You have established a code base to change and put together a team with the right mix of innovation and enterprise knowledge to change it. You’ve selected a tool to track work and have some ideas of what work to do with the code. How does the team start producing results?
Safely changing software with feedback loops
Product feedback loops allow for a product to evolve after that first deployment while maintaining the key metrics expected of the application by its users.
Below is a commonly referenced software feedback loop:

Let's review each of these steps while adding some details I think are often missed.
Build: Must include experimentation
In the context of migrating legacy software, “build” also includes “changes to existing software.” When building or changing, sometimes it's not always clear exactly how things should be built or changed.
This means there must be experimentation in the build phase. This is not a sign of incompetence—experimentation should be expected and planned for.
This experimentation results in a loop within the build step; the outcome of this loop helps to determine what gets built. The code in this experimentation loop might not be the code the team is trying to modernize. It could be one-off samples that test capabilities the team is considering.
From a task-tracking point of view, sometimes this sort of experimental work will be labeled with the tag "Spike."
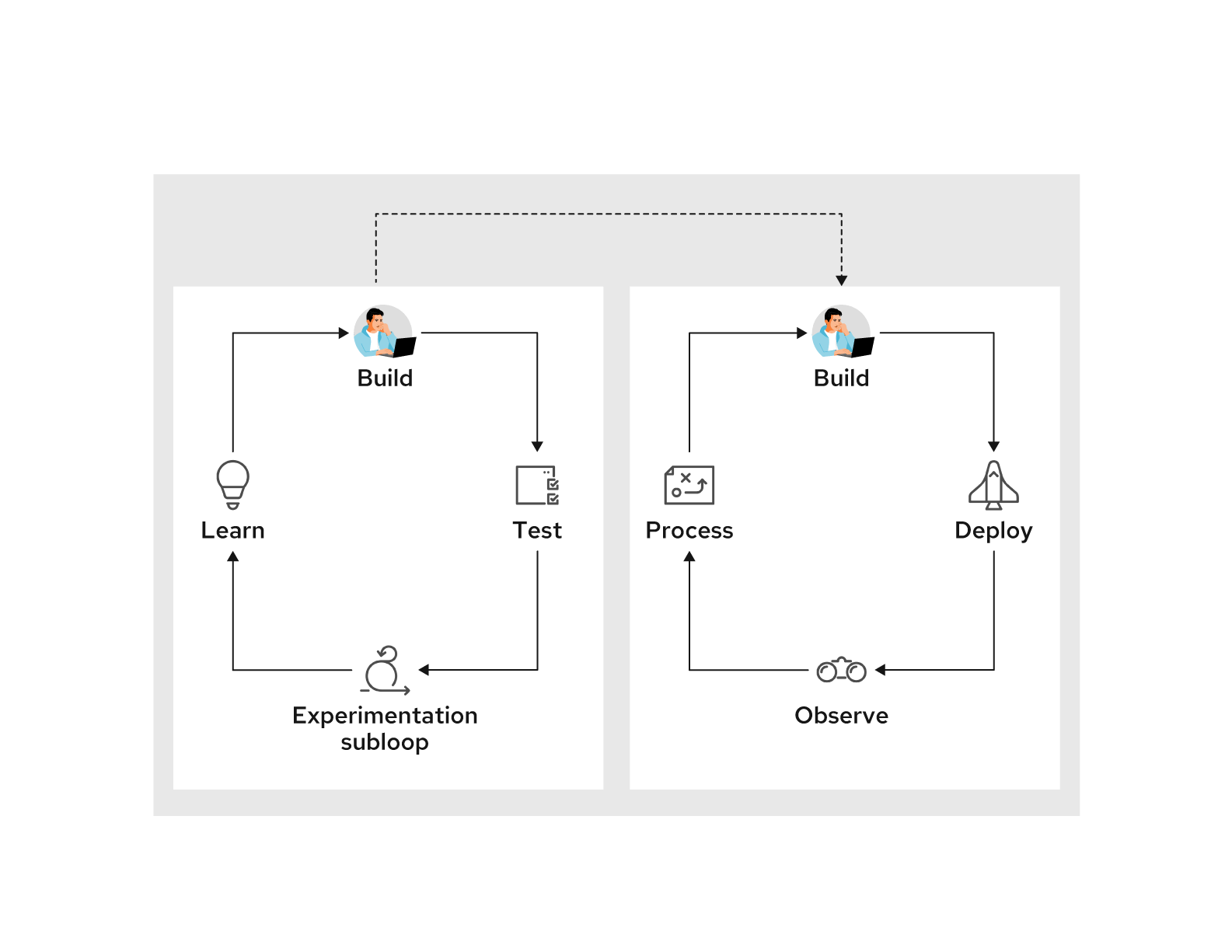
If the experimental sub-loop hits issues or slows down, it will impair the team's ability to move forward in the project. For example, the team might be experimenting with different libraries and approaches for integrating an OAuth2 flow into a collection of applications. They might do this by deploying a collection of simple services with different OAuth2 approaches and then testing different scenarios. If this experiment is slowed down or blocked (e.g., deployment is difficult and logs are not easily obtained), the team won’t have a security approach they are comfortable with. This could result in the main build process (which is working with the actual application code) becoming frozen.
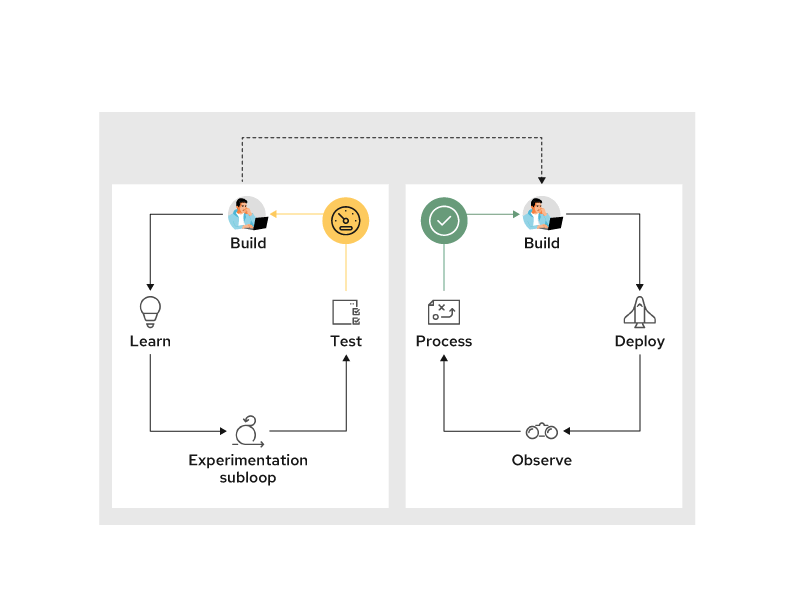
When to experiment?
It’s also important to know when it’s appropriate to experiment. The Project Lead can determine whether an experimentation phase is going to turn into a science experiment by asking the following questions:
- Does this help the project goal?
- Is this something that can go to production in this enterprise?
- Is this something the enterprise can operate?
The Project Lead should be empowered to stop work when experiments are starting to become misaligned with the project’s goals.
The goal coming out of the build phase should be deployable artifacts: There should be multiple artifacts at any given moment, depending on what the team is working on.

Deploy
In my experience, the best teams automatically deploy the application artifact to a development environment triggered by a code check-in (provided the code builds properly). From there, this artifact is promoted to higher environments (moving toward production), with the environments and services becoming as close in parity to production as possible.
Again, there are multiple builds generally running in the lower-level environments, with the release version (deemed most stable and feature-complete) running in production.
If there are challenges, delays or complexity around the deployment and/or the configuration, the success of the experimentation subloop—as well as the main product loop—will suffer. Deployments should be effortless for the product team and happen as frequently as they need.
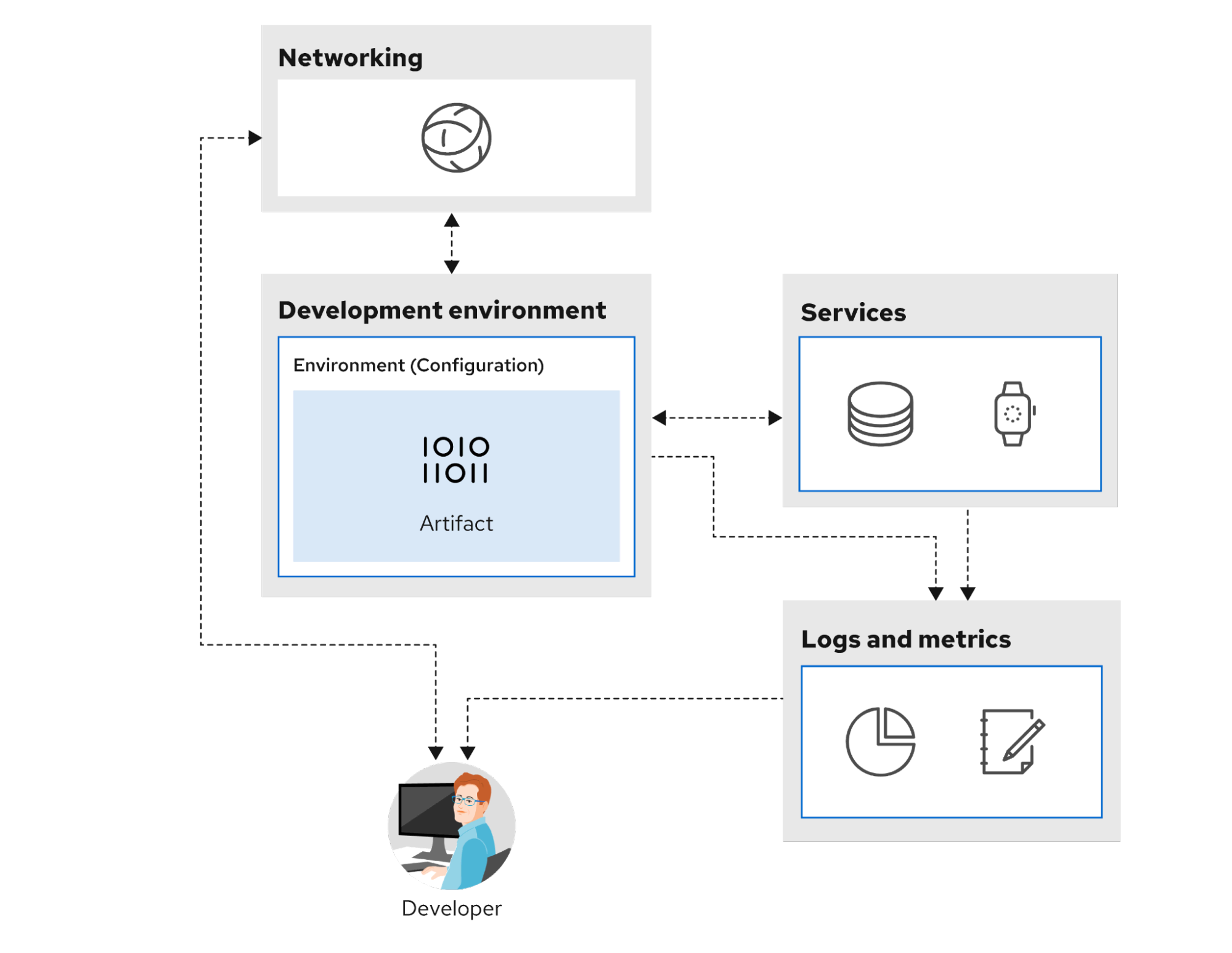
Externalizing configuration
When it comes to deployment, it’s worth revisiting the 12 Factors to help make code more deployable. Factor 3 refers to storing the config in the environment and not in the code (it's possible to use config files if a concept like profiles can be implemented). The goal is to take the same code base and move it from environment to environment on your way to production by changing only the configuration.
Details, such as connecting to a database, should be ideally obtained through environment variables or a service like Vault. However, in many enterprises, something like Vault may not be available, and security practices might prohibit storing credentials in a variable environment.
In a situation where getting access to Vault took too long, a team I worked with created a utility class that encrypted/decrypted strings stored in the environment. Although better than storing data in clear text in environment variables, even this approach may not get approved by security teams in certain environments.
This is where the Wise Sage will come in handy. You need someone with knowledge of security and production best practices in that particular enterprise to be a guide. The goal is to be able to set or update the configuration of the application without having to change the code, retest, rebuild and then redeploy.
Observe
Now that a version of the application is deployed into an environment, the exact changes the team has been building can be tested. It’s quite likely that while making a significant change, the first few deployments could fail. But if you can measure it, you can improve it. As long as a team can trigger an error or issue and obtain the right feedback, it should be possible to create a plan to put improvements in place.
A typical cycle might look like this:
- A developer adds or changes code and/or configuration in the codebase.
- Extra logging is added around the new or changed code.
- The code is deployed.
- A behavior is elicited in the deployed code.
- The logs and metrics are reviewed.
In this case, everything that the application needs has been provisioned and wired up for deployment. There should be no friction about obtaining everything the build needs to run—otherwise, the team will not be able to generate activity to observe.
There should also be simple/direct paths to obtaining logs and tools in the environment, or permission to install tools, allowing the teams to get environmental and application-level metrics.
Process
Now that the team has observed the effects of their changes or experimentation, an alignment-based decision can be made. This decision could be on further work, or to promote an existing build to a higher-level environment, getting it closer to production.

To avoid unproductive outcomes at this step, the teams must have access to information and be able to come to agreement. If an effective product team has not been created, there will always be issues at this step. Luckily, you have already put together the ideal team for this enterprise!
Create, release and verify deployments as you go
The goal is to keep the code changes in a release small. If something breaks, it will be easier to find out what it is. The worst-case scenario is that many changes are made, the application breaks, and no one knows which change broke it.
But a key tool that will help you keep changes from breaking the code is still missing.
Building out the tests
In my previous blog post, I recommended that you organize functionality by package, break that functionality up into the appropriate stereotypes, and simplify and encapsulate the logic. Now, if you are following TDD (test-driven development) methodology, you should already have tests of some sort. However, it's not unheard of for legacy applications to not have unit test coverage (testing might have been done by a quality assurance team in a manual fashion). Either way, the goal now is to build up the quality of the unit tests (or add them if missing).
The plan is simple: Start at one end of the stack—controllers or POJOs—and work your way to the other side.
For example, in the test below I’m testing the CompanyResource (which is a controller). As my experience is with the Spring Framework, this example will use annotations from that. But if you are not a Spring Framework user, fear not. Most mature frameworks have similar equivalents.
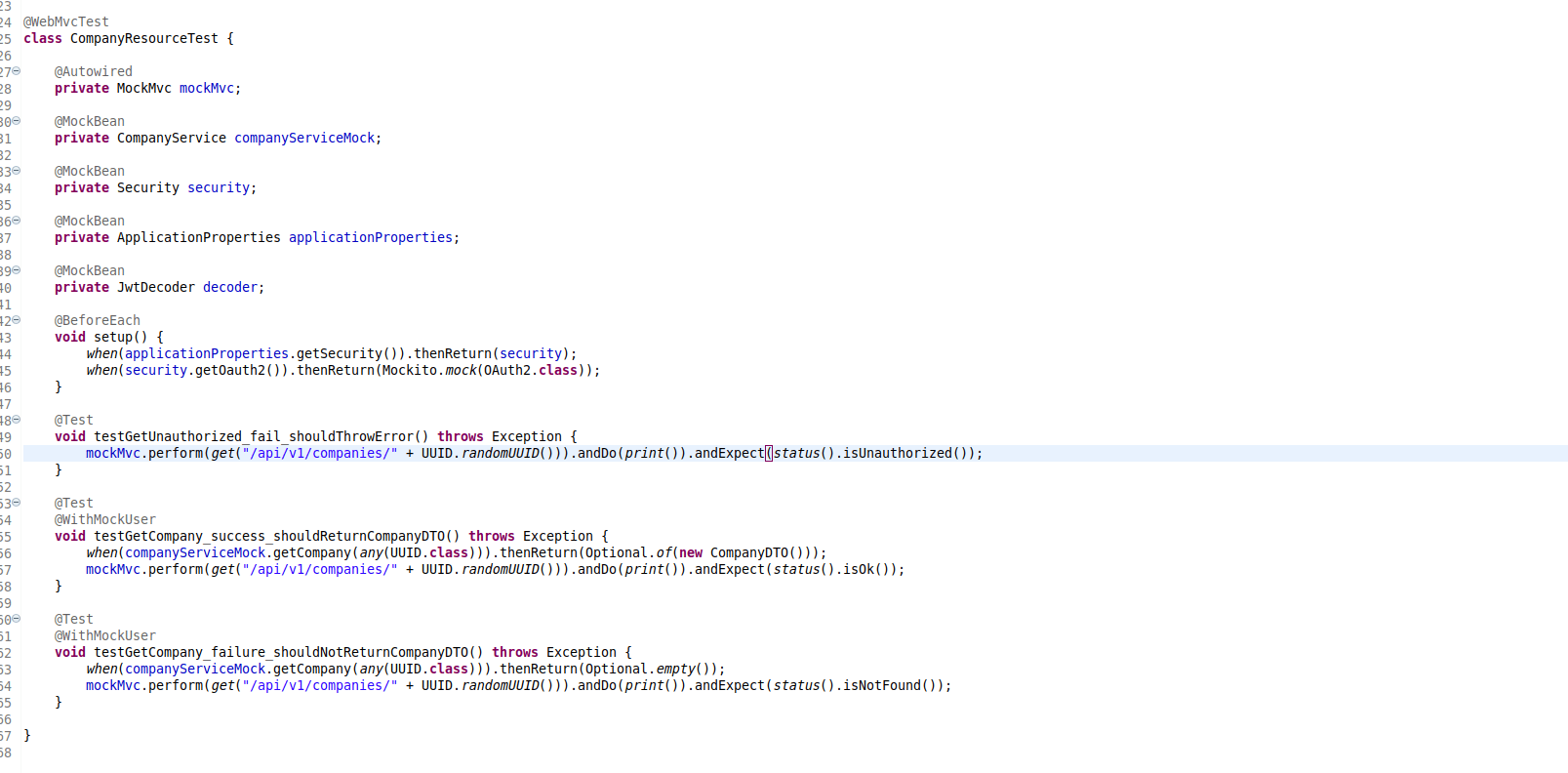
The annotations are from Spring Boot (an opinionated approach to utilizing the Spring Framework). In this instance, I use @MockBean to ask Spring to put a Mock in for that dependency. In this case, even if there is a reference that exists, it will be replaced by a Mock (this is an implementation of the object that is the correct type, but contains no logic). This means I have now isolated the code I’m trying to test from the logic/dependencies that might be introduced by the reference that was mocked.
Using Mockito, I can then decide to have the Mock object behave in different ways (e.g., throw an error, provide the expected result, give incorrect data) across a suite of tests to see how my logic holds up.
Let’s look at the service layer to see an example of this.
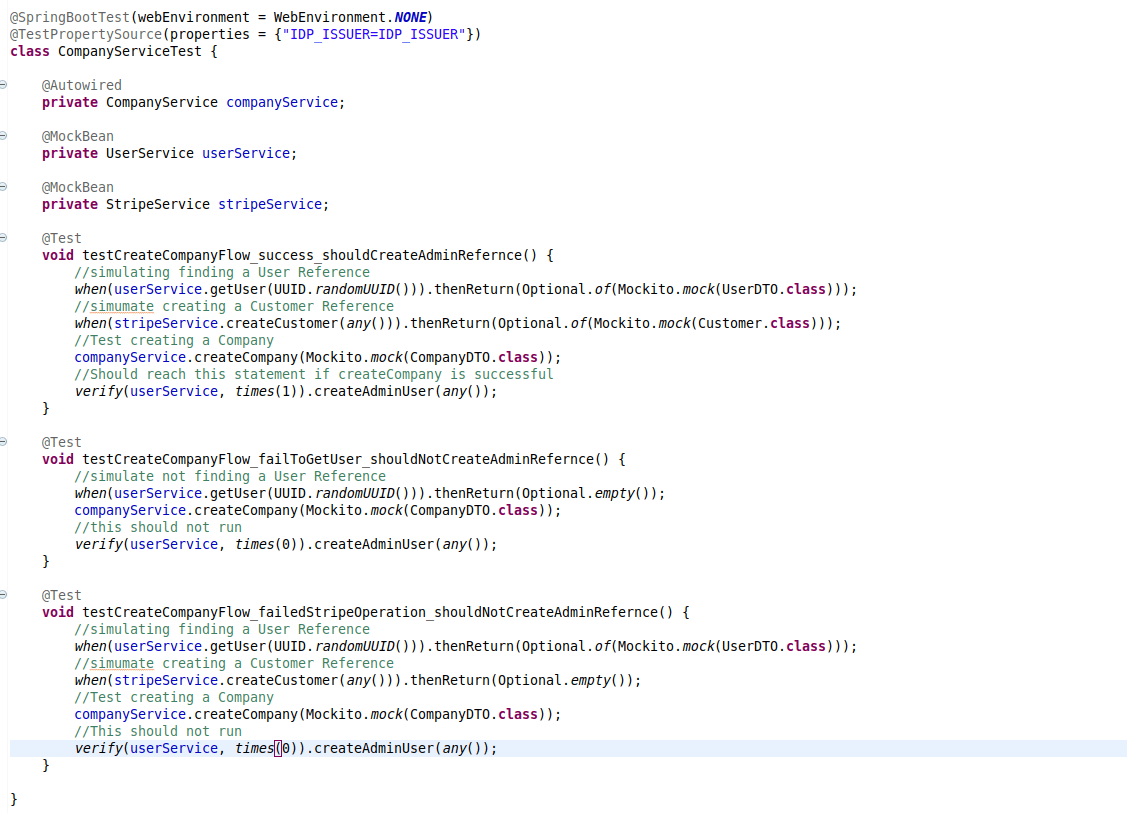
Logic in the service, specifically around the logic to create a company, is being tested. For this to succeed, I need to find a user associated with the company, then make a successful call to Stripe (a payment processor). If both succeed, I can add a “Create an Admin” user reference.
User references are in a database; Stripe is a third-party product. Remember, the goal is for the test to run without needing any outside dependencies.
Since all of this logic is encapsulated correctly, I’m able to mock those calls out to simulate if the logic I am testing (creating a company) behaves as I expect for some potential responses I might get.
Is this test perfect? Can I be totally assured the logic will never fail? No, of course not. But it's a good start that can be improved upon over time.
What are best practices for writing a test?
There are a lot of good blogs on best practices for writing a test. This post on JUnit makes a lot of sense to me.
Keep in mind some of these high-level guidelines while writing your test:
- Test one thing at a time.
- Keep assertions simple and to a minimum.
- Tests should be able to run independently of one another.
- Keep naming clear and concise.
The guidelines for writing test code should be clearly explained in the project’s principles and practices documentation (created by the Project Lead as described in a previous blog).
How many tests are enough?
This is an interesting question, and really one that should be answered by the team. There are some tools that can help frame your thinking about this. EclEmma is a great Eclipse plugin that wraps JaCoCo. It tests your instructions to see what level of coverage you have.
It's tempting to try and get to 100% coverage, but the value of doing that may not be worth the effort. Also, it really comes down to the quality of the tests.

The report shown above is on a package (feature). The coverage seems pretty bad, but it's possible that the most important logic is covered in this eight percent, meaning the team can move on to other important logic (and come back to this later).
If the application has no tests (i.e., it has only been tested manually by a QA team), the best approach might be to take passes at it to slowly improve it. A small collection of well-written tests is more valuable than a bunch of low-quality ones.
Getting more feedback
All the work to this point requires lots of deployments. In some cases, multiple team members will be deploying different artifacts in their own branches of the same code base.
Sometimes, the whole point of a deployment is to add some new logging statements so that the next time an error is simulated, key clues are obtained. Nothing kills this problem-solving loop faster than making it hard to deploy and get logs.
It’s useful to set up the pipeline as soon as possible, which will necessitate two things:
- Logs
- An APM tool
Logs
Ideally, you should be able to easily add logging information to the code, deploy it, and get access to the logs. You DO NOT want a bunch of logging in production because it will be a nightmare to sort the signal from the noise should a real issue arise.
From a deployment point of view, you want to ensure you use a logging framework that
- Is easy to add to the code
- Is easy to use
- Can set the specificity of the logging statements without redeploying the application
The Project Lead will decide what to use for this—my personal favorite is Lombok which also reduces boiler plate code in POJOs. Newer versions of Java contain this type of functionality, however, if you are unable to upgrade to a newer version, Lombok works well with older versions of the JDK.
However, you need to ensure the team does not log personal information (PI) data, such as customer ID or account numbers, into the logs. While the intention might be to turn it off in production, I have seen such logging accidentally promoted to production. In a public cloud environment where external hackers have more attack vectors, this can be a disaster.
Metrics
Finally, you will want to add something to the application that gives real-time insights into the application itself, such as
- Heap memory
- Long pauses in garbage collection
- Percentage of HTTP errors
- Thread counts
- Native memory
Ideally, the enterprise already uses something like Dynatrace, AppDynamics, or New Relic. If not, there are open source solutions that can be used. One example is Prometheus. In an enterprise, it may be challenging to get such a tool approved for production workloads; however, in a situation where there is no approved tool, something like this should be at least added to the dev environment so the team can get the feedback they need.
If the application has a UI, a tool like LogRocket can be invaluable. This allows you to replay the sessions of users who have issues to see if they are clicking or inputting what they tell you they are.
So far, this probably all sounds good. Except this is a legacy enterprise environment. All this work around getting infrastructure to deploy to, getting logs, and setting up tools is often done by another team. We'll discuss that in our next article.
Application modernization series
執筆者紹介

Luke Shannon has 20+ years of experience of getting software running in enterprise environments. He started his IT career creating virtual agents for companies such as Ford Motor Company and Coca-Cola. He has also worked in a variety of software environments - particularly financial enterprises - and has experience that ranges from creating ETL jobs for custom reports with Jaspersoft to advancing PCF and Spring Framework adoption in Pivotal. In 2018, Shannon co-founded Phlyt, a cloud-native software consulting company with the goal of helping enterprises better use cloud platforms. In 2021, Shannon and team Phlyt joined Red Hat.
チャンネル別に見る

自動化
テクノロジー、チームおよび環境に関する IT 自動化の最新情報

AI (人工知能)
お客様が AI ワークロードをどこでも自由に実行することを可能にするプラットフォームについてのアップデート

オープン・ハイブリッドクラウド
ハイブリッドクラウドで柔軟に未来を築く方法をご確認ください。

セキュリティ
環境やテクノロジー全体に及ぶリスクを軽減する方法に関する最新情報

エッジコンピューティング
エッジでの運用を単純化するプラットフォームのアップデート

インフラストラクチャ
世界有数のエンタープライズ向け Linux プラットフォームの最新情報

アプリケーション
アプリケーションの最も困難な課題に対する Red Hat ソリューションの詳細
仮想化
オンプレミスまたは複数クラウドでのワークロードに対応するエンタープライズ仮想化の将来についてご覧ください