


Microservices application architecture is taking root across the enterprise ecosystem. Organizing and efficiently operating microservices in multicloud environments and making their data available in near-real time are some of the key challenges enterprise architects confront with this design.
Thanks to developments in event-driven architecture (EDA) platforms (such as Apache Kafka) and data-management techniques (such as data mesh and data fabrics), designing microservices-based applications has become much easier.
However, to ensure that microservices-based applications perform at requisite levels, you must consider critical non-functional requirements (NFRs) in the design. NFRs address how a system operates, rather than how the system functions (the functional requirements).
The most important NFRs involve performance, resiliency, availability, scalability, and security. This article describes designing for performance, which entails low-latency processing of events and high throughput. Future articles will address the other NFRs.
We'll use electronic funds transfer (EFT) as an example of the architectural and design decisions that are the basis of high-volume, low-latency processing.
How electronic funds transfer works
EFT involves sending and receiving money through digital channels. It's a good use case for explaining performance-related decisions. It involves handling a high volume of requests, coordinating with many distributed systems, and having no margin of error (the system needs to be reliable and fault-tolerant).
In the past, a fund transfer would take days and involve visiting a bank branch or writing a check. Now, fund transfer has become instantaneous due to new digital payment mechanisms, payment gateways, and regulations. In September 2021, systems executed 3.6 billion real-time transactions worth INR 6.5 trillion on India's United Payment Interface (UPI) network.
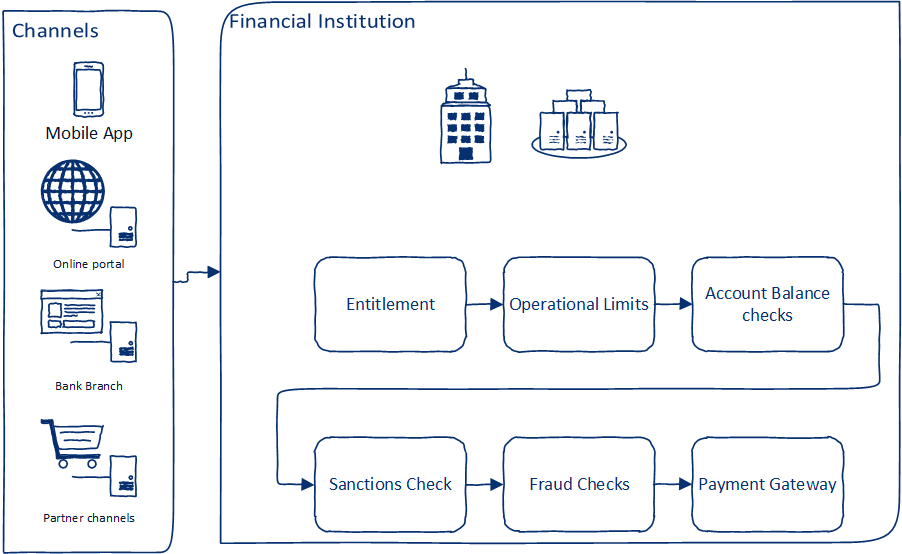
Customers expect real-time payments across a wide variety of channels, and country-specific regulations have made it mandatory to expose payment mechanisms to trusted third-party application developers. Typically, a bank customer places a request for fund transfer using one of the available channels (mobile app, online portal, or in person at the institution). Once the request is received, the bank must:
- Check entitlements to ensure the customer is eligible to make the request
- Perform checks for operational limits depending on channel and mode of transfer
- Perform balance checks and lock the amount of the transfer
- Perform sanctions checks to ensure the transaction conforms to regulations and sanctions checks
- Perform fraud checks to find out if the transaction seems fraudulent
- Create a request for payments in the payment gateway
[ Register for the free online course Developing cloud-native applications with microservices architectures. ]
The architecture
Implementation of this use case uses a cloud-native style—microservices, APIs, containers, event streams, and distributed data management with eventually consistent data persistence for integrity. This architecture is based on the best practices outlined in Architectural considerations for event-driven microservices-based systems.
The key architectural patterns used to implement this user story are staged event-driven architecture (SEDA), event-stream processing, event sourcing, the Saga pattern, and CQRS.
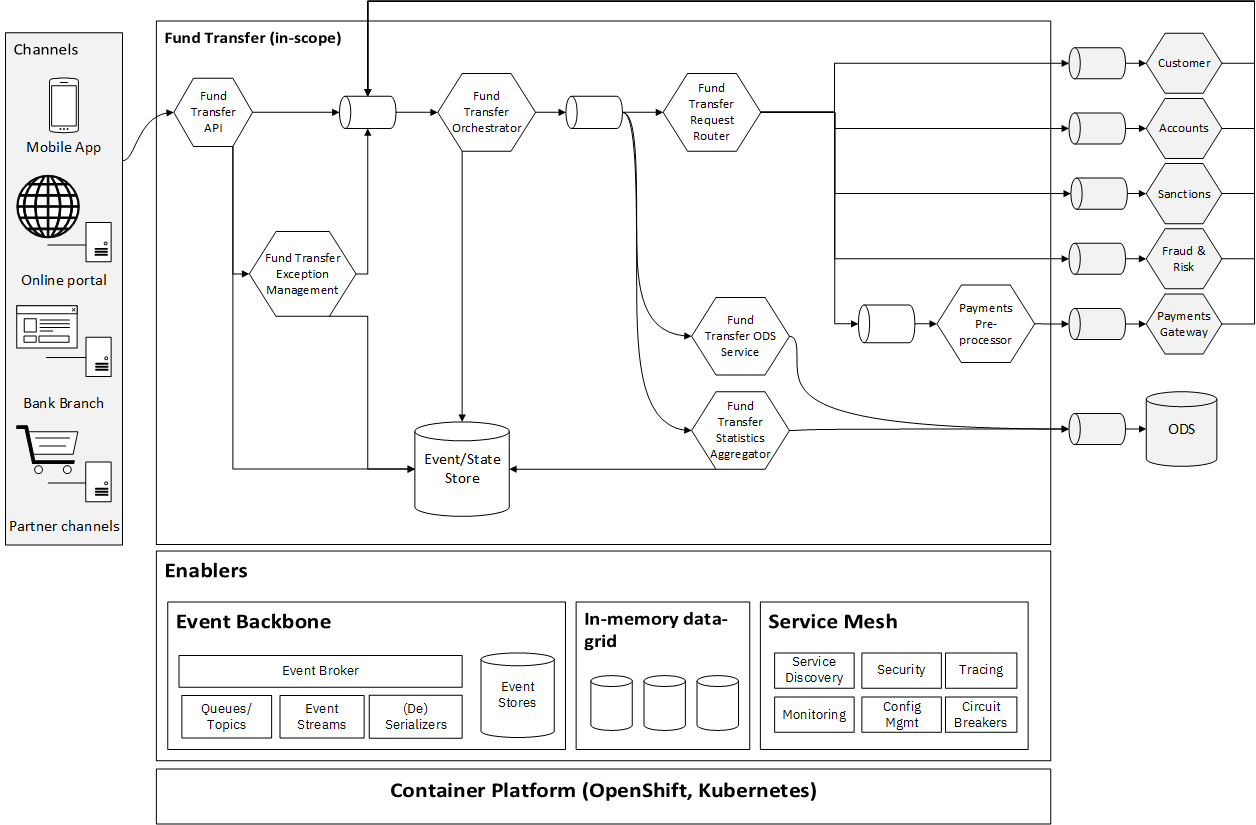
Application and data flow
This application architecture uses a set of independently operable microservices. In addition, an orchestrator service (another microservice) coordinates the full transaction for end-to-end process execution.
The different fund transfer services are wired together as a set of event producers, processors, and consumers. There are five main processors:
- Fund transfer orchestrator: This is responsible for processing fund transfer events and modifying and maintaining the state of fund transfer requests.
- Fund transfer request router: This optional component generates an event and determines where to route the event based on state transition. It can multicast the event to one or more other systems. Request routers are required only if the downstream consumers can't consume from a single topic (that is, they are legacy or implemented services and can't change to consume from a single topic).
- Fund transfer statistics aggregator: This is responsible for aggregating and maintaining fund transfer statistics based on multiple dimensions required to manage key performance indicators (KPIs).
- Fund transfer exception management: This component allows users to manage exceptions. It is responsible for triggering user actions on in-flight fund transfer requests in case of exceptions. This could include canceling a fund transfer request or replaying the request if there is an exception. Additionally, it provides the mechanism to replay all events (by using the event sourcing architectural pattern) in case of major system crashes in order to reinstate the latest state.
- Fund transfer API: This provides functionality for the channels to request fund transfer, check the transfer status, and perform interventions (cancel, replay, and others).
The API publishes an event to the fund transfer orchestrator input, the primary coordinator for fund transfer requests. Events are first-class citizens and are persistent. The events accumulate in an event store (enabling the event sourcing pattern). Based on the event context and the payload, the orchestrator transforms the event and publishes the state of fund transfer to another topic. The fund transfer state transitions also get recorded in a state store, which you can use to regenerate the state in case of system-level failures.
[ Learn more about Event-driven architecture for a hybrid cloud blueprint. ]
This state gets consumed by the fund transfer request router, which makes routing decisions and routes it to other systems (either single or multiple systems simultaneously). Other systems process and publish the outcome as an event to the input topic. The fund transfer orchestrator then correlates and processes these, resulting in a state change in the fund transfer request. The fund transfer orchestrator processes functional exceptions, and the fund transfer request state is updated accordingly.
Fund transfer state changes also get consumed by the real-time fund transfer statistics service, which aggregates the statistics of fund transfer across multiple different dimensions so that the operations team can have a near-real-time view of the fund transfer statistics.
Technology building blocks
The technology building blocks that implement this application architecture are:
- Event backbone: This sends messages between services and manages the ordering and sequencing of events. It also provides the single source of truth of data. In case of failures, the system can restart from the point of failure. It provides the mechanism to build event and state stores. In major outages, you can utilize the event and state stores to reinstate the state.
- In-memory data grid: This is a distributed cache for improving performance. It provides the ability to store and look up data from the services. Each service can have its own set of caches. These caches can be persistent. You can also enable the cache as a "write-through" cache, which is resilient and can withstand outages. Also, in case of cluster-level failure (such as if the entire cache cluster goes down), the cache can be rehydrated from the event and the state stores of the event backbone (this would require some processor downtime).
- Service mesh: This provides the ability to monitor, secure, and discover services.
Focus on performance
It is critical to maintain desired performance levels for each component of the architecture, as issues in any one of them can cause stream processing to choke. Therefore, every architecture component needs performance tuning without compromising other NFRs. You need a deep technical understanding of each component is to tune it effectively. We'll explain how Apache Kafka improves performance in event-driven architectures in a separate article.
This is excerpted from Designing high-volume systems using event-driven architectures and reused with permission.
About the authors
Ram Ravishankar is an IBM Distinguished Engineer and the Global CTO for IBM Services for Cloud Strategy and Transformation Solutions. Ram particularly leads transformation strategies for global large banking clients. Ram is currently leading the solution strategies and architecture to modernize complex core systems including core banking systems.
Harish is an IBM Distinguished Engineer with over 22 years of experience in designing business solutions using a wide spectrum of technologies. Harish is a globally recognized expert leading clients into new generations of technologies and bringing paradigm shifts in their ways of working. He has deep cloud-native and data-architecture expertise with the ability to solve complex problems in a systemic and structured manner to design new genres of solutions. Harish is an IBM master with 102 filed patents on emerging technologies including cloud, blockchain, cognitive computing, microservices, mobility digital integration and the Internet of Things.
Tanmay is an IT architect and technology leader with hands-on experience in delivering first-of-a-kind solutions on emerging technologies. With over 21 years of experience, he has a consistent track record of delivering multiple complex and strategic technology transformation programs for clients in banking and financial markets and telecom. His core areas of expertise include digital transformation, cloud-native development, cloud-based modernization, microservices, and event-driven architectures. He is known for developing IT architectures, performance engineering, troubled project recovery, and hands-on technology leadership during implementation.
More like this
Why platform engineering fails to scale: Product and adoption design in practice
The new reality of supply chain trust: Why platform-native security is non-negotiable
Becoming a Coder | Command Line Heroes
The Great Stack Debate | Compiler: Stack/Unstuck
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds