
Introduction
In a past blog post, we illustrated some disaster recovery strategies for applications deployed in OpenShift. In particular, the scenario called “Multiple OpenShift Clusters in Multiple Datacenters” promised near-zero RTO and RPO.
Nearly zero downtime and zero data loss in the event of a disaster is a very desirable property for a system, albeit potentially expensive. In this article, we will describe how to deploy stateful applications across three cloud regions to achieve near zero RTO and RPO.
The following is a high-level overview of the architecture that is needed for this kind of deployments:
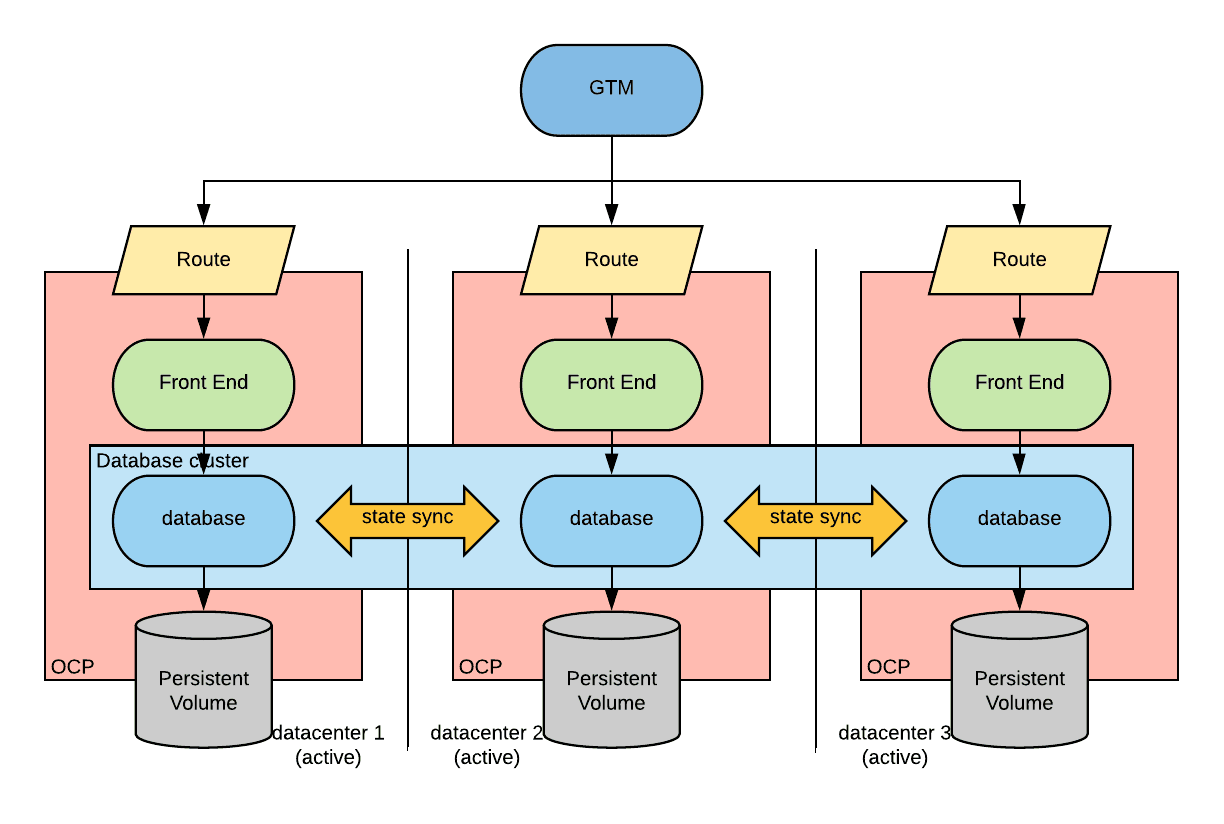
There will be three OpenShift clusters in three separate regions. Each cluster will have instances of a stafetul workload. In this case, the workload example is a database.
These instances will form a cluster and become a single conceptual entity by synchronizing the state with each other. All instances will be active, and a leader is elected using a leader election algorithm such as paxos or raft (see this article on why this becomes necessary).
Instances can communicate with each other via a network tunnel established between the OpenShift’s SDNs.
For the ingress portion, a global load balance will be used to direct the traffic to one of the clusters. Health checks enable the global load balancer to react to an application outage in a specific cluster by excluding it from the available target pool members.
The remainder of this article will describe the set of steps necessary to build this architecture along with explaining the design decisions that were made. For the step-by-step instructions for building this infrastructure, refer to this tutorial.
Standing up Multiple OpenShift Clusters
The first step is to create the environment. For this example, we will create three OpenShift clusters in three different AWS regions. However, conceptually, this architecture would be feasible with other cloud providers or on premise deployments as well as mixing cloud providers and on premise deployments in a true hybrid cloud fashion.
There are several ways of creating the clusters, and you are welcome to choose the best approach that works for you. In this example, we are going to use Red Hat Advanced Cluster Management (RHACM) for cluster creation. One of the advantages of using RHACM is that we can stand up clusters in a declarative fashion using the Hive operator.
A Helm chart has been created to streamline cluster creation, and once the deployment is complete, the newly created cluster is automatically registered in RHACM.
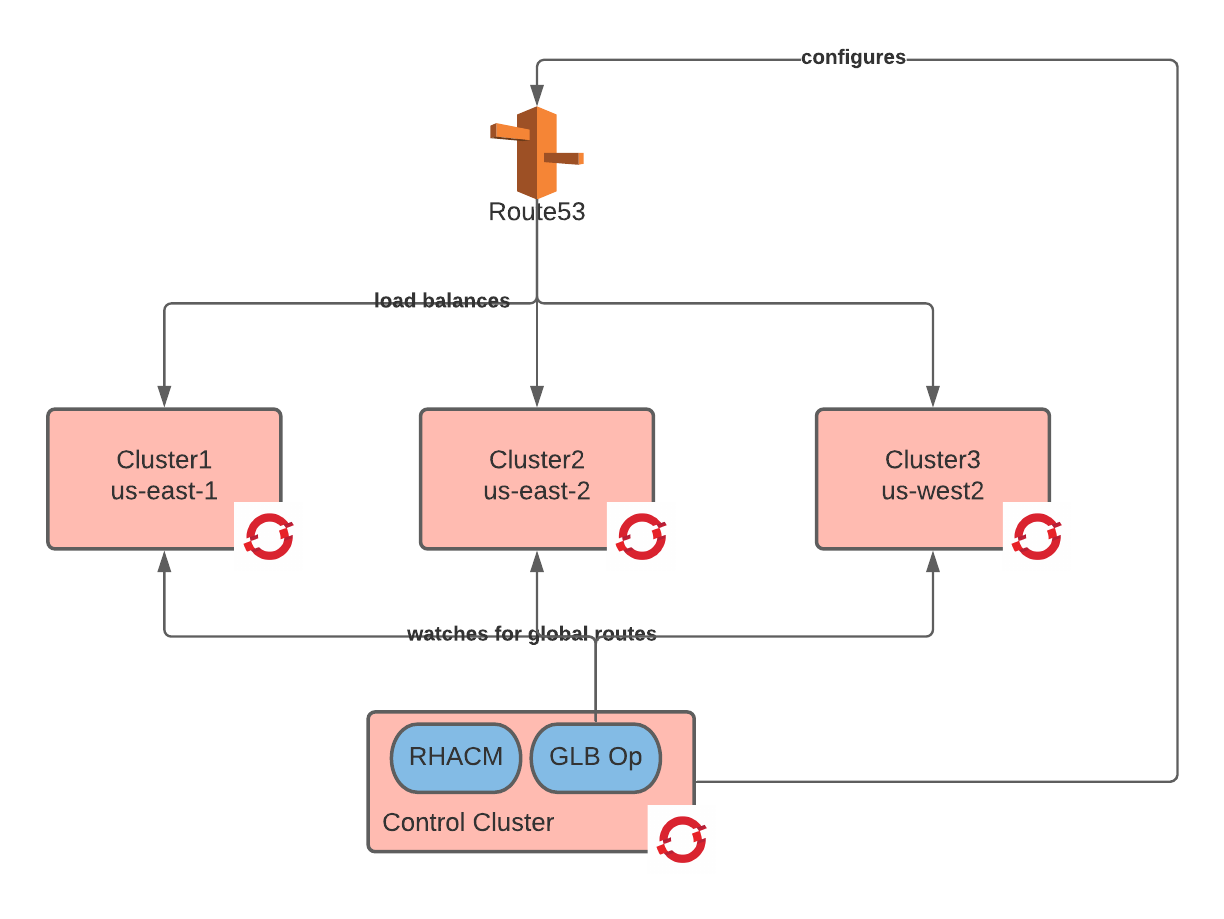
After following the steps in this tutorial, the following architecture will be created:
Deploying a Global Load Balancer
The global load balancer will then need to be deployed in order to direct traffic to one of the clusters. For this tutorial, we are using route53 (other approaches are also possible).
Route53 will be configured by the global-load-balancer-operator. For more information about this operator, refer to this article.
After you follow the steps to deploy and configure the operator, the resulting architecture is represented by the below diagram:
The global-load-balancer operator is configured to watch the managed clusters for OpenShift routes with the label route-type: global. By extracting information from these routes, the operator will configure consistent DNS entries in Route53.
When matching routes with the above annotation are created in the managed cluster, the global-load-balancer-operator will configure Route53 DNS entries that load balance across the three clusters. Additionally, it is possible to configure the route53 entries with health checks so that traffic will not be sent to destinations where the application endpoint becomes unresponsive. It is also possible to configure different load balancing policies. For this example, we will use the Latency load balancing policy.
Deploying a Network Tunnel between Clusters
The last step needed to prepare our infrastructure is to create a network tunnel between the SDNs of the managed OpenShift clusters.
A network tunnel enables east-west communication between clusters without having to egress and ingress traffic from the origin cluster to the destination cluster. This simplifies the deployment of applications that require communication between individual pod instances deployed across multiple clusters.
Our network tunnel will be created using Submariner.
After following the steps to deploy Submariner, the deployed environment is represented by the following architecture:
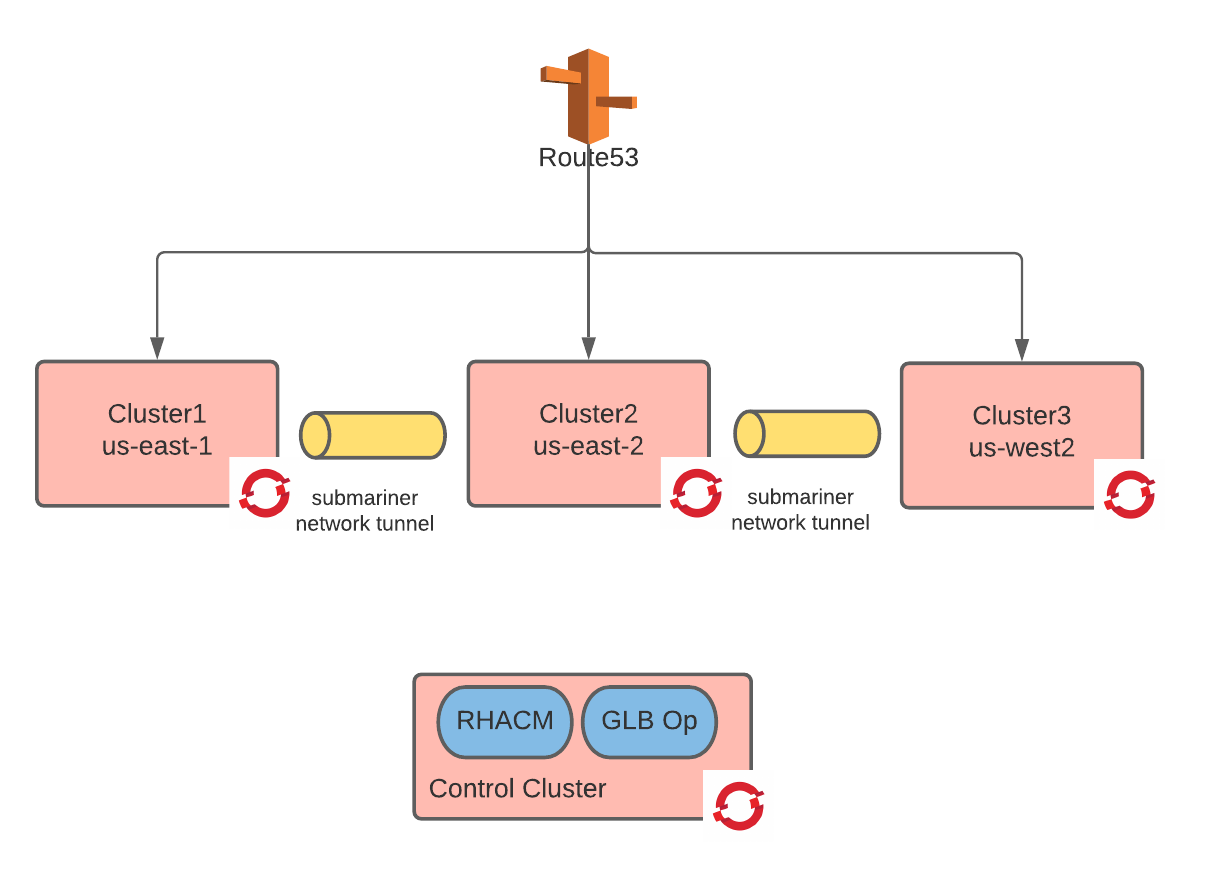
All the managed clusters are now connected by the network tunnel in a sort of a cluster mesh fashion (for editorial reasons, the tunnel between Cluster1 and Cluster3 is not shown in the diagram above).
Submariner provides us with an IPsec encrypted tunnel that has the following capabilities:
- Ability to route IP packets between Pods in clusters participating in the tunnel.
- Ability to honor the Kubernetes service semantics. If a pod attempts to communicate to a service IP located in a different cluster, the connection will be load balanced to one of the pods backing that service in the destination cluster. This requires services to be exported via the ServiceExport API.
- Ability to discover services from another cluster using DNS. This capability is described in the Multi Cluster Service API specification and it is implemented with the Lighthouse addon.
- Ability to govern NetworkPolicy (firewall rules) for traffic between clusters. This feature is currently on the roadmap and should be implemented with the Coastguard addon.
Submariner employs gateway nodes to manage the IPsec connections that create the network tunnel.
Establishing Trust between the Clusters
When deploying stateful workloads, and in particular, ones where communication between each instance is required in order to form a logical cluster, it is commonly required that a trust be established between each of these instances. The standard approach for this use case is to use digital certificates and mutual authentication. A method for distributing certificates from a common certificate authority becomes necessary. Additionally, applications typically require credentials in order to obtain access to the stateful workloads. This brings up the need for a centralized secret management tool that can easily distribute certificates and credentials to resources that require them
For this demo, we are going to use HashiCorp Vault, but as with many other areas in this discussion, other tools are also available. HashiCorp Vault will be self-hosted in the managed clusters. We could have hosted Vault anywhere, but it makes sense to create a Vault cluster stretched across the managed OpenShift clusters as it will benefit from the geographically distributed infrastructure we are building, making it resilient to disasters.
Follow the steps in this tutorial to deploy HashiCorp Vault on the previously created infrastructure. The result is depicted in the diagram below:
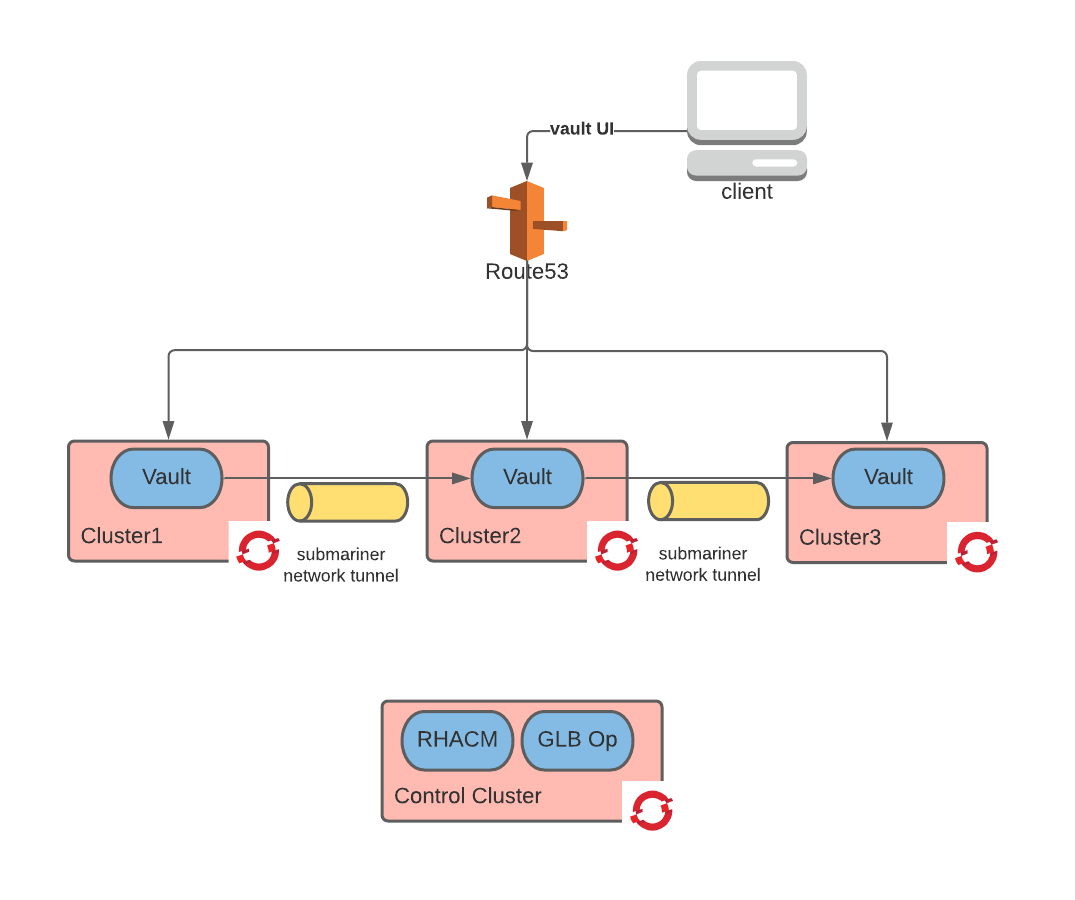
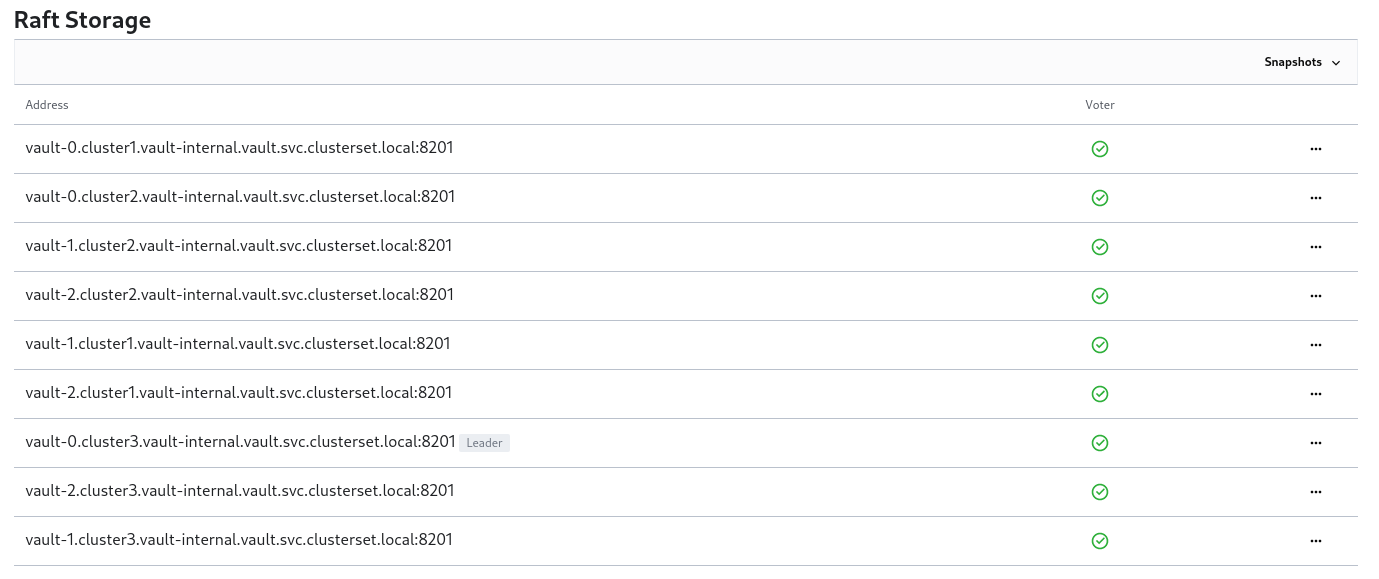
The Helm template in this tutorial is derived from the official Vault Helm template and deploys Vault with Raft storage in a multi-cluster configuration. The result is a nine-node Vault cluster in which Vault nodes are configured to auto-unseal (using AWS KMS) and auto-join the Raft cluster on boot. So, aside from the one-time initialization step, this Vault cluster requires minimal maintenance.
Once Vault is correctly initialized, you should see all the members joining the cluster, which can be verified from the web UI:
Certificate Management
HashiCorp Vault will be our certificate authority for this demo. To facilitate the certificate provisioning process, we are going to use a set of operators: cert-manager (to provision the certificates), cert-utils-operator (to inject the certificates in OpenShift routes), and Reloader (to rollout pods when a certificate is modified, such as renewal). For more information on how these operators work together to offer a fully automated certificate lifecycle experience, see this article.
After completing the configuration steps, the deployed architecture is depicted below:
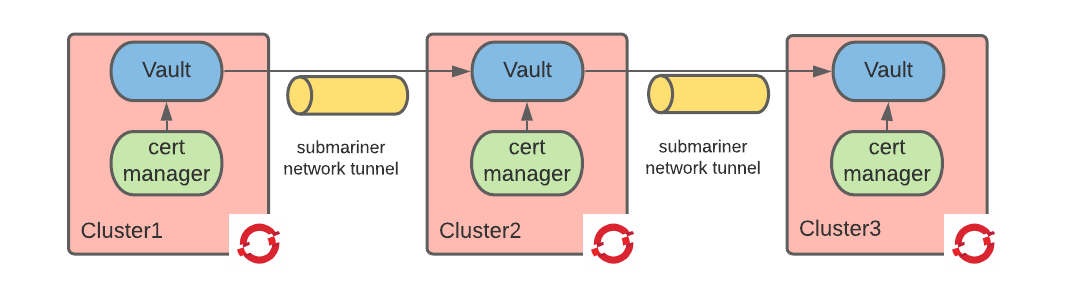
An interesting topic of note in this configuration is that each instance of cert-manager needs to authenticate to Vault to provision certificates. But from a Vault’s perspective, these cert-managers are different entities, as they each authenticate themselves via the Kubernetes authentication method using different service accounts (from different clusters).
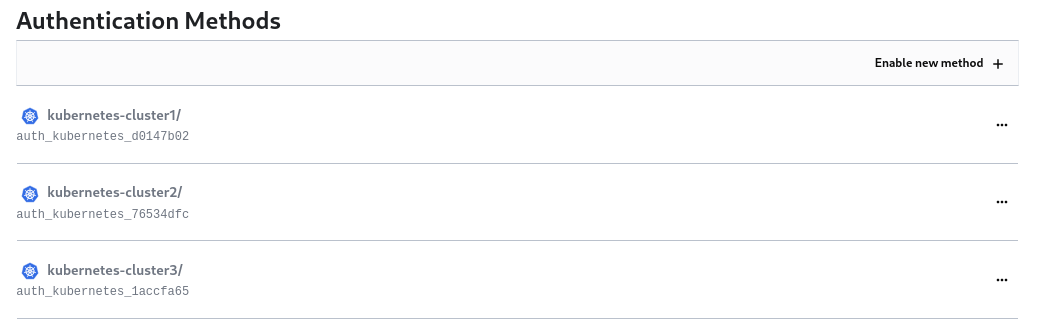
To solve this issue, three Kubernetes authentication endpoints (one per cluster) have been configured and can be seen from the Vault web UI:
Conclusions
In this article, we introduced a proposed architecture to deploy stateful workloads across multiple geographical regions and began preparing the needed infrastructure. In doing so, we ended up actually deploying our first stateful workload: HashiCorp Vault. In part two of this series, we will look at deploying CockroachDB, a cloud-native distributed SQL database.
About the author
Raffaele is a full-stack enterprise architect with 20+ years of experience. Raffaele started his career in Italy as a Java Architect then gradually moved to Integration Architect and then Enterprise Architect. Later he moved to the United States to eventually become an OpenShift Architect for Red Hat consulting services, acquiring, in the process, knowledge of the infrastructure side of IT.
Currently Raffaele covers a consulting position of cross-portfolio application architect with a focus on OpenShift. Most of his career Raffaele worked with large financial institutions allowing him to acquire an understanding of enterprise processes and security and compliance requirements of large enterprise customers.
Raffaele has become part of the CNCF TAG Storage and contributed to the Cloud Native Disaster Recovery whitepaper.
Recently Raffaele has been focusing on how to improve the developer experience by implementing internal development platforms (IDP).
More like this
Why Operational Resilience and Digital Sovereignty Top the CIO Agenda
How Red Hat OpenShift 4.22 impacts enterprise AI’s bottom line
Crack the Cloud_Open | Command Line Heroes
Edge computing covered and diced | Technically Speaking
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds