
In an event-driven architecture, components act independently. They don’t need to know about other components and, in that way, they are truly independent services. All the given component needs to know is how to process an incoming message and how to emit messages upon the given process’s completion. (See Figure 1 below.)
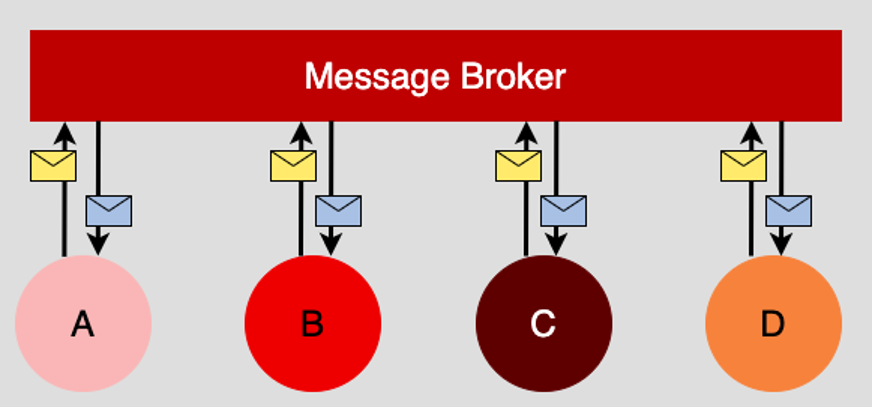
When it comes time to add a new service to the system in an event-driven architecture, all that’s required for integration is an awareness of the relevant “inboxes” and “outboxes” in the message broker. You don’t have to go searching the network for service endpoints. Everything is in a central location, the message broker.
Event-driven architectures are popular today because they address a critical problem that occurs when managing connections in inter-service communication at web scale. As the number of nodes on a network increases, the number of possible connections on the network increases well beyond the node count. Figure 2 below illustrates the problem.
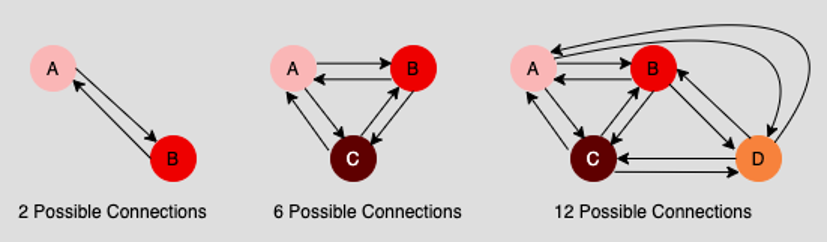
As you can see above in Figure 2, when you have two nodes on a network, there are two possible connections: One connection going from Point A to Point B and another connection going from Point B to Point A. However, when you have three nodes on the network, the number of possible connections increases to six. When there are four nodes on the network, the number of possible connections increases to 12. As nodes are added to the network, the number of possible connections increases well beyond the node count.
Using an asynchronous framework to "fire and forget"
When you have an architecture with many endpoints (a.k.a. nodes) that are part of a synchronous API framework such as REST, things can get unwieldy. REST is, by definition, based on the request and response pattern. This means that the caller needs to know the exact location of the target on the network in order to call the endpoint directly. Also, the connection is synchronous, which means the interaction between the caller and target is locked until either the caller receives a response from the target or the caller’s request times out.
REST interactions aren’t that much of a problem when you’re exposing a single API to parties external to the application domain. However, when you’re in a situation where you have dozens or hundreds of services active server-side within a distributed architecture—which is not uncommon in modern microservice-oriented architectures—keeping track of it all is a herculean task. You have to know a lot just to find the location of an API on the network, and you need to know even more to facilitate meaningful data exchanges. This alone is a significant task when the number of services in a system is unchanging. When you need to add a new service to the design and that service uses some of the existing REST services, just wiring it all up will take a good deal of time. The whole process can be a never-ending set of problems.
Event-driven architectures address these problems head-on. At its core, event-driven architecture relies upon facilitating inter-service communication using asynchronous messaging. In the asynchronous messaging pattern, a service sends information in the form of a discrete message to a message broker and then moves on to other activities. On the broker side, that message is consumed by one or many interested parties at their convenience. All communication happens independently and discretely. It’s a “fire and forget” interaction.
However, while things do get easier by focusing on component behavior instead of managing the burdens of endpoint discovery that go with inter-service communication, there is still a good deal of complexity involved in taking a messaging approach. In an event-driven architecture, a component needs to understand the structure of an incoming message. Also, a component needs to know the format and validation rules for the message that will be emitted back to the broker when processing is complete. Addressing this scope of complexity is where a schema registry comes into play.
Using a schema registry to make asynchronous communication easier
A schema registry is a program or service that describes the data structures used in a given domain. Its purpose is to be the sole source of truth for schema definitions.
The way a schema registry works is that when a developer(s) creates a specific data schema for use within the system, that data schema is stored in a schema registry that is accessible to all relevant parties. (See Figure 3 below.)
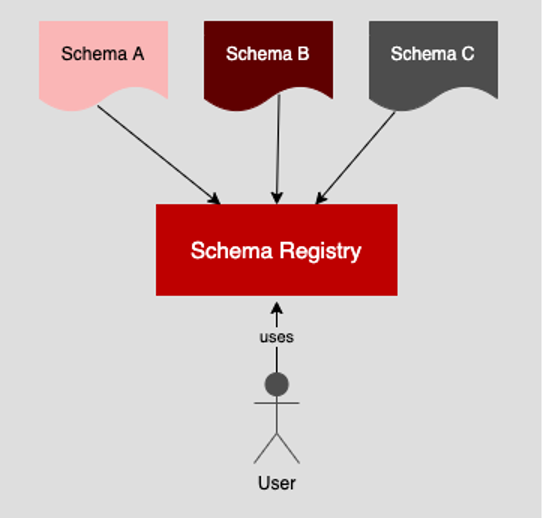
Typically, the schema is stored with metadata that makes it more easily discoverable. For example, the schema can be stored with a description, labels, and keywords that can be discovered using the schema registry’s query mechanisms.
Once a common source of truth is established via a schema registry, developers then get a schema definition of interest from the registry and use that definition to ensure that the data being sent to and consumed from the broker conforms to the particular schema of interest.
[ For more information about using schema registries to manage messaging, read Using a schema registry to ensure data consistency between microservices ]
However, when using a schema registry in an event-driven architecture, there is a gotcha in play. There isn’t a standard format for storing event schemas. There are many general-purpose formats out there, such as JSON Schema, Protocol Buffers, Thrift, and SOAP. And there are specifications such as Cloud Events and AsyncAPI that are particular to event-driven architectures. However, as of this writing, there is no specification for event messaging that is universally accepted on the order of one as commonplace as HTML. Thus, a critical architectural decision you’re going to need to make is which schema format to use. The specification you define today will be used for years, long after you’ve moved on to other things. It’s a big decision.
Putting it all together
Event-driven architecture has several benefits for an enterprise application that has a large number of active components. Instead of concerning yourself with the details of location discovery between many endpoints to do data exchange, one endpoint on the network—the message broker—receives all messages and then redistributes those messages based on forwarding rules and the distribution architecture used by the message broker.
[ For more information about messaging patterns and message distribution architectures, read the associated article, Architectural messaging patterns: An illustrated guide. ]
Each component can act independently. Also, event-driven architectures are asynchronous. Thus, the risk of a service getting tied up in a long-running message exchange is reduced. Event-driven architectures are basically fire and forget.
However, an event-driven architecture has its own type of complexity. Since a message can come from any source by way of the common message broker, consumers of a message need to know a lot about how the message is formatted to interpret the information the message contains. Using a schema registry addresses this problem. A schema registry acts as a single source of truth about the messages in play in an application. Consumers query the schema registry to learn what’s required to process a message’s information properly.
Using an event-driven architecture makes a lot of sense for managing many internal services at web scale. However, there is still complexity in play, particularly around understanding the actual structure of event messages. Using a tool such as a schema registry will help address some of this complexity. The trick is to have a plan in place to address the new complexities at hand so you can enjoy the significant benefits that event-driven architectures have to offer.
About the author
Bob Reselman is a nationally known software developer, system architect, industry analyst, and technical writer/journalist. Over a career that spans 30 years, Bob has worked for companies such as Gateway, Cap Gemini, The Los Angeles Weekly, Edmunds.com and the Academy of Recording Arts and Sciences, to name a few. He has held roles with significant responsibility, including but not limited to, Platform Architect (Consumer) at Gateway, Principal Consultant with Cap Gemini and CTO at the international trade finance company, ItFex.
More like this
Red Hat Ansible All-Stars: Driving the future of network and infrastructure automation
Achieve high scalability using Red Hat Satellite Capsule Server
Container Roundup | Compiler
Untangling Networks | Compiler
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds