

Automating systems provisioning is essential for IT or network system administrators. Many technologies and standards attempt to address this; some are vendor neutral, and some are vendor specific. The latter is particularly true in wireless networks where each network equipment provider needs its associated Element/Network Management System to control its network elements.
Given the rise of radio access network (RAN) decomposition and disaggregation, standards bodies, such as Open RAN, focus on defining interoperable interfaces between the RAN components Radio Unit (RU), Distributed Unit (DU), and Central Unit (CU). At the same time, there is an industry push, led by the O-RAN Alliance, towards virtualizing and cloudifying RAN components, so their lifecycle can be managed independently from the platform running them. Such a platform, composed of commodity off-the-shelf (COTS) servers, needs a high degree of configuration to unlock the benefits of 5G.
[ Find out more about Open RAN and O-RAN. ]
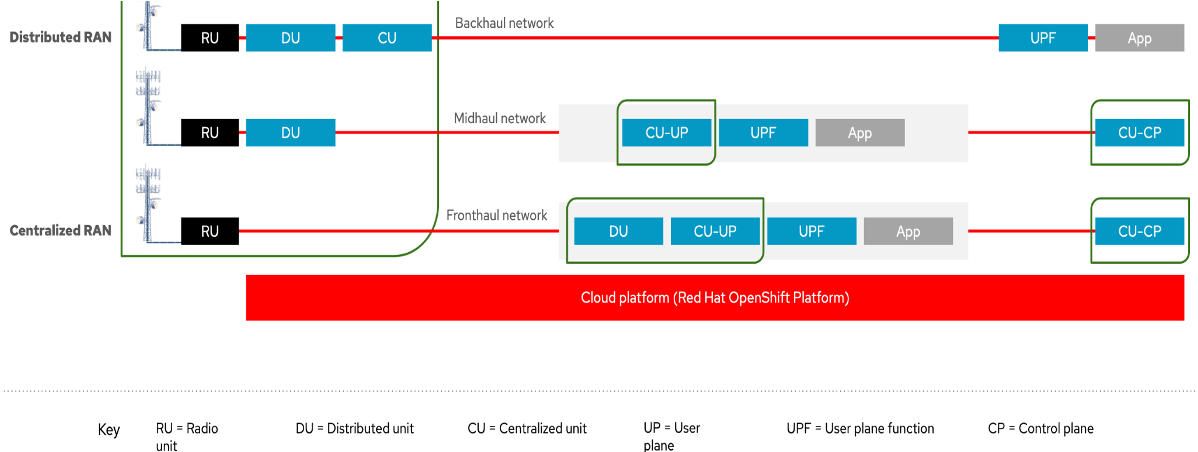
One of the challenges this introduces is the ability to provision and configure this platform at scale; a telecommunication service provider might have thousands of RAN deployments. The platform comprises servers and a hypervisor or container orchestration system.
This article will use the container orchestration system Kubernetes implemented with OpenShift; specifically Red Hat OpenShift 4.11.
Solution overview
Deploy cloud-native 5G open RAN with Red Hat and partners presents the requirements and the high-level approach. It has three main elements:
- Cloud-native platform for deployments at scale
- Automation and operations with GitOps
- Thriving partner ecosystem
This solution aims to provide the same administration, operation, and user experience throughout the entire environment by leveraging a common set of well-adopted APIs offered by Red Hat OpenShift, whether in a central, regional, or edge zone. That horizontal platform isn't necessarily one instance but is rather a set of instances managed collectively.
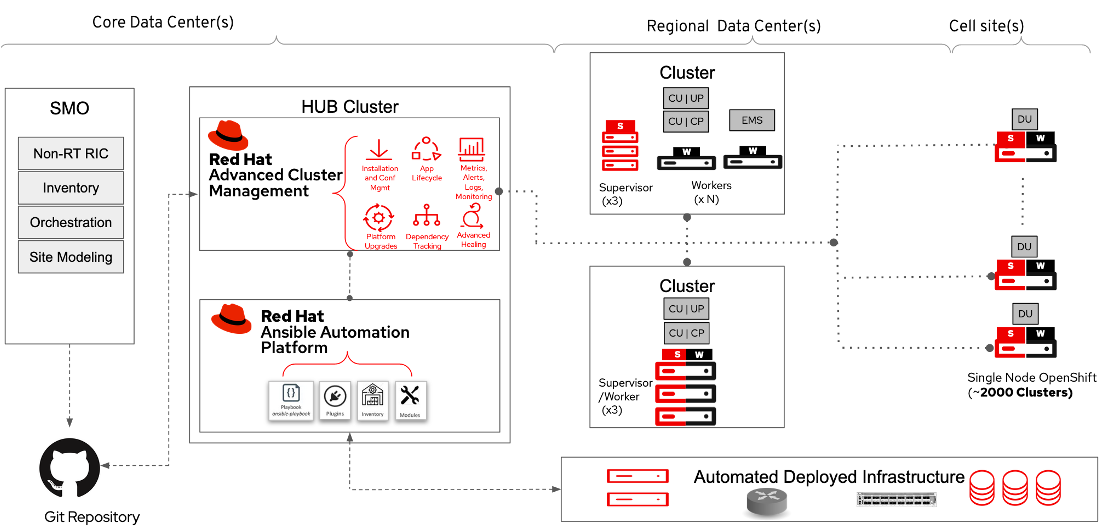
These RAN deployment models use a management environment that will control the others, treating them as cattle and not pets. It is called as a management cluster or hub cluster. The remote environments are called managed clusters.
The image below depicts how that central entity, enabled by Red Hat Advanced Cluster Management (RHACM), can provision and operate remote environments composed of any of the following:
- A full OpenShift cluster (three control planes and at least two computes nodes)
- A compact OpenShift cluster (three nodes acting as both control and compute)
- A single-node OpenShift composed of one node
- A remote worker node (remotely attached to a control plane, hosted in the management cluster, or remote)

Finally, to define once, deploy anywhere, and continuously reconcile the running state with the source of truth, follow a GitOps methodology such as Red Hat OpenShift GitOps.
[ Learn more about deploying multicluster Kubernetes applications using RHACM and GitOps. ]
Different implementation models exist for adopting GitOps at scale, but these are not the subject of this article.

Remote bare-metal cluster lifecycle management
The OpenStack community first addressed this requirement through project Ironic. The goal is to manage hardware through both common (preboot execution environment [PXE] and intelligent platform management interface [IPMI]) and vendor-specific remote management protocols (baseboard management controller [BMC]). This project became the stepping stone of Metal3, enabling such functionalities for Kubernetes.
It's straightforward to deploy the first cluster using the Red Hat SaaS Assisted Installer platform on the Red Hat Hybrid Cloud Console, even if you use your own image registry. Read Making OpenShift on bare metal easy for a good overview of the process.
The main requirement is outbound internet access; no inbound connectivity is needed. The assisted installer is a service that:
- Allows infrastructure admins to generate discovery images
- Discovers hosts that infrastructure admins boot with discovery images
- Allows cluster creators to define clusters from available hosts
- Validates installations before they begin
- Monitors installations
- Collects logs
- Publishes metrics for internal use
- Allows cluster creators to add hosts to existing clusters
Once you create the first cluster, you must install RHACM and Red Hat OpenShift GitOps. Next, you can follow the GitOps methodology to create and configure subsequent clusters.
[ Learn why open source and 5G are a perfect partnership. ]
Zero-touch provisioning for factory workflows is a good way to understand the strategy to enable remote provisioning of bare-metal servers to achieve a fully automated cluster installation. It uses Metal3 under the hood and heavily relies on BMC and a provisioning interface MAC address.
At a high level, you'll use the factory cluster to deploy a self-contained cluster as follows:
- Install the factory cluster: Create the factory cluster (management) to create OpenShift clusters.
- Create the edge clusters: Create fully operational OpenShift clusters (spoke) on OEM hardware using the factory cluster.
- Configure the edge clusters: Unpack and configure the OpenShift cluster at the end-customer site (edge).
In addition, RHACM offers Site Planning and Policy templates, enabling the deployment and configuration of clusters at scale.
Find more details in the documentation.
Topology-aware lifecycle management
A robust infrastructure lifecycle management tool is required to meet the technical and business requirements of managing the infrastructure at scale throughout its entire lifecycle.
It should consider the following:
- Service-level agreements (SLAs) that define minimum availability requirements
- Operational procedures requiring progressive rollout to the fleet (for example, canary clusters upgraded as an initial smoke test)
- Large-scale automation requirements
The Topology Aware Lifecycle Operator (TALO) manages these events at scale in an operational environment.
[ Automating the last mile: Ensuring consistency and scalability at the edge. ]
An example use case is a large fleet of clusters (DUs) with RAN coverage. Updates are applied in waves to ensure sufficient RAN coverage is maintained. SLAs specify the maximum number of unavailable clusters during maintenance events in a coverage area.
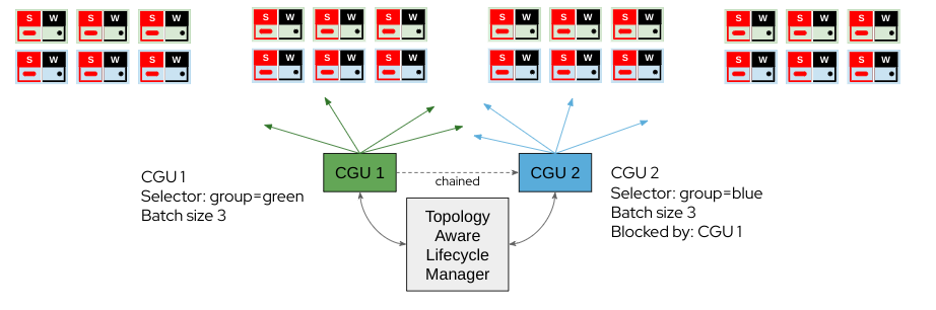
- Green and blue clusters (Cluster Group Upgrade [CGU] 1 and CGU 2) are paired to provide service coverage overlap.
- Operational procedures mandate three clusters (maximum) can be updated.
- CGU 1 updates green clusters in batches of three.
- CGU 2 is chained with CGU 1 and will update blue clusters in batches of three when CGU 1 completes.
TALO minimizes risk during maintenance windows by providing integrated backup and recovery (rollback) functionality. This feature creates a preupgrade backup and provides a procedure for rapid recovery of the single-node OpenShift (SNO) in the event of a failed upgrade. In case of an upgrade failure, this feature allows the SNO to be restored to a working state with the previous version of OpenShift without requiring application reprovisioning.
Cluster upgrades need to be completed within the maintenance window time. The window also needs to include time to resolve a failed upgrade. The OpenShift release artifacts must be downloaded to the cluster for the upgrade. Some clusters may have limited bandwidth to the hub cluster hosting the registry, making it difficult for the upgrade to complete within the required time. The required artifacts must be present on the cluster before the upgrade to ensure the upgrade fits within the maintenance window.
To enable those operational procedures, TALO manages the deployment of RHACM policies for one or more OpenShift clusters in a declarative way.
Find out more information in our documentation.
Cloud-native platform configuration
The methodology can deploy and manage clusters at scale. Look at each cluster's lower-level components to enable performance tuning. These are the elements that will compose the policies mentioned above.
The goal is to complete 100% of the hardware configuration using the Kubernetes Resource Model, enabling declaration of the intended configuration as code and fostering the management of operations through GitOps.
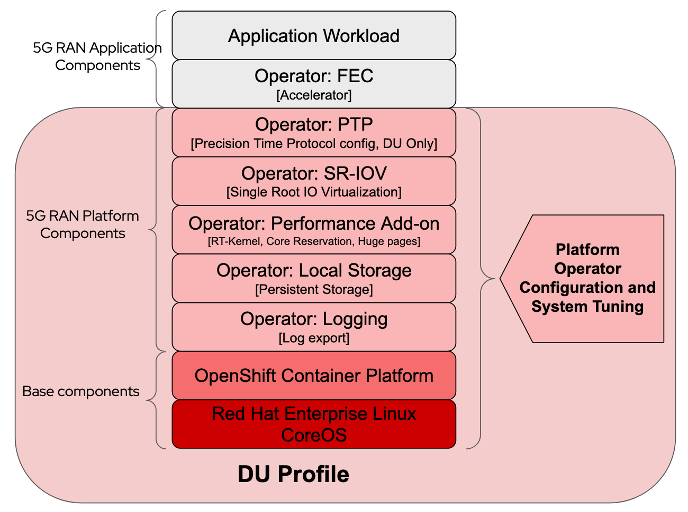
The picture below presents the node operating system and all the supported operators, enabling specific node configuration.

Here are the most important operators for a 5G Core application:
- Node Tuning Operator can be used to tune the underlying operating system to reduce latency. It uses a perfomance profile and is responsible for:
- HugePages
- Topology manager policy (NUMA)
- CPU reservation and isolation
- Power consumption scheme
- Real-time kernel
- Network interface controller (NIC) queues tuning (DPDK)
- IRQ dynamic load-balancing
- Special Resource Operator lets you load specific kernel modules and device drivers. This component is still in technology preview, meaning you should not use it in production. It is recommended to get guidance if you want to use it.
- NMState Operator enables interface configuration, regardless of their type. It is commonly used to define bound interfaces, along with VLAN subinterfaces.
- SR-IOV Operator permits the configuration of SR-IOV supported NICs through SriovNetworkNodePolicy, which configures, among other things:
- MTU
- Number of VFs
- NIC selector
- Device type (whether vfio-pci or netdev)
A SriovNetwork is required to consume the created devices. This will result in a NetworkAttachmentDefinition that pods can then consume through annotation.
There are several other operators for 5G RAN or other types of workloads, such as Precision Time Protocol Operator, Intel Device Plugin Operator, FEC Operator, NVIDIA GPU Operator, and Network Operator. Each is meant to abstract hardware-specific functionality and enable its configuration using a Kubernetes Resource Model.
Note: Many operators enable alarming, monitoring, service assurance, remote management, certificate management, and so forth.
Defining performance profiles per type of application and infrastructure is key to unlocking performance.
The following image is an example of the operators required for the DU performance profile.
Looking ahead
The ability to provision and configure bare-metal clusters at scale is now a reality. But other challenges remain, including:
- Observing all these environments using a unified pane of glass for operations
- Enabling self-autonomous systems (platform and networks) fostering sustainability of service level assurance
- Multicluster networking for seamless application communication (distributed SBA 5G Core across central and edge clusters)
- Enhancing scheduling capabilities toward sustainable computing
Stay tuned for more information. In the meantime, feel free to look at some of the progress we accomplished and presented at KubeCon NA 2022.
[ Check out Red Hat's Portfolio Architecture Center for a wide variety of reference architectures you can use. ]
About the authors
Alexis de Talhouët is a Telco Solutions Architect at Red Hat, supporting North America telecommunication companies. He has extensive experience in the areas of software architecture and development, release engineering and deployment strategy, hybrid multi-cloud governance, and network automation and orchestration.
Federico Rossi is a Sr. Specialist Solutions Architect at Red Hat, with professional experience in the design, development, integration, delivery, and maintenance of carrier-grade voice/data networks and services for Telco operators worldwide. Federico focuses on helping partners and customers architect 5G RAN, O-RAN, 5G Core, and Edge/MEC solutions on hybrid clouds leveraging Red Hat Open Source technologies.
More like this
Gain stronger pod isolation on Microsoft Azure Red Hat OpenShift with OpenShift sandboxed containers
Physical AI: When machines start to think and act in the real world
Container Roundup | Compiler
Infrastructure At The Edge | Compiler
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds