
With the release of OpenShift Online 3, the time is slowly approaching to start migrating applications from the original OpenShift Online (v2) to the new version. There are some important aspects to this and the most important will be covered in this blog post.
Basic Architecture
In OpenShift v2 the architecture was pretty much built from the ground up by the OpenShift team. The broker was written in Ruby while a STOMP-based message queue provided the communication hub. Mcollective from the Puppet project provided cluster communication. The applications were running in small isolated containers called gears. All of that has changed.
While OpenShift Online V2 was hugely successful, we saw a lot of momentum around containers and orchestration in the community. We decided it would be best for our users if we took our experience running containers at scale and became significant contributors to both the open source docker and kubernetes projects. In fact, we are the 2nd largest contributor to both projects. Given the amount of work we were doing in these upstream communities, we felt it was time to re-architect our platform around these two base technologies and add additional features to make them accessible to developers.
OpenShift 3 is built around Kubernetes. And I used “around” intentionally because the relationship between Kubernetes and OpenShift is pretty interesting. On some level we are building in Kubernetes - that means we are trying to push as many features as possible to the upstream project. We are building underneath Kubernetes as well, putting a lot of effort into making Kubernetes usable with all the different possible networking/storage/infrastructure setups. OpenShift builds on top of Kubernetes to provide a great developer experience, features for building and maintaining containers, etc. We are also building "around" Kubernetes by extending the upstream features and providing extensions not (yet) available in the upstream. With all that said, users can still treat OpenShift as a Kubernetes cluster - you can take kubectl and use it against an OpenShift cluster and it will just work, which is great if you already have some integration at the Kubernetes level or if you are just looking for an enterprise distribution of Kubernetes.
Gears vs. Containers
Gears were the container technology in OpenShift 2 to provide isolation for user applications in a multitenant environment. Gears were essentially a thin layer over SELinux, cgroups, and kernel namespaces. The technology was started because there was no other viable option at that time that met all of our requirements. However, docker arrived and became popular (and the technology is actually becoming standard through the OCI initiative) for container technology. OpenShift 3 has replaced gears with docker-based containers under the hood.
For users looking for the "PaaS" experience, this is not as important, but for those who are looking for a platform for building, maintaining, and deploying docker-based containers, OpenShift can help you there.
Even though OpenShift can run any docker-based container from the public Docker hub or any other source, in OpenShift Online this is not the case. For security reasons, we are limiting the usage of containers running as "root". That means that when the container is started, it will get random UID assigned and the container has to be able to deal with that, but unfortunately, most containers on the DockerHub are not built in this way. So make sure that the container you want to run is built in a reasonable and secure way.
Action Hooks
Action hooks were provided in OpenShift v2 to run tasks during different stages of the container lifecycle. Action hooks were implemented through “well-known” files in the application repository, i.e. use provided executable files in a specific directory and OpenShift executed the file when the lifecycle stage came.
There are no action hooks in OpenShift 3 as you have known them in OpenShift v2. There is however way to do action hook-like functionality using the deployment hooks as Veer has described how to do this in his blog post.
Environment Variables (EV)
Environment variables are still used for application configuration, for example knowing where to connect to your database. With OpenShift v2 there were well known EVs that provided this information. With OpenShift 3 this is not the case. With the flexibility of deploying any possible container on the platform, it’s almost impossible to provide a reasonable set of well-known environment variable names.
With OpenShift 3, when you deploy something like PostgreSQL from the catalog, you will be asked for the name of the new deployment. Check the following picture and pay close attention to the “Database Service Name”

Let’s say we accept the proposed service name posgresql. OpenShift will provide the application connection information for the PostgreSQL service through environment variables:
- POSTGRESQL_SERVICE_HOST = host to connect to
- POSTGRESQL_SERVICE_PORT = port to connect to
This can be generalized to any possible service, OpenShift 3 will always provide SERVICENAME_SERVICE_HOST and SERVICENAME_SERVICE_PORT.
The other big different from OpenShift v2 is that your application container will no longer be provided with application specific information, e.g. usernames, password, database names, etc. The user has to push that to the application manually, for example by updating the DeploymentConfig in the web interface (Application in the left-hand menu under Deployments).

Git Hosting
OpenShift v2 had integrated Git, allowing the user to git push into the platform to trigger the deployment action. OpenShift 3 does not enforce this workflow anymore. OpenShift 3 can simply work with any possible git hosting and integrate using webhooks to trigger deployment actions.
You can use Github or Gitlab (or any other git hosting) and configure the hosting to trigger the build. When you go to Builds in the left menu under Builds, choose your build configuration and open the Configuration tab where on the right side are triggers including webhook triggers.

Real-World Example
First open OpenShift v2 console with your application, the screen should look similar to what’s on the below screenshot:

We will need the source code of the application and we need to know what cartridges are used.
Step 1 - getting the source code
Use the git URL to clone the source code to your machine
$ git clone <source url>
In case you have .openshift directory in your repository, remove it
$ rm -rf .openshift
and upload the source code to your git hosting of choice, in my case I am going to use Gitlab
$ git remote add github <gitlab url>
$ git push -u github master
Step 2 - deploying the source code
Once we have the code, we can deploy it on OpenShift 3. In my case it’s a Ruby application, so I am going to deploy Ruby using the Ruby Source-To-Image builder.
From command line, I enter in the following command:
$ oc new-app --name=myapp ruby~<gitlab url>
Or you can use the web interface
Add to project -> Browse catalogue -> Ruby -> Select the latest version
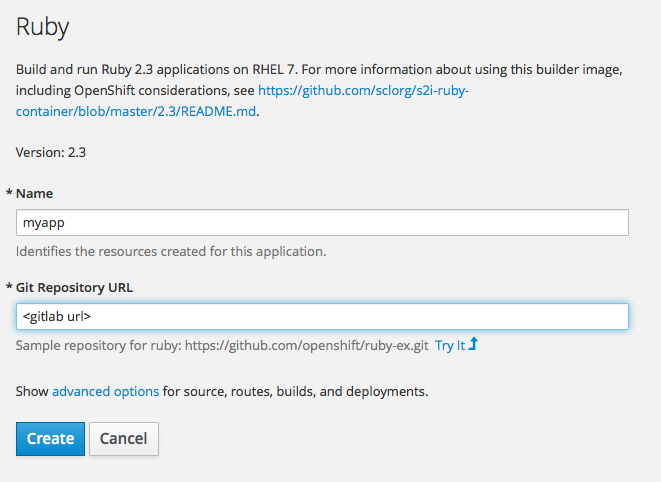
and by clicking “Create” deploy the application.
With both approaches you shall end up with an application running on OpenShift, however, it will be failing as it does not have any database backend, yet. On the dashboard you should see the following:
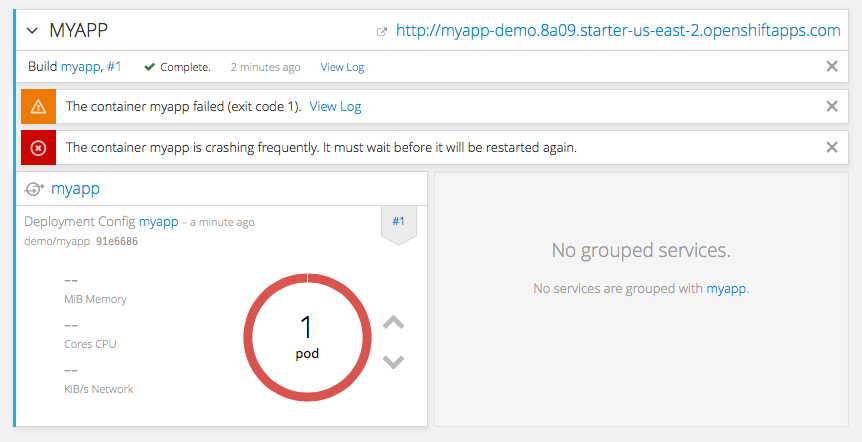
Step 3 - deploying the database
Next step is to deploy the database, in this example we are going to deploy a PostgreSQL database. Go to the web console and deploy the database using
Add to project -> Browse catalogue -> Data Stores -> PostgreSQL (Persistent) -> Keep or change the default options -> Create
On the next page you will see a blue box similar to the one on this picture, write down all the connection information, as we will need to make those available to our application
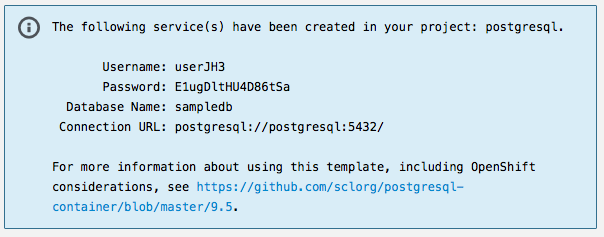
Step 4 - linking the application & database
I have kep the “Database service name” defaulted to “postgresql” as you can see on this picture
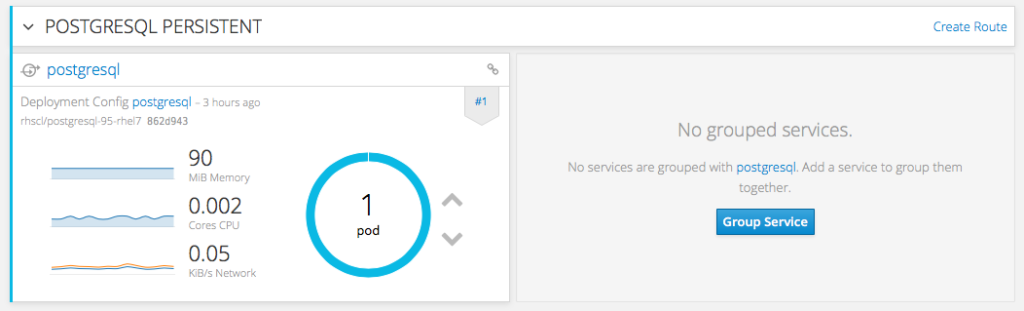
That means that OpenShift is going to provide environment variables
- POSTGRESQL_SERVICE_HOST
- POSTGRESQL_SERVICE_PORT
to connect to the database, these replace the original
- OPENSHIFT_POSTGRESQL_DB_HOST
- OPENSHIFT_POSTGRESQL_DB_PORT
known from OpenShift v2. These will be automatically injected into our application container, so the only action required is to change our code to consume the information from the new variables.
The other three environment variables from OpenShift v2
- OPENSHIFT_APP_NAME
- OPENSHIFT_POSTGRESQL_DB_USERNAME
- OPENSHIFT_POSTGRESQL_DB_PASSWORD
Have no special meaning in OpenShift 3 and are not automatically injected in any way from the PostgreSQL deployment. To save us some work, we can reuse the names (but as well, there no problem in changing the names).
To inject the information into the application deployment we can either run this command from the cli
$ oc env dc myapp OPENSHIFT_APP_NAME="<db name>" OPENSHIFT_POSTGRESQL_DB_USERNAME="<username>" OPENSHIFT_POSTGRESQL_DB_PASSWORD="<password>"
the actual values come from the blue rectangle we have seen before.
Step 5 - setting up webhook
We have changed the code, but have not yet deployed it. Before we do so, we should configure a webhook to automatically trigger build of our application whenever we push to the git hosting (in my case Gitlab).
From the command line you can run this command
$ oc describe bc myapp
And you will see the web hooks printed to the console. Or from the web UI, go to
Builds -> Builds -> myapp -> Configuration
And the webhooks are available in the “Triggers” section of the page
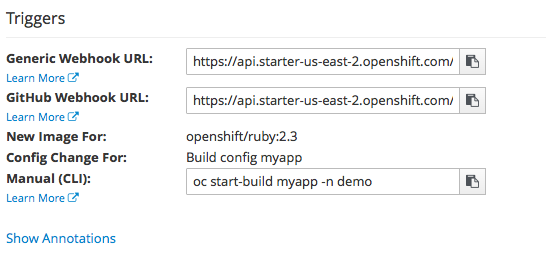
Setup the webhook and commit the code changes in your repository and push them to the git hosting. OpenShift will automatically trigger the build for you and will redeploy the application.
Once finished there is the application running on OpenShift 3 with PostgreSQL backend.
Step 6 - exporting & importing database data
Last step is to transfer the data from the old database to the new one.
First we need to export the database, to do so, we shall forward the postgresql port from the old database to your local machine. You will need the old “rhc” command
$ rhc port-forward <application name>
and now we shall dump the PostgreSQL database
$ pg_dump -h 127.0.0.1 -U <user> -W <app name > db.dump
and you will be prompted for a password. The username, password and application name is available on application detail page in the original OpenShift v2 console.
Now we can stop port-forwarding to OpenShift v2 and will need to open connection to OpenShift 3. From the command line run
$ oc get pods
and find the name of the postgresql pod. Then start the port forwarding
$ oc port-forward <pod name> 5432
and finally restore the data
$ cat db.dump | psql -h 127.0.0.1 -U <user name> -W <db name>
The database name, username and password are those that were shown before in the blue box and we set then as environment variables to the application.
Step 7 - Profit!
The application is now running on OpenShift 3 and you can easily benefit from the awesomeness of the new platform!
For more information on migrating applications from OpenShift v2 to OpenShift 3, please see our Migrating Applications Guide.
About the author
More like this
Reclaiming infrastructure autonomy: The 180-day mandate for virtualization service providers
Why Red Hat partners are the ultimate telco business asset
Crack the Cloud_Open | Command Line Heroes
Edge computing covered and diced | Technically Speaking
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds