) that are managed by a cluster of appliance-based load balancers via the VRRP protocol. One load balancer is active, the other(s) are on standby.
Recently a customer asked me to provide a load balancer solution that did not include an appliance load balancer, but that was based purely on supported open source software.
I’d like to share my research on architectural approaches for load balancing in front of OpenShift with open source load balancer solutions. For those who are looking for good foundational concepts on load balancing, this is an excellent article.
VIP and L7 load balancer
The first and most documented approach to solve this problem is an architecture with a VIP and a set of Layer 7 (hereby layer we are referring to the OSI network model layers) load balancers such as HAProxy or Ngnix in active and standby configuration.

For simplicity, this picture only shows load balancing on the masters.
The Layer 7 (L7) proxy should be configured with passthrough mode for both the masters and the routers.
Architecturally this configuration is equivalent to the appliance-based one. An appliance-based solution is better from several other points of view such as optimized hardware, management CLI, and UI, monitoring tools.
The VIP in our open source solution is realized via Keepalived, which is a service in Linux that uses the VRRP protocol to create and manage a highly-available IP. This highly available IP (or VIP) is advertised by the active member of the keepalived cluster via the Address Resolution Protocol (ARP), so any packets, whose destination is the VIP, will be delivered to that member of the cluster.
If the active member crashes or becomes unavailable, the VIP is moved to another member of the cluster which becomes active.
A good load balancer will perform health checks on the instances it is load balancing to. If an instance is not available, it will be removed from the pool of the active instances and it will not receive any traffic from the load balancer. HAProxy and Nginx both have support for health checks.
VIP and L4 load balancer
Analyzing the needs for the load balancers in front of OpenShift, a Layer 7 load balancer is not needed: we can use a Layer 4 load balancer. All the layer 7 processing is done at the master or router level. A layer 4 load balancer is more efficient because it does less packet analysis.
HAProxy and Nginx can act as L4 load balancing, but Keepalived can also do that via IP Virtual Server (IPVS). IPVS is an L4 load balancer implemented in the Linux kernel and is part of Linux Virtual Server (LVS). So, we can simplify the previous architecture as follows (again this picture is only showing the masters, this applies to the routers on the infranodes):

Keepalived health checks are not as configurable as HAProxy or Nginx, but we can still create sufficient health checks by passing in a custom script.
Unfortunately, keepalived has a limitation where the load balanced servers cannot also be the client (see here, at the bottom of the page). This prevents the masters (which need to be client of themselves) from using this architecture. For the masters we have to keep using the architecture presented in the previous paragraph.
Self-hosted load balancer
The machines and processes used in the above options still need to be monitored and patched/upgraded. This type of thing is where OpenShift excels, so ideally we would like to run the Keepalived processes as pods inside it.
The issue with running the master’s load balancer as a pod is that the load balancer is a prerequisite for the cluster to work. One way to work around this issue is to create the Keepalived processes as static pods so they will start even before the node is registered to the masters. This diagram shows the self-hosted load balancer.
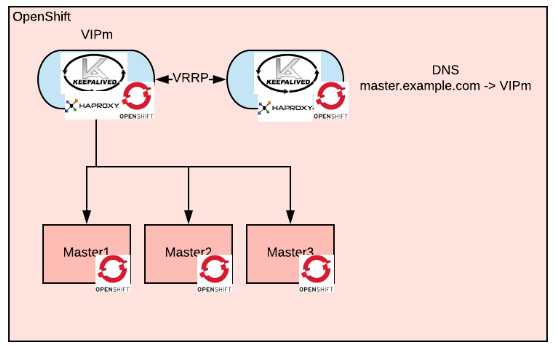
This approach is philosophically aligned with the Kubernetes way.
For the infranodes the architecture would look as follows:
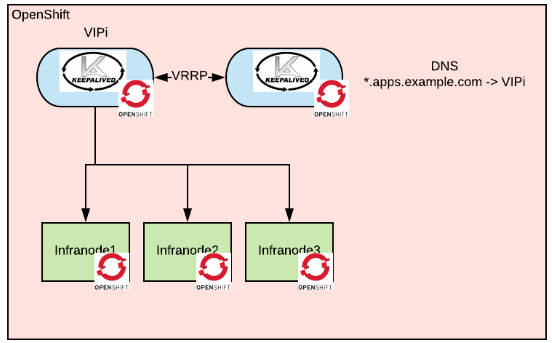
Thanks to the fact that now the processes are running as pods, they inherit all of the monitoring and metering capabilities that are present in the OpenShift cluster, this compensates for some of the management capabilities that we have lost by switching to opensource.
Performance considerations
In the previous picture, the load balancers nodes are separated from the load balanced servers. If you don’t anticipate having a significant load, which is almost always the case for the masters, you can deploy the load balancer pods directly on the nodes that you need to load balance. This allows for reducing the number of nodes of the cluster.

Note that for this configuration the OpenShift master api service will need to be bound to the host-specific IP and not any IP (0.0.0.0) as it is by default.
Conversely, if you anticipate significant load, as it may be likely for the routers, here are some performance tuning considerations.
Use two NICs
Keepalived can be configured to ingest traffic from on Network Interface Controller (NIC) and load balance it using a different NICs, this will prevent a NIC from saturating.
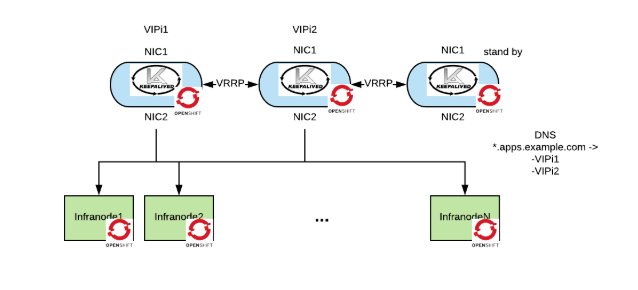
Split the traffic across multiple active load balancers
So far we have always used the active - standby approach. This means that all the network traffic goes to one of the load balancers instance. By adding VIPs we can spread the traffic across multiple active instances. In order for this to work, the corporate DNS will have to be configured to return one of the VIPs.
This picture shows the discussed optimizations:
Google Maglev Load Balancer
The previous architecture should allow you to manage a very large traffic workload. But what if you need to support a web-scale workload?
Google published a load balancer design paper that explains how to create a horizontally scalable load balancer in which each load balancer instance can achieve a 10Gbps throughput using commodity Linux hardware. This load balancer is called Maglev and was released publically under the project name seesaw. This system can scale to very high loads but relies on a few uncommon networking setups and therefore the level of effort to implement this solution may not be worthwhile unless you really need to support a web-scale deployment.

The main architectural ideas that Maglev introduces are the following:
Maglev uses an anycast VIP. In anycast, several servers advertise the same VIP to an edge router, which chooses one of them when it routes an IP packet. IPv4 does not support this mode natively (IPv6 does), but it can be implemented using the Border Gateway Protocol (BGP) with equal Equal-Cost Multi-Path (ECMP) for all the destinations. This provides theoretical unlimited horizontal scalability of the load balancer layer. Anycast will typically work only with edge routers that can interpret BGP.
Maglev does not use the kernel stack for processing network packets, it processes packets directly from the NIC in userspace. Not going through the kernel TCP/IP stack allows the code to be very efficient and focused. The most expensive operation is deciding where to send the packet (especially when you have a very large battery of servers to load balance to). Google uses a specialized hashing algorithm for this task.
Only inbound packets are routed. Return packets are sent back to the edge router directly by the load balanced servers (the OpenShift routers in this picture). The reason for this choice is that typically the return flow is ten times larger than the inbound flow and therefore much more bandwidth and computation power can be used to route the inbound packets. This setup is also known as Direct Server Return and requires some additional network configuration. Each load balanced server must also expose the VIP but must not advertise it on the network via the ARP protocol. Arptables (or other mechanisms) can be used to filter ARP broadcasts for the VIP. With direct server return, the only thing the router needs to do is to change the mac destination address in the data link frame and retransmit the packet.
Keepalived can also work in this mode, but I intentionally didn’t consider it in the above sections because, as said, this mode requires an unusual networking setup.
Each tier of this architecture load balances at a different layer of the OSI model. The edge router load balances at layer 3 because of the anycast setup, the maglev router load balances at layer 4, and the OpenShift routers load balance at layer 7.
I haven’t tried to containerize Seesaw and deploy it as a static pod in OpenShift, if you do please let me (rspazzol@redhat.com) know.
Conclusions
If you run OpenShift in the cloud, your cloud provider will give you an API-based elastic load balancer. If you run OpenShift on-premise and want to use open source software and commodity hardware to create your load balancers, this article shows a series of architectural approaches that you can consider. The self-hosted solution is probably the most versatile and the one I’d recommend. If you need to manage web-scale load you might want to consider the Maglev load balancer.
執筆者紹介
Raffaele is a full-stack enterprise architect with 20+ years of experience. Raffaele started his career in Italy as a Java Architect then gradually moved to Integration Architect and then Enterprise Architect. Later he moved to the United States to eventually become an OpenShift Architect for Red Hat consulting services, acquiring, in the process, knowledge of the infrastructure side of IT.
Currently Raffaele covers a consulting position of cross-portfolio application architect with a focus on OpenShift. Most of his career Raffaele worked with large financial institutions allowing him to acquire an understanding of enterprise processes and security and compliance requirements of large enterprise customers.
Raffaele has become part of the CNCF TAG Storage and contributed to the Cloud Native Disaster Recovery whitepaper.
Recently Raffaele has been focusing on how to improve the developer experience by implementing internal development platforms (IDP).
類似検索
エージェント型のパラドックスとハイブリッド AI の事例
過去を管理するのをやめて、IT の未来を構築しましょう
Crack the Cloud_Open | Command Line Heroes
Edge computing covered and diced | Technically Speaking
チャンネル別に見る

自動化
テクノロジー、チームおよび環境に関する IT 自動化の最新情報

AI (人工知能)
お客様が AI ワークロードをどこでも自由に実行することを可能にするプラットフォームについてのアップデート

オープン・ハイブリッドクラウド
ハイブリッドクラウドで柔軟に未来を築く方法をご確認ください。

セキュリティ
環境やテクノロジー全体に及ぶリスクを軽減する方法に関する最新情報

エッジコンピューティング
エッジでの運用を単純化するプラットフォームのアップデート

インフラストラクチャ
世界有数のエンタープライズ向け Linux プラットフォームの最新情報

アプリケーション
アプリケーションの最も困難な課題に対する Red Hat ソリューションの詳細
仮想化
オンプレミスまたは複数クラウドでのワークロードに対応するエンタープライズ仮想化の将来についてご覧ください