


DevOps and shared infrastructure have changed how we develop and operate applications. Previously, developers would run a copy of their entire complex system on their own machine. They might encounter issues including "works on my machine" problems, resource constraints, and the inability to quickly collaborate with others.
Most enterprise developers now work in a distributed environment, where resources can be shared and allocated where they're needed. As we onboard more data scientists into best practice-informed development processes, they are looking at similar challenges—separation, resources, productization, and more.
Out of our own need to process data produced daily across the company, a few years ago, we started working on Open Data Hub, an open source project that focuses on OpenShift and data science. This is a blueprint for putting data science components together on top of a scalable platform like OpenShift or Kubernetes.
At DevConf 2021, we presented a talk titled Cloud-native AI using OpenShift. This article (and a companion piece) summarize our presentation.
Cloud-native technologies and AI
Cloud-native technologies can be applied to artificial intelligence (AI) to accelerate machine learning (ML) from research to testing to production. According to the Cloud-Native Computing Foundation (CNCF):
Cloud-native technologies empower organizations to build and run scalable applications in modern, dynamic environments such as public, private, and hybrid clouds. Containers, service meshes, microservices, immutable infrastructure, and declarative APIs exemplify this approach.
These techniques enable loosely coupled systems that are resilient, manageable, and observable. Combined with robust automation, they allow engineers to make high-impact changes frequently and predictably with minimal toil.
All of the the steps in the machine learning lifecycle (from data exploration to model training and inference) can help you:
- Switch rapidly across different technologies
- Use a variety of available hardware platforms to speed up each step of developing an AI solution
- Scale up and scale out for training and inference
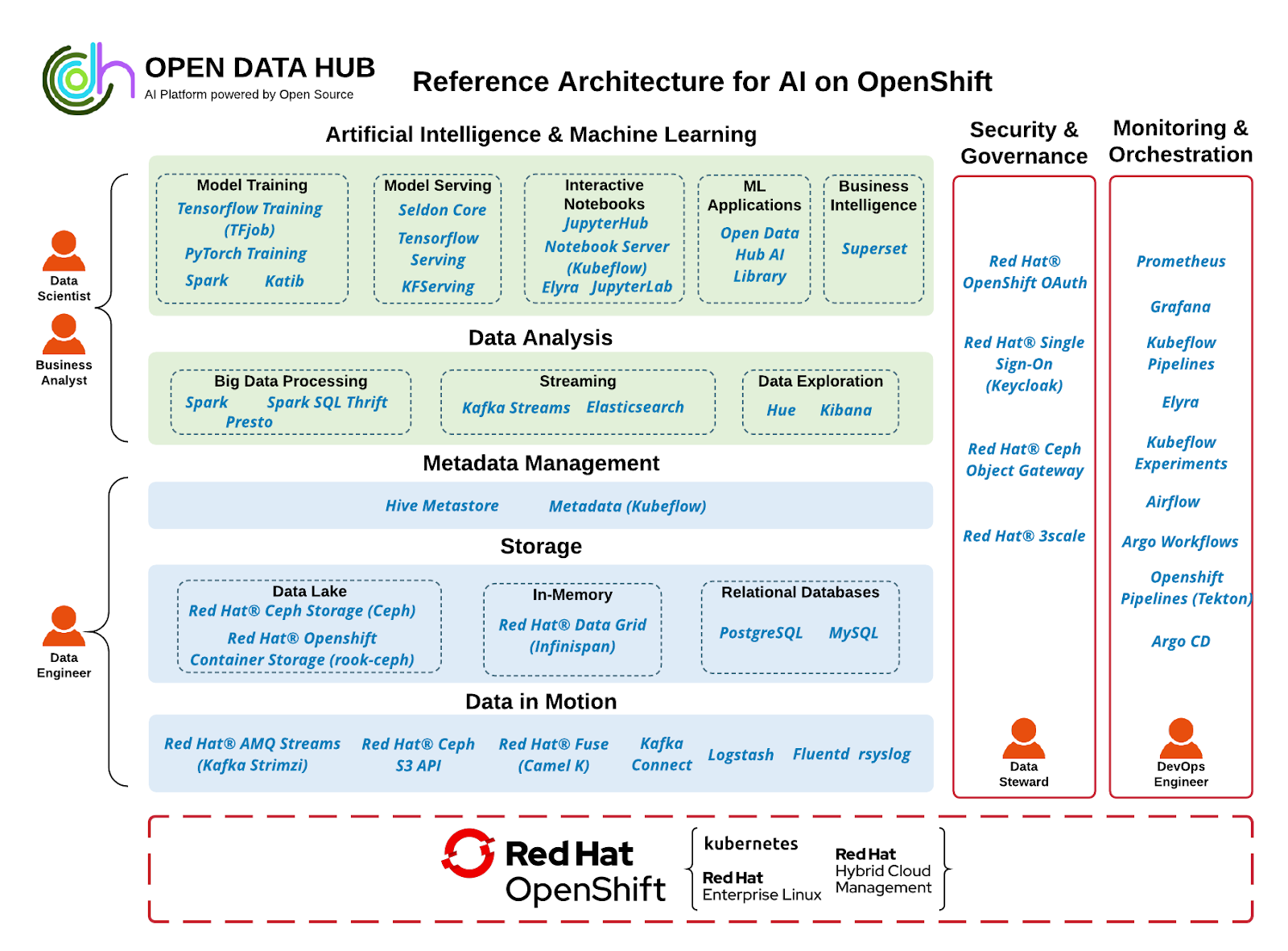
What is Open Data Hub?
While navigating cloud-native computing and artificial intelligence, we found that users need to combine the two technologies easily and in a way that supports their requirements to run heavy data science workloads on a lightweight, scalable infrastructure. Hence, the Open Data Hub project was born.
Open Data Hub is a collection of popular tools often used in machine learning and artificial intelligence. Projects like JupyterHub, Argo, Tekton, Superset, Kafka, and many others are included by default. Open Data Hub uses Kubeflow as its upstream and base for tooling. It allows users to leverage projects incubated and integrated within the Kubeflow community such as Katib, KF Serving, or KF Pipelines.
Install Open Data Hub
One of our goals was to provide easy installation and maintenance of the platform. Since it's built around cloud-native infrastructure that heavily uses the Operator design pattern, we decided to take the same route.
We collaborated with the Kubeflow machine learning project to help build a Kubeflow Operator to run the Kubeflow platform on Kubernetes. Since Open Data Hub shares most of the deployment processes with Kubeflow, we could directly adopt the Kubeflow Operator. Then, with slight modifications, we turned it into an Open Data Hub Operator and published it on OpenShift Operator Hub.
Simply put, you can install Open Data Hub with a few clicks directly from the OpenShift Console.
How Open Data Hub powers data science
Open Data Hub uses Project Thoth to integrate DevSecOps processes into data science. DevSecOps stands for development, security, and operations. It's an approach to culture, automation, and platform design that integrates security as a shared responsibility throughout the entire IT lifecycle.
Project Thoth aims to provide DevSecOps capabilities to all developers (including data scientists). It starts from selecting dependencies based on the developers' needs (such as performance and security) and phase of the project (for example, the latest), creating images with automated pipelines and bots, and finally, deploying applications (for example, machine learning model) using declarative approaches.
Thoth services can power Open Data Hub as a platform for data science in different ways:
- Pipelines: AICoE-CI pipelines can provide build capabilities to Open Data Hub to create optimized, secure images for you, depending on your requirements. AICoE CI is a GitHub App, and you can integrate it into GitHub projects. You just need to add a configuration file and trigger your builds. CI checks and deploys feedback for intelligent apps.
- Jupyter tools integration: Data scientists can spawn images from JupyterHub on Open Data Hub. These images are maintained by Thoth bots and built from AICoE-CI pipelines. These images contain Thoth integration for JupyterLab Notebooks, called jupyterlab-requirements. This library allows you to manage dependencies directly from your notebooks easily. It provides optimized and secure stacks and guarantees shareability and reproducibility. These concepts are very important if you want others to repeat your experiments, avoid issues due to dependency management, and allow traceability of packages (such as the source they are coming from).
When using pip install <package_name>, it is impossible to verify which software stack was used to run the notebook, and therefore another user cannot repeat the same experiment. Dependency management is one of the most important requirements for reproducibility. Having clearly stated dependencies allows portability of notebooks, so you can share them safely with others, reuse them in other projects, or simply reproduce them. If you want to know more about this issue in the data science domain, look at this article or this video.
- Bots: Kebechet is a SourceOps bot that automates updating your project's dependencies. Currently, it supports managing and updating Python projects based on pipenv files (
PipfileandPipfile.lock) orrequirements.txt/requirements.infiles (Kebechet is a replacement for pip-tools). It keeps repositories secure and up to date, helps automate releases, and reduces developers' workload so that they can focus on solving problems. - Predictable stacks images: These are secure, well-maintained, specialized application images recommended by Thoth. Data scientists can use them as an environment for running notebooks or in their AI pipelines without worrying too much about dependencies or builds. These images provide things such as:
Tying it all together with Meteor
If this makes sense as a foundation for your data science users, you're probably asking: How do I tie all of it together and evolve all these components into a coherent, integrated platform? We think the answer to that is Project Meteor.
Project Meteor is an Operator that provides an easy way to show, deploy, and measure the impact of various data science projects within Open Data Hub while using all the wisdom encoded in Project Thoth. Meteor's mission is to provide a single-click deployment of complex data science workloads. It features a curated list of Tekton pipelines at its core to ensure integrations.
[ Get started with container development by downloading 10 considerations for Kubernetes deployments. ]
Project Meteor consumes a data science repository URL and executes a set of pipelines against it, building multiple container images from the repository and providing other integration services. The aim is to simplify and reduce decisions about deployment and operations, necessary when a repository contributor (especially a data scientist contributor) would like to achieve a simple goal, such as deploying their repository as a JupyterLab instance runtime with all their dependencies included.
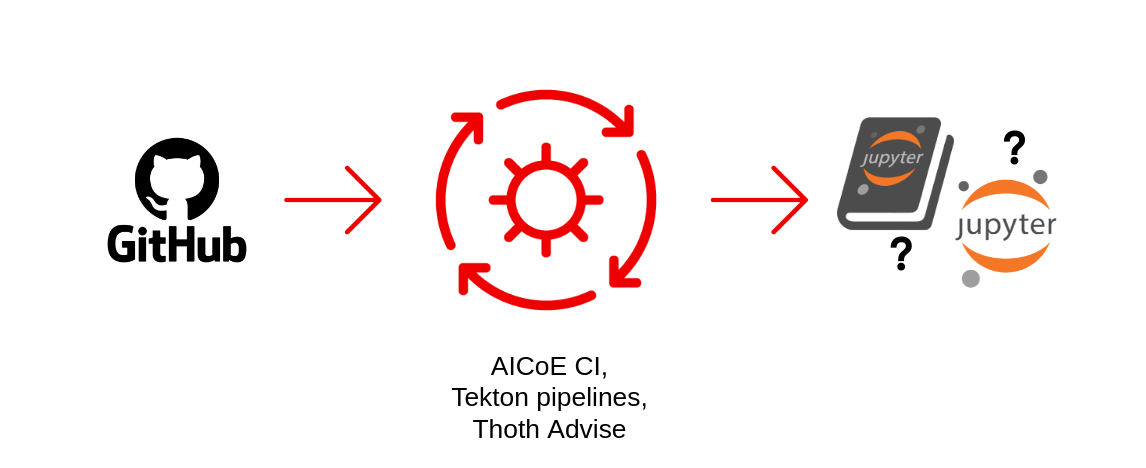
Currently, Project Meteor features pipelines for an Open Data Hub JupyterHub integration. It provides ready-to-use JupyterLab images connected to an Open Data Hub JupyterHub spawner and includes the most performant dependency stack based on Project Thoth recommendations. This pipeline ensures that any data science user who would like to start using the Open Data Hub JupyterHub deployment can do so in the most performant and efficient way while also bringing their data science repository content.
Another pipeline supported by Project Meteor deploys a static version of the repository rendered as a JupyterBook. This aims to provide easy access to the repository content, presumably an analysis of some kind, with rendered visuals structured, organized, and paginated. This deployment provides a snapshot of the repository, ready to be presented to stakeholders and other collaborators. It serves as a minimal-effort entry point into the data science world, allowing users to quickly ramp up on a given project, provide feedback, and even quickly switch over to the interactive variant in JupyterHub.
Project Meteor wants to simplify cloud-native development and deployment while maintaining transparency. It provides a single-click deployment, leveraging Project Thoth's know-how about dependencies, performance, and optimizations, and integrates tightly with Open Data Hub.
It also codifies operational knowledge acquired by Operate First, a new way to manage applications and infrastructure that bridges the gap between operations and site reliability engineering (which we'll write about in our upcoming companion article). Project Meteor is an opinionated, self-service platform and an entry point to efficient operations for data scientists.
Next steps
Building and operating in a cloud-native manner is not trivial. Our approach supports different personas in the AI lifecycle, facilitating and automating many tasks using Kubernetes Operators, pipelines, and AI services. Moreover, working openly with the community to identify issues and improve overall systems boosts productivity and reduces time to provide solutions and deploy AI applications safely.
In our follow-up article, we'll talk specifically about how we use Operate First to host cloud-native AI.
For more, please see our DevConf presentation, Cloud-native AI using OpenShift.
DevConf is a free, Red Hat-sponsored technology conference for community projects and professional contributors to free and open source technologies. Check out the conference schedule to find other presentations that interest you, and access the YouTube playlist to watch them on demand.
About the authors
Francesco is a senior data scientist and senior software engineer.
He's been with Red Hat for almost three years, and he contributes to several open source projects. He has a passion for AI, software and space, and open source. He previously worked at the European Space Agency (ESA) while pursuing his PhD, mixing AI and the space field.
Tom Coufal is a principal software engineer who has been working in open source his entire career.
Doing everything from quality assurance to development; backend to frontend and back; platform and monolithic legacy applications to cloud-native microservices, Tom has had the opportunity to experience many different areas of software engineering.
In his seven years at Red Hat, Tom has helped transform manual testing of customer subscriptions into a fully automated framework. He has co-maintained client libraries for various cloud providers. He helped to design and create an analytics platform foundation for Ansible. He has also worked on processing big data across Red Hat.
Tom has also spoken at various conferences including DevConf, Red Hat Summit, Red Hat Tech Exchange, and The Linux Foundation webinars.
He enjoys the Python, Ruby, and OpenShift/Kubernetes worlds. However, he likes spending his spare time in Typescript and Golang lands as well.
Vaclav is a member of Red Hat's AI services team, where he leads development of Red Hat OpenShift Data Science's AI/ML platform. He has been working with containers and container orchestration for many years.
More like this
Why single AI agents fail at scale: Building governed multi-agent networks
Avoid operational drift with Red Hat Lightspeed content templates for RHEL extended environments
Technically Speaking | Defining sovereign AI with open source
Technically Speaking | Inside open source AI strategy
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds