

はじめに
Red Hat OpenShift 上の仮想マシン (VM) の DR 戦略は、予定外の停止時にビジネス継続性を維持するために不可欠です。重要なワークロードを Kubernetes プラットフォームに移行する際、それらのワークロードを迅速かつ確実に復旧する機能が運用上の重要な要件になります。
クラウドネイティブ環境では一時的なステートレス VM が一般的になっているものの、ほとんどのエンタープライズ VM ワークロードは依然としてステートフルです。これらの VM には、再起動や移行中に再接続できる永続ブロックストレージが必要です。その結果、ステートフル VM の DR では、一般的にステートレスなコンテナベースのアプリケーションに焦点を当てた以前の Kubernetes DR パターン (Spazzoli、2024 年) で対処されている課題とは大幅に異なる課題がもたらされます。
このブログ記事では、ステートフル VM に特有の要件について触れます。まず、クラスタとストレージ・アーキテクチャの選択がフェイルオーバーの実現可能性、レプリケーション動作、RPO/RTO 目標にどのように影響するかを確認します。次にオーケストレーション・レイヤーについて調べ、Red Hat Advanced Cluster Management、Helm、Kustomize、GitOps パイプラインなど、Kubernetes ネイティブのツールがワークロードの配置とリカバリーをどのように制御するかを示します。最後に、ブロックストレージと Kubernetes マニフェストの両方をレプリケートする高度なストレージ・プラットフォームが、どのようにリカバリープロセスを効率化し、インフラストラクチャをまたいでアプリケーションレベルの自動化を行うのかについて考察します。
用語の意味
先に進む前に、いくつかの重要な用語を定義します。
障害:
この記事での「障害」という用語は、「サイトの損失」を意味します。DR について考えるとき、ビジネスサービスの中断を最小限に抑えることが常に重要です。そのため、サイトの機能が停止した場合には、サービスをできるだけ迅速かつ効率的に代替サイトでリストアするための DR プランを実装する必要があります。
注:DR プランが実行されるのは、サイトの機能が失われた場合だけではありません。主要なコンポーネントに障害が発生し、障害が発生したコンポーネントのリストア中に個別のビジネスサービスを代替サイトにシフトする必要がある場合は、個々のビジネスサービスに対して DR プランを実行するのが一般的です。
コンポーネントの障害:
コンポーネントの障害とは、組織内のビジネスアプリケーションのサブセットに影響する、1 つ以上のサブシステムの障害を指します。この障害モードでは、プライマリーサイト内の代替システムに処理をフェイルオーバーする必要があります。あるいは、個別の DR プランを実行して、ビジネスアプリケーションの処理をセカンダリーサイトにシフトする必要があります。
目標復旧時点 (RPO):
RPO は、災害または障害イベントからの復旧後、データ損失が組織の許容範囲を超えるまでの、失っても構わないデータの最大量 (測定単位は時間) と定義されます。
目標復旧時間 (RTO):
RTO は、組織がサービスが利用できない状態を許容できる最大時間と定義されます。アーキテクチャの選択は RTO に影響を与えますが、このブログ記事ではそれらの検討事項について詳細に説明することはしません。
Metro-DR と Regional-DR:
DR には、Metro-DR と Regional-DR の 2 つのタイプがあります。
- Metro-DR は、データセンター間の距離が十分に近接しており、ネットワーク・パフォーマンスによって同期データレプリケーションが可能です。同期レプリケーションには、RPO ゼロを達成できるというメリットがあります。
- Regional-DR は、同期レプリケーションをサポートできないほどデータセンター間が離れているために、非同期レプリケーションを実行せざるを得ない場合に使用します。非同期レプリケーションでは、ほぼ確実にデータが失われます。このブログ記事の目的としてはデータ損失の量は重要ではありません。
注:ストレージ・インフラストラクチャが同期レプリケーションをサポートしていない場合、Metro-DR には Regional-DR アーキテクチャが使用されます。
再起動ストーム:
再起動ストームは、同時に再起動しようとする VM の数が多すぎて、ハイパーバイザーとサポートするインフラストラクチャが対応できない場合に発生するイベントで、結果としてどの VM も再起動できなかったり、VM の再起動に許容範囲を超える大幅な時間がかかったりすることがあります。これは、悪意のないサービス拒否攻撃とも呼ばれます。
ビジネス継続性に対するアーキテクチャアプローチ
ビジネス継続性と DR を実現するためのアプローチはいくつかあります。このトピックの一般的な説明として、まず Cloud Native Computing Foundation (CNCF) のホワイトペーパー、「Cloud Native Disaster Recovery for Stateful Workloads」(Spazzoli、2024 年) を確認することから始めましょう。おおまかに言うと、DR には次の図に示す 4 つのアーキタイプアローチがあります (これらのアプローチの詳細な説明についてはホワイトペーパーをお読みください)。
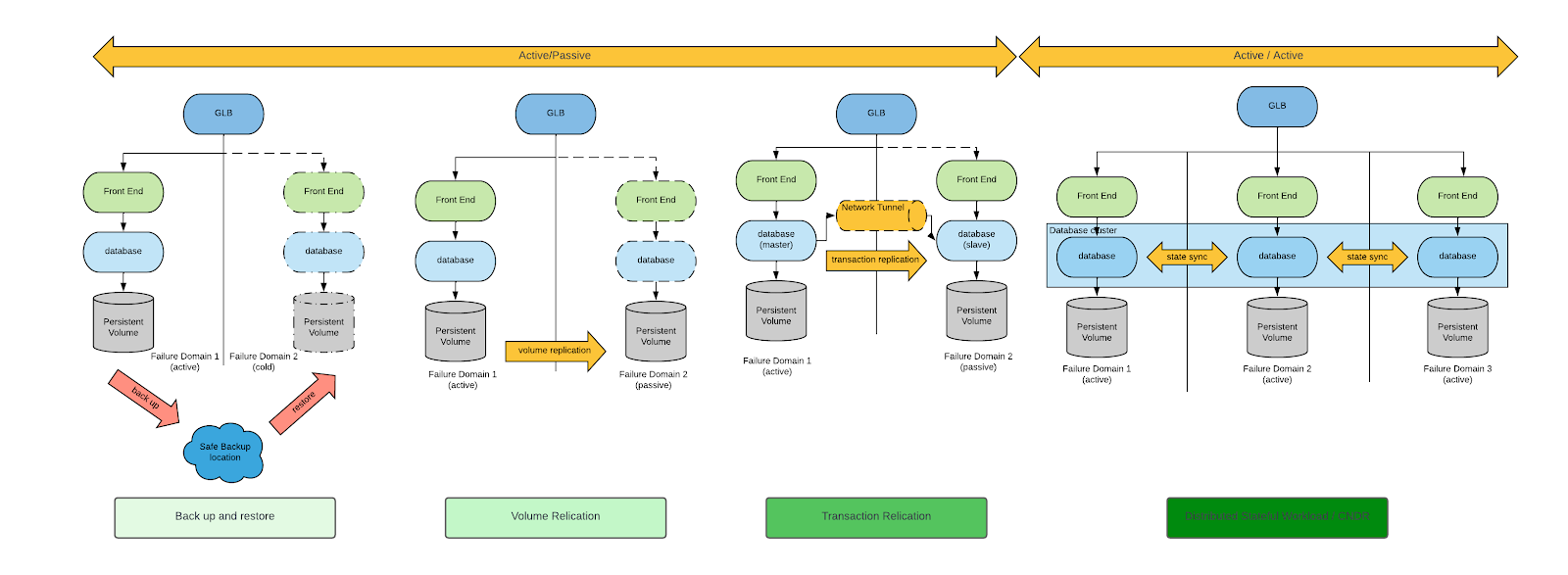
VM の DR 要件を検討する場合、適切な DR パターンはバックアップとリストア、およびボリューム・レプリケーションのみです。
バックアップとリストア、およびボリューム・レプリケーションはいずれも実行可能なアプローチですが、ボリューム・レプリケーションベースの DR アプローチは RPO と RTO の両方を最小限に抑えます。このため、ここではボリューム・レプリケーションに基づく DR アプローチのみに焦点を当てます。
分析する分野を絞り込んだので、DR に対する 2 つのアーキテクチャアプローチについて説明していきます。これらはそのアーキテクチャ上、ボリューム・レプリケーションのタイプによって区別されます。
- 単方向レプリケーション
- 対称レプリケーション、または双方向レプリケーション
単方向レプリケーション
単方向レプリケーションでは、1 つのデータセンターから別のデータセンターにボリュームがレプリケートされますが、逆方向へはレプリケートされません。レプリケーションの方向はストレージアレイを介して制御され、ボリューム・レプリケーションは同期または非同期で行われます。その選択は、ストレージアレイの機能と 2 つのデータセンター間のレイテンシーによって決まります。非同期レプリケーションは、データセンター間のレイテンシーが高く、両方のデータセンターが地理的に同じ地域にあることが多いものの同じメトロポリタンエリアにはないデータセンター間に適しています。
単方向レプリケーションのアーキテクチャは、次の図のように表されます。
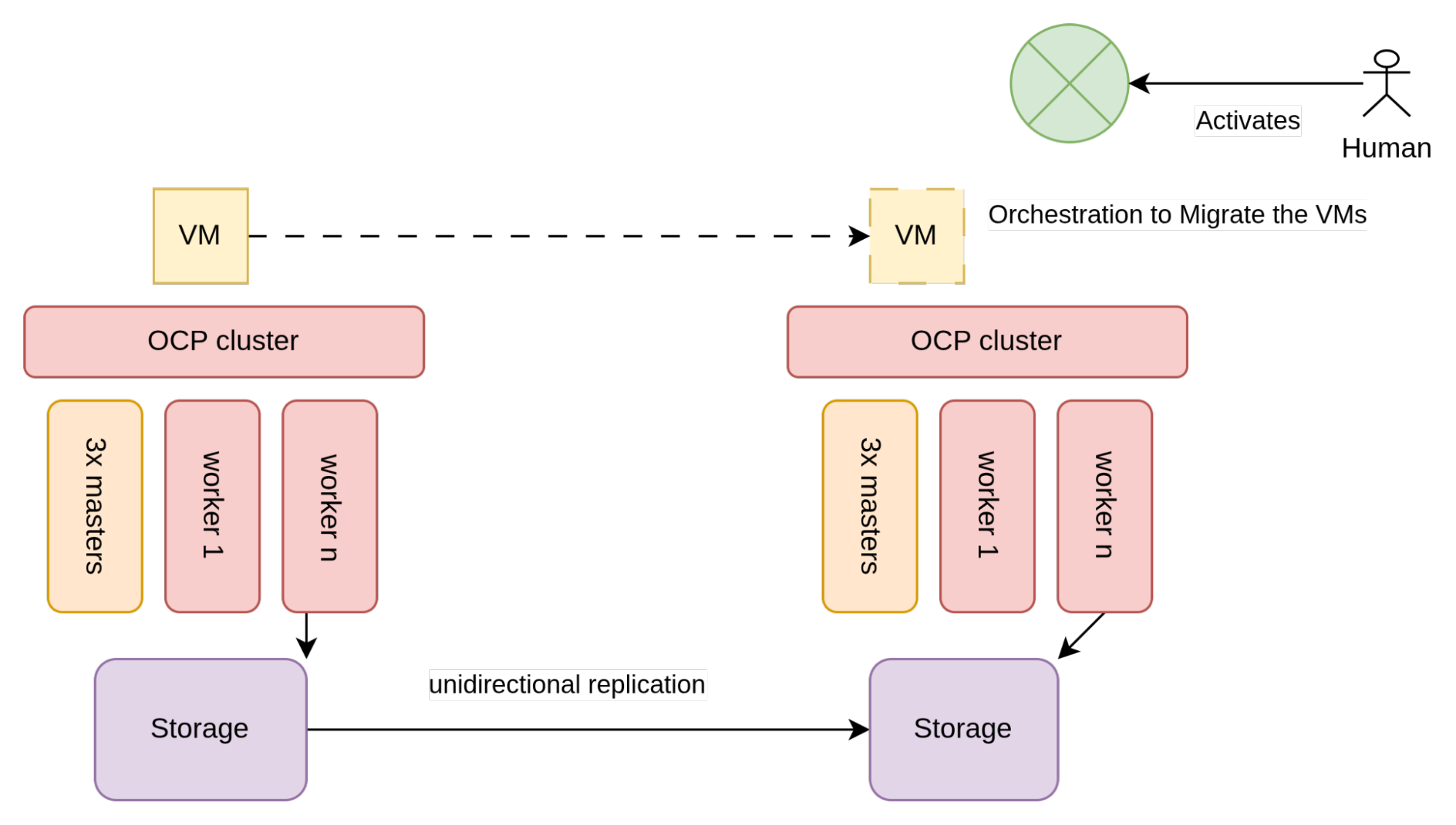
図 2 に示すように、VM が使用するストレージ (通常は SAN アレイ) は、単方向レプリケーションを可能にするように構成されています。
各データセンターには 2 つの異なる OpenShift クラスタが存在し、それぞれがローカルストレージアレイに接続されています。クラスタは互いを認識しないため、このアーキテクチャを実装するための唯一の制約は、ストレージベンダーによってもたらされます。具体的には、単方向レプリケーションを実現するために満たす必要がある要件によってもたらされます。
単方向ボリューム・レプリケーションの考慮事項
ボリューム・レプリケーションは、Kubernetes CSI 仕様では標準化されていません。そのため、ストレージベンダーはこの機能を有効にするために、プロプライエタリーなカスタムリソース定義 (CRD) を構築しています。おおまかに言うと、この機能を持つベンダーは次の 3 つの成熟度に分けられます。
- ボリューム・レプリケーション機能を CSI レベルで利用できない、または利用できるものの、ストレージアレイ API を直接呼び出さないと適切な DR オーケストレーションを作成できない
- ボリューム・レプリケーション機能を CSI レベルで利用できる
- ボリューム・レプリケーション機能が利用可能であり、ベンダーが namespace メタデータ (namespace に存在する VM とその他のマニフェスト) のリストアも管理する
このような断片化を考慮すると、Regional-DR の設定のために、ベンダーに依存しない DR リカバリープロセスを策定するのは簡単ではありません。適切な DR オーケストレーションを作成するために必要な記述量は、ストレージベンダーによって異なります。
OpenShift ノード障害、ストレージアレイ障害 (コンポーネント障害)、データセンター全体の障害 (これが実際の DR シナリオ) といったさまざまな障害モードにおける、このアーキテクチャの動作を見てみましょう。
OpenShift ノードの障害
ノード (コンポーネント) に障害が発生した場合、OpenShift Virtualization スケジューラーは、クラスタ内でその障害ノードの次に最も適切なノードで VM を自動的に再起動する役割を担います。このシナリオでは、これ以上のアクションは必要ありません。
ストレージアレイの障害
ストレージアレイに障害が発生すると、そのストレージアレイに依存しているすべての VM にも障害が発生します。このシナリオでは、DR プロセスを実施する必要があります(関連手順については「障害復旧プロセス」のセクションを参照してください)。
データセンターの障害
データセンターに障害が発生した場合は、データセンター内で障害の影響を受けないすべての VM を再起動する DR プロセスを実施する必要があります。ここでは自動化が重要な役割を果たします。ただし、このプロセスは通常、重大なインシデント管理のフレームワーク内で人間が開始します。次のセクションでは、関連する手順の概要を説明します。
障害復旧プロセス
DR 手順は非常に複雑になりがちですが、簡単に言うと、DR プロセスでは次のことを考慮する必要があります。
- 同じアプリケーションの一部である VM は、一貫した方法でボリュームをレプリケートする必要があります。これは通常、それらの VM のボリュームが同じ一貫性グループに含まれていることを意味します。
- 一貫性グループ内のボリュームをレプリケートするかどうか、またどの方向にレプリケートするかを制御できる必要があります。通常、ボリュームはアクティブサイトからパッシブサイトにレプリケートされます。フェイルオーバー中、ボリュームはレプリケートされません。フェイルバックの準備フェーズ中に、ボリュームがパッシブサイトからアクティブサイトにレプリケートされます。フェイルバック中に、ボリュームはレプリケートされません。
- もう一方のデータセンターで VM を再起動することが可能で、それらの VM は、レプリケートされたストレージボリュームにアタッチできる必要があります。
- 再起動ストームを回避するために、VM の再起動を調整することが必要な場合があります。さらに、最も重要なアプリケーションを最初に起動したり、データベースなど、他のサービスが依存するコンポーネントをそれらのサービスより先に起動したりするように、VM の再起動シーケンスの優先順位をつけることが望ましい場合がよくあります。
コストに関する考慮事項
OpenShift クラスタの設定方法に応じて、ウォームまたはホット DR サイトと見なされる場合があります。ホットサイトは完全にサブスクライブする必要があり、ウォームサイトはサブスクライブする必要はありません (場合によってはコストを削減できます)。
一般に、DR サイトでアクティブなワークロードが実行されていない場合、ウォームと見なすことができます。具体的には、永続ボリューム (PV) や永続ボリューム要求 (PVC)、さらには実行されていない VM を構成し、障害発生時に起動できるようにすることで、ウォームサイトの状態を維持することができます。
対称アクティブ/パッシブ
ワークロードをすべてアクティブサイトに配置することは一般的な方法ではありません。そうではなく、組織はプライマリーデータセンターとセカンダリーデータセンター間で半々に分割します。これは、何らかの障害によってすべてのサービスが一度に停止されないようにするための実用的なアプローチです。さらに、これによってリカバリー作業を全体的に減らすことができます。
各データセンターにアクティブな VM を分散させる場合、もう一方にフェイルオーバーできるようにそれぞれを設定します。このセットアップは、対称アクティブ/パッシブと呼ばれることがあります。
対称アクティブ/パッシブは、OpenShift Virtualization と前述のアーキテクチャで機能します。対称アクティブ/パッシブの場合、両方のデータセンターがアクティブと見なされるので、すべての OpenShift ノードをサブスクライブする必要があることに注意してください。
対称レプリケーション
対称レプリケーションでは、ボリュームが双方向に同期してレプリケートされます。その結果、両方のデータセンターにアクティブなボリュームが存在し、それらのボリュームに対して書き込みを行うことができます。これを可能にするには、ネットワーク・レイテンシーが極めて低い (たとえば、5 ミリ秒未満) データセンターが 2 つ必要です。これは通常、2 つのデータセンターが同じメトロポリタンエリアにある場合に可能なため、このアーキテクチャは Metro-DR とも呼ばれます。このような状況では次のアーキテクチャを使用できます。

このアーキテクチャでは、VM により使用されるストレージ (通常は SAN アレイ) が 2 つのデータセンター間で対称レプリケーションを実行するように設定されます。
これにより、2 つのデータセンターに拡張された論理ストレージアレイが作成されます。対称レプリケーションを可能にするには、「監視サイト」が必要です。これは、ネットワークやサイトに障害が発生した場合に独立したアービトレーターとして機能し、「スプリットブレイン」シナリオを防ぐものです。
監視サイトは、クォーラムの作成とスプリットブレイン・シナリオの解決に使用されるため、2 つの主要データセンターと (レイテンシーの観点から) それほど近接している必要はありません。監視サイトは独立したアベイラビリティーゾーンであり、アプリケーション・ワークロードを実行せず、大容量である必要もありませんが、データセンターの運用に関しては、データセンターと同じサービス品質を持つ必要があります (物理/論理セキュリティ、電源管理、冷却など)。
ストレージがデータセンター間で拡張され、その上で OpenShift が拡張されます。これを高可用性アーキテクチャで実装するには、OpenShift コントロールプレーンに 3 つのアベイラビリティーゾーン (サイト) が必要です。これは、Kubernetes の内部 etcd データベースが信頼性の高いクォーラムを維持するために少なくとも 3 つの障害ドメインを必要とするためです。これは一般的に、コントロールプレーン・ノードのうちの 1 つのストレージ監視サイトを利用して実装されます。
ほとんどのストレージエリア・ネットワーク (SAN) ベンダーは、自社ストレージアレイの対称レプリケーションをサポートしています。ただし、すべてのベンダーがこの機能を CSI レベルで提供しているわけではありません。CSI レベルで対称レプリケーションをサポートするストレージベンダーが、必要な前提条件と設定を満たしていると想定した場合、PVC が作成されるとマルチパス論理ユニット番号 (LUN) がプロビジョニングされます。この LUN には両方のデータセンターに到達するパスが含まれているため、すべての OpenShift ノードは両方のストレージアレイに接続できるように、接続を有効にする必要があります。マルチパスデバイスは通常、非対称論理ユニットアクセス (ALUA) 構成 (Pearson IT Certification、2024 年) (アクティブ/パッシブであり、アクティブパスは最も近いアレイへのパスになります)、または異なる重み付けを持つ (最も近いアレイの重み付けが高い) アクティブ/アクティブパスを使用して作成されます。
一部のベンダーは、ファイバーチャネル接続が「均一」ではない場合、つまり、1 つのサイト上のノードがローカルストレージアレイにしか接続できない場合でも、このアーキテクチャを許可しています。この場合、ALUC 設定はもちろん作成されません。
このクラスタトポロジーは、コンポーネントの障害だけでなく災害による障害から保護するのにも役立ちます。さまざまな障害モードにおけるこのアーキテクチャの動作を見てみましょう。
OpenShift ノードの障害
ノード (コンポーネント) に障害が発生した場合、OpenShift Virtualization スケジューラーは、クラスタ内でその障害ノードの次に最も適切なノードで VM を自動的に再起動する役割を担います。このシナリオでは、これ以上のアクションは必要ありません。
ストレージアレイの障害
マルチパス LUN は、2 つのストレージアレイのうちいずれかに障害が発生した場合や、メンテナンスのためにオフラインになった場合でも、サービスの継続性を確保できます。均一な接続のシナリオでは、マルチパス LUN のパッシブパスまたは重み付けの少ないパスを使用して VM を他のアレイに接続します。この障害は VM に対して完全に透過的であるため、ディスク I/O のレイテンシーがわずかに増加する可能性があります。不均一な接続のシナリオでは、接続可能なノードに VM を移行する必要があります。
データセンターの障害
データセンター全体が使用不能になると、拡張された OpenShift によって複数のノードの同時障害として認識されます。OpenShift は、「OpenShift ノードの障害」セクションで説明したように、もう一方のデータセンター内のノードへの VM のスケジューリングを開始します。
ワークロードの移行先となる十分な予備容量があることを前提に、すべてのマシンは最終的にもう一方のデータセンターで再起動されます。再起動された VM の RPO はゼロで、RTO は次の時間の合計となります。
- ノードが準備未完了状態であることを OpenShift が認識するまでの時間
- ノードのフェンシングにかかる時間
- VM の再起動にかかる時間
- VM のブートプロセスの完了にかかる時間
この DR メカニズムは基本的に完全に自律的であり、人的介入は必要ありません。これは必ずしも望ましいとは限りません。再起動ストームを回避するために、再起動される VM とこのプロセスが開始されるタイミングを制御することが望ましい場合がよくあります。
Metro-DR の考慮事項
このアプローチに関する考慮事項を以下に示します。
- VM は通常 VLAN に接続されているため、データセンター間で分散させるには、VLAN もメトロデータセンター間に拡張される必要があります。場合によっては、これは望ましくありません。
- 多くの場合、監視サイト管理ネットワーク (OpenShift ノードネットワーク) は、メトロデータセンターの管理ネットワークと同じ L2 サブネットにありません。
- OpenShift コントロールプレーンとストレージアレイ・コントロールプレーンが 2 つの単一障害点 (SPOF) となるため、これは完全な DR ソリューションとは見なされないという考え方もあります。この SPOF は論理的な観点を意図したものであり、物理的な観点からは冗長性があります。しかし、OpenShift またはストレージアレイへの 1 つの誤ったコマンドで、理論上、環境全体が消去される可能性があることは事実です。このため、このアーキテクチャは、最も重要なワークロード用に従来の Regional-DR アーキテクチャにデイジーチェーン接続されることがあります。
- 何も指定しないと、DR が発生したときに OpenShift は障害の影響を受けるデータセンターにあるすべての VM を同時に、正常なデータセンターへと自動的に再スケジュールします。これにより、再起動ストームと呼ばれる現象が発生する可能性があります。Kubernetes には、どのアプリケーションをいつフェイルオーバーするかを制御することで、このリスクを軽減する機能が数多くあります。再起動ストームの概念については、後のセクションで説明します。
コストに関する考慮事項
対称レプリケーションの場合、両方のサイトは単一のアクティブな OpenShift クラスタに属するため、完全にサブスクライブする必要があります。単方向レプリケーションの場合、各サイトを 100% オーバープロビジョニングする必要があり、もう一方のサイトへの 100% のフェイルオーバーが可能である必要があります。
まとめ
単方向レプリケーション・アーキテクチャと対称レプリケーション・アーキテクチャのどちらを選ぶかにより、OpenShift Virtualization での DR 戦略全体の方向性が決まります。各モデルには、運用の複雑さ、インフラストラクチャのコスト、RPO/RTO の保証、自動化の可能性の間でトレードオフがあります。デュアルクラスタ設計またはストレッチクラスタ設計のいずれを選択する場合も、基盤となるアーキテクチャは、ビジネス継続性に関する期待やインフラストラクチャの制約と整合する必要があります。この基盤が整ったら、パート 2 では重点をインフラストラクチャからオーケストレーションに移し、ストレージだけでなく、障害が発生した場合に VM を配置、再起動、および制御する方法を見ていきます。
製品トライアル
Red Hat OpenShift Virtualization Engine | 製品トライアル
執筆者紹介
Bryon is a skilled infrastructure and software engineering specialist with deep expertise in AI/ML, Kubernetes, OpenShift, cloud-native architecture, and enterprise networking. With a strong background in storage technologies, infrastructure, and virtualisation, Bryon works across domains including system administration, AI model deployment, and platform engineering. He is proficient in C#, Golang and Python, experienced in container orchestration, and actively contributes to Red Hat-based solutions. Passionate about education and enablement, Bryon frequently develops technical workshops and training programs, particularly in AI/ML and DevOps. He is also a practising musician, blending his technical acumen with creative expression.
Raffaele is a full-stack enterprise architect with 20+ years of experience. Raffaele started his career in Italy as a Java Architect then gradually moved to Integration Architect and then Enterprise Architect. Later he moved to the United States to eventually become an OpenShift Architect for Red Hat consulting services, acquiring, in the process, knowledge of the infrastructure side of IT.
Currently Raffaele covers a consulting position of cross-portfolio application architect with a focus on OpenShift. Most of his career Raffaele worked with large financial institutions allowing him to acquire an understanding of enterprise processes and security and compliance requirements of large enterprise customers.
Raffaele has become part of the CNCF TAG Storage and contributed to the Cloud Native Disaster Recovery whitepaper.
Recently Raffaele has been focusing on how to improve the developer experience by implementing internal development platforms (IDP).
チャンネル別に見る

自動化
テクノロジー、チームおよび環境に関する IT 自動化の最新情報

AI (人工知能)
お客様が AI ワークロードをどこでも自由に実行することを可能にするプラットフォームについてのアップデート

オープン・ハイブリッドクラウド
ハイブリッドクラウドで柔軟に未来を築く方法をご確認ください。

セキュリティ
環境やテクノロジー全体に及ぶリスクを軽減する方法に関する最新情報

エッジコンピューティング
エッジでの運用を単純化するプラットフォームのアップデート

インフラストラクチャ
世界有数のエンタープライズ向け Linux プラットフォームの最新情報

アプリケーション
アプリケーションの最も困難な課題に対する Red Hat ソリューションの詳細
仮想化
オンプレミスまたは複数クラウドでのワークロードに対応するエンタープライズ仮想化の将来についてご覧ください