
Our Journey Continues
If you’re just joining us now, it would be well worth your time to read the first 3 parts of the series. Go ahead, we’ll wait for you. I promise.
Part 1 - Intro
Part 2 - Turning Knobs
Part 3 - Thanks for the Memories
Today, we’re going to look at the storage controller and what we can do in terms of block I/O. This is an interesting one to me, because now we’re really getting into territory where changes we make once a system is live are not nearly as important as the decisions we made prior to deployment.
Foundations. They’re Pretty Important
Here’s an image I include in any of my presentations that talk about performance or resource management.
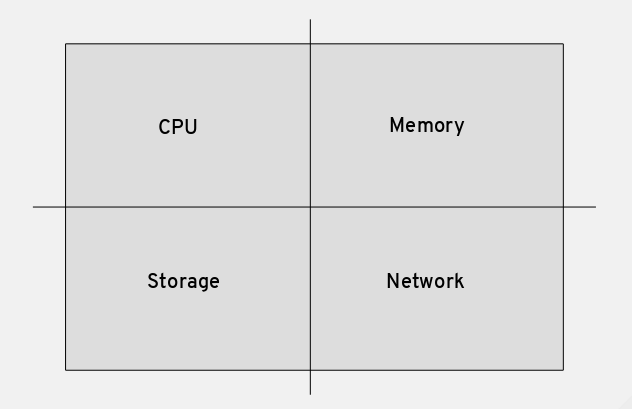
In the graphic, we see the four major resources that a modern computer requires for it to fully function. Tuning performance is often a fine art of making sure that we allocate these resources in a balanced manner appropriate for each application process. However, we also need to keep in mind that none of the resources are limitless and not all of them are equal in terms of impact.
Storage performance comes down to the underlying technology, all of which have vastly different characteristics: spinning platters, SSD, network attached storage, SAN. All of these can vary wildly in terms of access speed and throughput. A very fast computer with lots of memory can be completely hobbled if the storage devices aren’t up to the task.
If you, as the Linux expert, can be involved in the decisions around hardware for your environments, then ensuring that your organization is using an adequate (or awesome) storage platform will result in far less pain down the road.
Ok, I’ll climb off my soapbox now. Let’s check out what the I/O controller can do for us.
It’s All About the Devices
The formal name of the I/O controller is “blkio”, although he may respond to “Blocky” if he’s in a good mood. Much like the CPU controller, Blocky has two different modes of operation:
-
Relative I/O shares - you can balance performance against all block devices or a subset using values from 10 - 1000. The default is 1000, so the changes you will make are to basically reduce I/O shares to certain users or services. Why this scale rather than the arbitrary values defaulting to 1024 like the CPU controller? Good question. Sometimes the open nature of Linux works against itself, I suppose.
-
Absolute bandwidth - you can cap read and/or write bandwidth for a service or user. This behavior is off by default.
Here are the exposed options we can set via systemctl. (We can see valid options via the magic of tab-completion. If you don’t have the bash-completion RPM installed, you really should. It expands the ability of tab to complete commands mid-way through issuing them.)

Relative I/O shares are controlled by BlockIODeviceWeight and BlockIOWeight. Mouthfuls, I know. One very important thing to know before trying to use either of these settings is that they will only work if the CFQ I/O scheduler is enabled on a device.
…
Stop looking at me like that. I guess I should spend some time talking about the I/O scheduler.
Let’s get nerdy. As we (hopefully) already know, the Linux kernel is responsible for making all the little hardware bits of our computer talk to one another properly. Since many components are all trying to get things done at the same time, the kernel needs some way of managing this workflow. And that makes sense, it’s rather like our regular day-to-day lives...we need to juggle working, sleeping, eating, playing Skyrim and all that other good stuff.
For storage devices, the kernel relies on the I/O scheduler. This is code that determines the best way to manage data flow for block devices, which includes everything from USB sticks to hard drives to virtual hard drives which are really a file to SAN connections to ISCI devices...well, yeah. As I pointed out earlier, there’s a host of different storage technologies that Linux users can choose from.
On top of all the different devices we can use, there are also different jobs we ask our computers to handle. At Red Hat, we like the term “use cases”. Because of this, there are a few different schedulers available, and the best one to pick for your environment can vary. They are named “noop”, “deadline” and “cfq”. In general terms we can say this about them:
-
Noop is a good choice for memory-backed block devices and other non-rotational media (flash).
-
Deadline is a lightweight scheduler which tries to put a hard limit on latency. Read batches take precedence over write batches by default, as most applications tend to block on reads.
-
Cfq tries to maintain system-wide fairness of I/O bandwidth. As we’ve already noted, it’s the only I/O scheduler that supports the weighted I/O option for cgroups.
You can read more about the schedulers in the Red Hat Enterprise Linux 7 Performance Tuning Guide.
I say all of this because most systems do NOT default to cfq unless they are using a SATA based device. Unless you understand this requirement, you could be sitting there trying to adjust BlockIOWeight settings and seeing nothing happen. Unfortunately, systemd won’t tell you “hey Marc, sorry. You’re trying to set a parameter and the device is using the wrong scheduler. I’m just gonna sit over here while you rage and scratch your head.” With that said, please don't take this as a chance to take a cheap shot at systemd. Thanks!
You may also wonder how I knew about this limitation (other than trying to use it and things just failing). Well, this is actually covered in the kernel documentation for cgroups, which I explained how to install towards the end of my last blog. It’s always a good step to check out the documentation for the specific controllers that you might be planning to use.
Waddling Into a Use Case
Now that we’ve had that litt
Mr. Quackers runs a feed company and has an application server that runs two databases that track delivery requests. He demands that the database tracking duck feed is far more important than the database tracking goose feed, as geese are pretenders to the throne of True Waterfowl. Hey, he’s a duck. Don’t question his sanity.
We have both databases set up as services. Here are their unit files:

In the interest of being honest, the scripts referenced (duck.sh and goose.sh) don’t actually do real database work. Instead, they alternate writes and reads using a dd loop. Both of them use the /database filesystem, which is it’s own virtual disk.
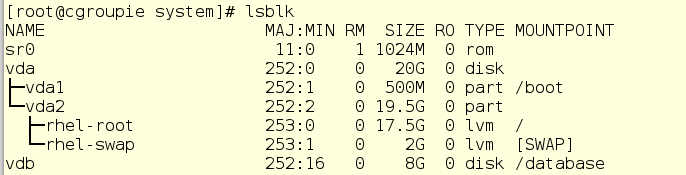
Let’s start up duck and goose and see where they land in the cgroup hierarchy:


And now we’ll take a peek at iotop (since we have the PIDs of the dd processes) to see what’s going on with the storage subsystem:

I realize that 12-14 M/s doesn’t seem very fast. Mr. Quackers doesn’t spend a whole lot of money on enterprise storage because (get ready for it) he hates paying the bill. Get it? He’s a duck and they have….anyway…..
Looking at our two database jobs, they are PID 3301 (goose) and 3300 (duck). They show as each using around 6 M/s in I/O - they vary, trust me on this one. In essence, they are sharing the bandwidth on the device.
Mr. Quackers wants duck to get at least 5 times the I/O time as goose, as this will ensure that the ducks get all of their feed deliveries first. If we could use BlockIOWeight, the following commands would work:

However, looking at iotop, that didn’t actually work:

Let’s check the I/O scheduler for /dev/vdb:

Oh my.
We try to change the I/O scheduler to cfq and it doesn’t work. Why?
Well, this system is running on a KVM virtual system and it turns out that starting with Red Hat Enterprise Linux 7.1, we can’t pick a scheduler. This is actually not a bug, but a design decision made due to improvements in the handling of virtualized I/O devices.
But all is not lost. We have two other parameters we can change: BlockIOReadBandwidth and BlockIOWriteBandwidth work at the block device level, ignoring the I/O scheduler. Since we know the expected throughput /dev/vdb can handle (around 14 M/s, give or take) if we go ahead and cap goose to around 2 M/s, we’ll achieve what Mr. Quackers wants. It requires understanding the capability of our environment and calculating the change based on observed behavior, but it should get us to where we need to be. Let’s try it.
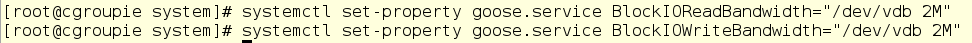

Look at that! PID 3426 (goose) is now using around 2 M/s of I/O. This has freed up duck (PID 3425) to gobble down almost 14 M/s. That’s a whole lotta feed! I’m glad we figured that out or else our goose might have been cooked.
Ouch. Sorry.
No More Ducks. Please.
With this blog, we’ve finished talking about the major cgroup controllers that are preconfigured for Red Hat Enterprise Linux 7. Next time, we’re going to head back in time just a little bit towards the end of 2010. In November of that year, our old friend Red Hat Enterprise Linux 6 was released. We will see how cgroups were configured and used during that era, which will also give you the concepts and tools you need to “roll your own cgroups” under Red Hat Enterprise Linux 7 today.

Marc Richter (RHCE) is a Technical Account Manager (TAM) in the US Northeast region. He has expertise in Red Hat Enterprise Linux (going all the way back to the glory days of Red Hat Enterprise Linux 4) as well as Red Hat Satellite. Marc has been a professional Linux nerd for 15 years, having spent time in the pharma industry prior to landing at Red Hat. Find more posts by Marc at https://www.redhat.com/en/about/blog/authors/marc-richter
A Red Hat Technical Account Manager (TAM) is a specialized product expert who works collaboratively with IT organizations to strategically plan for successful deployments and help realize optimal performance and growth. The TAM is part of Red Hat’s world class Customer Experience and Engagement organization and provides proactive advice and guidance to help you identify and address potential problems before they occur. Should a problem arise, your TAM will own the issue and engage the best resources to resolve it as quickly as possible with minimal disruption to your business.
執筆者紹介
Marc Richter (RHCE) is a Principal Technical Account Manager (TAM) in the US Northeast region. Prior to coming to Red Hat in 2015, Richter spent 10 years as a Linux administrator and engineer at Merck. He has been a Linux user since the late 1990s and a computer nerd since his first encounter with the Apple 2 in 1978. His focus at Red Hat is RHEL Platform, especially around performance and systems management.
類似検索
vi エディター入門
急激に進化する AI の脅威に対応する防御作とは
Container Roundup | Compiler
Untangling Networks | Compiler
チャンネル別に見る

自動化
テクノロジー、チームおよび環境に関する IT 自動化の最新情報

AI (人工知能)
お客様が AI ワークロードをどこでも自由に実行することを可能にするプラットフォームについてのアップデート

オープン・ハイブリッドクラウド
ハイブリッドクラウドで柔軟に未来を築く方法をご確認ください。

セキュリティ
環境やテクノロジー全体に及ぶリスクを軽減する方法に関する最新情報

エッジコンピューティング
エッジでの運用を単純化するプラットフォームのアップデート

インフラストラクチャ
世界有数のエンタープライズ向け Linux プラットフォームの最新情報

アプリケーション
アプリケーションの最も困難な課題に対する Red Hat ソリューションの詳細
仮想化
オンプレミスまたは複数クラウドでのワークロードに対応するエンタープライズ仮想化の将来についてご覧ください