Many platform failures at scale often stem from overlooked control plane dependencies. Among them, the container registry is one of the most critical.
In the early stages of Kubernetes and Red Hat OpenShift adoption, the registry is treated as a supporting component, a place to store and retrieve images. That assumption quietly breaks as a platform scales across environments, supports production workloads, and introduces disaster recovery requirements. At scale, the container registry becomes part of the platform control plane, not its artifact store: Thus is the very nature of the “infrastructure as code” mentality.
The container registry often becomes a “hidden” control point as platforms mature. It directly influences deployment reliability, security posture, cost efficiency, and disaster recovery readiness.
Yet in many organizations, registry strategy remains reactive. Replication is added after incidents. Storage grows without governance. Disaster recovery environments drift out of sync. These gaps are rarely visible until they surface during outages, failover events, or trustworthiness incidents.
This configuration is not a tooling problem. It is a strategic architecture decision that determines whether the platform operates predictably at scale or accumulates hidden operational risk.
The business problem: When the registry becomes a bottleneck
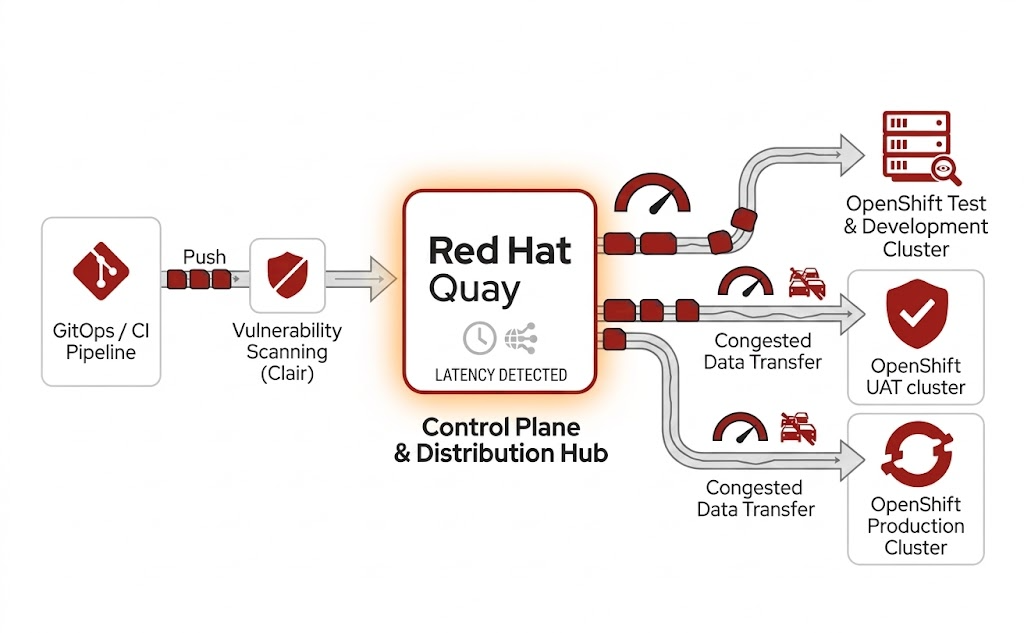
A workflow diagram describing the path of a workload from a git push event through to production via Clair and Red Hat Quay.
In modern platform engineering, the container registry is no longer just storage. It serves as:
- Distribution hub: A central location for all software artifacts.
- Trustworthiness enforcement point: Provides trusted images, integrating with vulnerability scanning, enforcing trusted content policies, and acting as a gatekeeper for what's allowed into runtime environments.
- Dependency: Required for platform availability and disaster recovery.
In enterprise platforms such as Red Hat OpenShift, registries like Red Hat Quay are commonly used to provide scalable, security-centric, and policy-driven image management across clusters and environments.
When this layer is under-designed, it effects the entire organization:
- Deployment failures: When required images are unavailable in target environments.
- Delayed disaster recovery: Incomplete or inconsistent image availability leads to delayed disaster recovery.
- Uncontrolled cost growth: Ungoverned image storage can lead to needless, and often unnoticed, expenditure.
- Erosion of developer trust: Developers expect and need platform reliability to be effective.
These failures rarely originate from compute or networking limitations. They emerge from overlooked control-plane dependencies where the registry silently becomes a single point of failure.
The strategic question every enterprise must answer
At scale, organizations operating across multiple environments or data centers face a defining decision: Should container images be replicated automatically through cross-site scripting, or should distribution be controlled and selective?
This decision is not about features. It reflects how an organization balances control and automation, cost and convenience, operational discipline and simplicity, disaster recovery readiness and data volume.
The choice typically manifests as a decision between geo-replication and controlled data mirroring. In some enterprise environments, a third pattern is introduced: Pull-through or proxy caching. This model allows the registry to cache upstream images on demand, reducing direct external dependencies. However, caching does not replace the need for controlled replication of internally built artifacts or disaster recovery readiness.
Two architectural paths, two different outcomes
These architectural patterns are commonly implemented using enterprise registries such as Red Hat Quay, which support both geo-replication and controlled data mirroring Models.
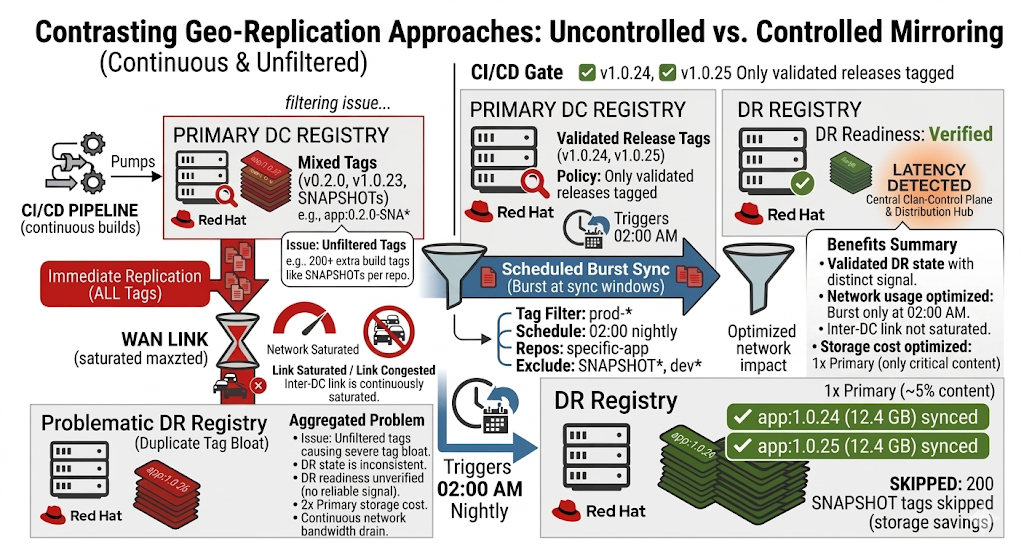
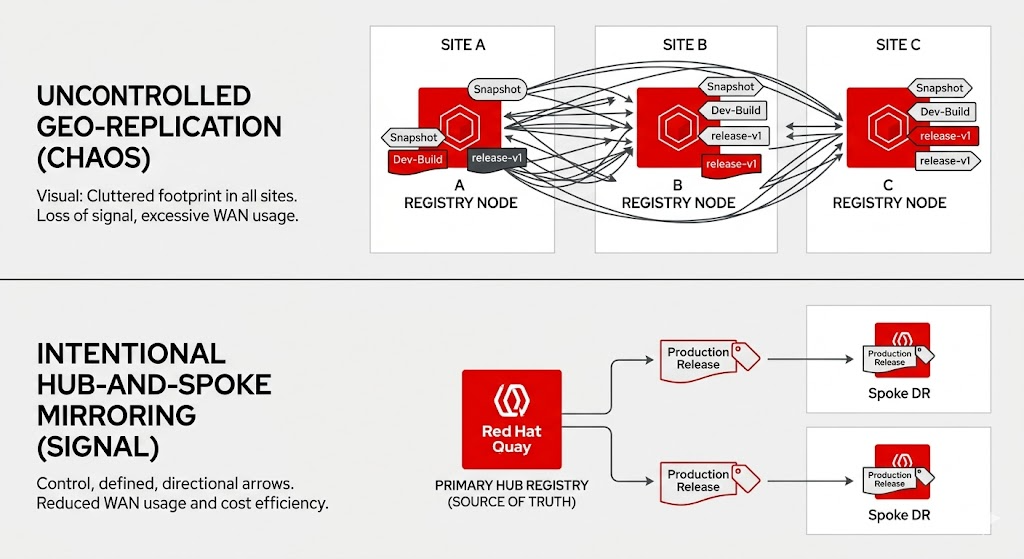
A diagram contrasting uncontrolled geo-replication with intentional hub-and-spoke mirroring.
Geo-Replication: Simplicity with hidden cost
Geo-replication offers an intuitive model: images pushed to the primary registry are automatically replicated to secondary locations within a defined scope.
In many environments, this model works well initially, but begins to show limitations as scale and operational complexity increase. At a small scale, this provides convenience and minimal operational overhead. However, as environments grow, the model introduces systemic challenges:
- A broad replication scope, often including temporary and non-production artifacts
- Continuous network use, increasing infrastructure cost
- Storage duplication across sites without prioritization
- Reduced clarity on which images are actually required for recovery
The result is inefficiency where it matters most.
Controlled mirroring: Precision with responsibility
Mirroring introduces a philosophy different from geo-replication. Instead of pushing everything everywhere, it supports selective, policy-driven distribution of images. In this instance, organizations define which repositories are relevant, which tags represent production-ready artifacts, and when synchronization occurs.
This approach delivers clear advantages:
- Reduced infrastructure cost through selective replication
- Clearer disaster recovery by focusing on production artifacts
- Decoupled environments, allowing independent operation
- Greater governance over software distribution
This model also introduces a defined recovery point objective (RPO), because synchronization is scheduled rather than continuous.
This control does come with a trade-off. It requires operational ownership. For organizations with established operational practices, this model provides greater long-term control, but it requires consistent ownership.
The real trade-off: Automation versus operational maturity
The decision between geo-replication and mirroring is fundamentally a reflection of organizational maturity.
- Geo-replication: Prioritizes automation and simplicity, but sacrifices control and efficiency at scale.
- Mirroring: Prioritizes control and optimization, but requires discipline, monitoring, and governance.
There is no universally correct choice. The right model depends on how much control your organization is prepared to own.
The hidden risk: Operational gaps in distribution strategy
The significant failures in registry architecture don't come from technology limitations. They emerge from gaps in ownership and governance. A common pattern during disaster recovery is that secondary environments lack the exact set of production images required, not because replication failed but because no policy explicitly defined what needed to be replicated.
In a controlled distribution model, an organization must actively manage synchronization health and monitoring, policy enforcement for image inclusion and exclusion, and validation of disaster recovery readiness. Without these considerations, environments silently drift, disaster recovery systems fall behind, and issues remain undetected until they matter most.
What this means is that introducing control without introducing accountability creates hidden failure modes.
Lifecycle management: Where cost and reliability intersect
One of the often overlooked, yet highly effective capabilities in registry architecture is pruning (the controlled removal of unused or outdated images based on defined policies).
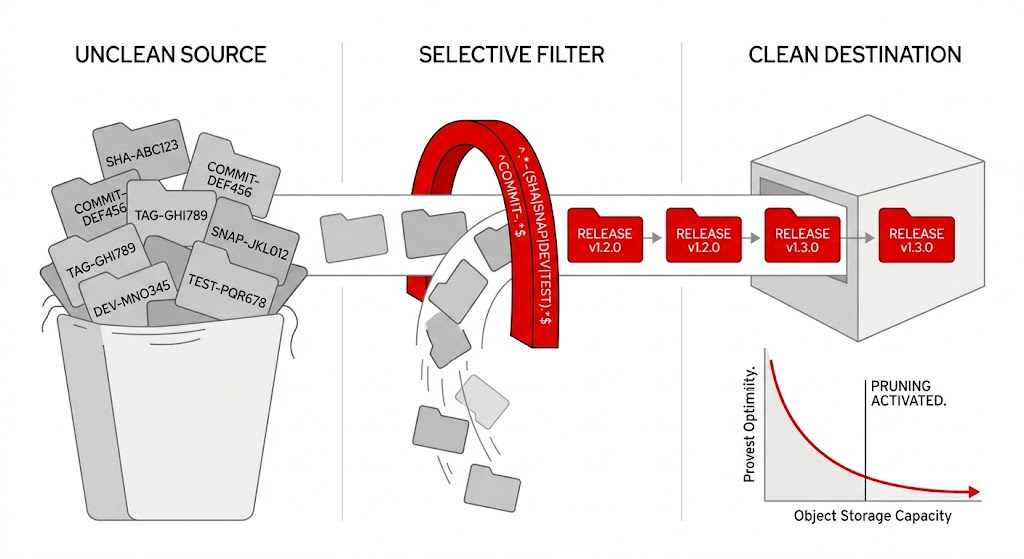
A diagram showing the path of unclean source code, through filtering, to a clean destination.
Without pruning, registries accumulate artifacts indefinitely, turning into high-cost, low-value storage systems that degrade over time. In practice, this accumulation often goes unnoticed until storage costs or replication delays begin to surface.
From a business perspective, the absence of pruning creates three compounding risks:
- Uncontrolled storage cost growth
- Operational slowdown in replication, synchronization, and scanning
- Disaster recovery ambiguity, where critical images are buried among non-critical images
A high-performing organization treats pruning not as a maintenance task, but as a governance mechanism. You must define automated policies to:
- Expire ephemeral and development artifacts
- Retain only production-relevant images
- Align stored content with recovery requirements
The outcome is a registry that remains lean, cost-efficient, and operationally meaningful.
Network design: The foundation of registry reliability
The registry is fundamentally a network-driven system. Every operation depends on reliable connectivity across clusters, trustworthiness systems, and external sources. In many enterprise deployments, registries such as Red Hat Quay are exposed using highly available endpoints backed by load-balancing solutions on site or in bare-metal environments.
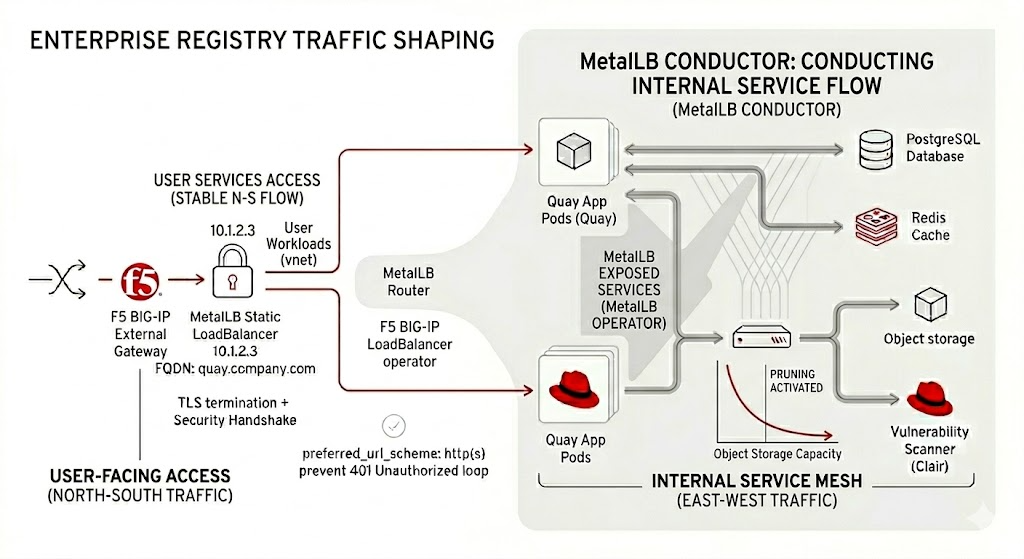
An architectural diagram describing registry traffic shaping and the MetalLB Conductor.
This architectural approach helps ensure that registry access remains stable and less dependent on underlying infrastructure variability. Without this, image pulls fail during node rescheduling or failover, TLS validation breaks due to endpoint inconsistency, and disaster recovery environments can't reliably access required artifacts.
These aren't performance issues, but availability failures. From a decisionmaker perspective, investing in stable registry access is about ensuring platform continuity, including:
- Stable and predictable endpoints
- Consistent DNS and certificate management
- Separation of internal and external traffic flows
- Predefined disaster recovery access paths
The cost of getting it wrong
When registry architecture is treated as an afterthought, the consequences are not immediate, but they are inevitable. They surface during disaster recovery events, platform upgrades, trustworthiness incidents, and large-scale deployments. In other words, the worst possible moments.
At that point, the cost is a major business effect, resulting in downtime, delayed recovery, increased operational effort, and a severe loss of confidence in the platform.
What high-performing organizations do differently
Organizations that successfully scale platform infrastructure treat the container registry as a first-class architectural component:
- Define distribution strategy early
- Establish lifecycle and pruning policies from day one
- Continuously validate disaster recovery readiness
- Invest in observability and ownership
From storage to strategy
At scale, the container registry is not a storage system, it is a reliability system. The container registry is often one of the last components to receive architectural attention, and one of the first to fail under pressure. Designing it correctly means making a strategic decision on how software is distributed, controlled, and trusted across environments.
An organization that recognizes this builds platforms that scale predictably.
A registry is never just storage. It's a control point, and when it fails, everything depending on it can fail with it. Organizations that succeed in this space are those that make deliberate decisions about control, distribution, and ownership. Click here to learn more about our Registry, Red Hat Quay.
Product trial
Red Hat Learning Subscription | Product Trial
About the author

Viral Gohel is a Senior Technical Account Manager at Red Hat. Specializing in Red Hat OpenShift, middleware, and application performance, he focuses on OpenShift optimization. With over 14 years at Red Hat, Viral has extensive experience in enhancing application performance and ensuring optimal OpenShift functionality.
More like this
Friday Five — May 8, 2026 | Red Hat
When AI finds the bugs: Why defense in depth was always the answer
Collaboration In Product Security | Compiler
Keeping Track Of Vulnerabilities With CVEs | Compiler
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds