OpenShift brings together the core open source components of Linux, containers and Kubernetes. It adds additional capabilities such as a registry and developer tools and optimizes the software for enterprise use.
IBM Z offers on-demand compute with horizontal scalability that can grow to thousands of Linux guests and millions of containers, and vertical scalability that can non-disruptively grow databases without requiring any partitioning or sharding while maintaining response times and throughput.
OpenShift on IBM Z together takes advantage of the underlying enterprise capabilities of the IBM Z platform, including advanced security, vertical and horizontal scalability, and 99.999% availability.
Running Red Hat OpenShift on IBM Z also enables cloud native applications to easily integrate with existing data and applications running on these platforms, enabling latency to be reduced by avoiding network delays.
This blogpost will provide a deep dive into the OpenShift installation process on a IBM Z-series.
Prerequisites
To proceed with the installation some prerequisites need to be in place. Also note that this is a user-provisioned infrastructure (UPI) installation. The OpenShift nodes are using RHEL CoreOS and the storage is NFS-based persistent storage.
The minimum system requirements are:
- IBM z13/z13s or later
- 1 LPAR with z/VM Hypervisor 7.1 using 3 IFLs, +80GB RAM
- FICON or FCP attached disk storage
- OSA, RoCE, z/VM VSwitch networking
For the installation the following assumptions are made:
- The zVM guests have been already configured, and the SYSADMIN of the zVM has pre-configured and provided the credentials of each zVM guest
- The DASD devices to be used in each zVM guest have been identified
- The linux kernel parameters to boot the z/VM guests are understood
- The zVM network information is understood (nameserver, gateway, netmask, IP and MAC addresses)
- An account at https://cloud.redhat.com has been created to download the pull secret for the installer
- Infrastructure services
- Static IP address assignment
- DNS server
- Load balancers
- A helper server for installation (temporary)
- Internet connectivity
- Operating system
- RHEL CoreOS for control plane nodes, bootstrap and compute nodes
- Persistent Storage
- 100GB minimum for internal image registry
- NFSv4 server with >100GB disk storage
- Bootstrap and control plane nodes
- 4 vCPUs
- +16GB main memory
- 120GB disk storage
- Compute nodes
- 2 vCPUs
- +8GB main memory
- 120GB disk storage
The following diagram shows how a cluster looks with the minimum requirements:
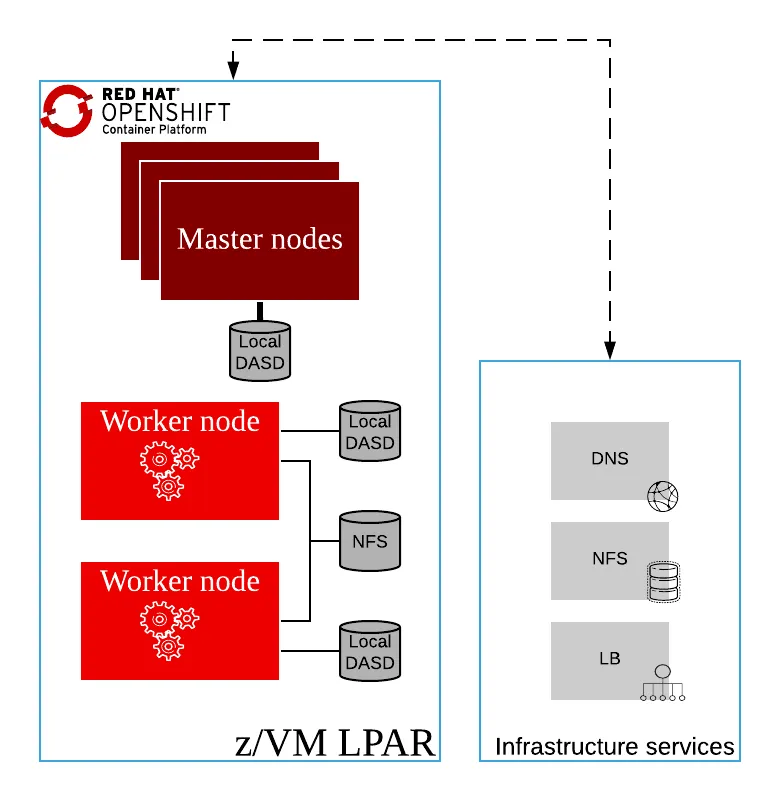 Figure 1
Figure 1
Preferred Systems Requirements for High-Availability
- 3 LPARS with z/VM 7.1 using 6 IFLs, +104GB RAM
The following diagram shows how a cluster looks with the preferred requirements:
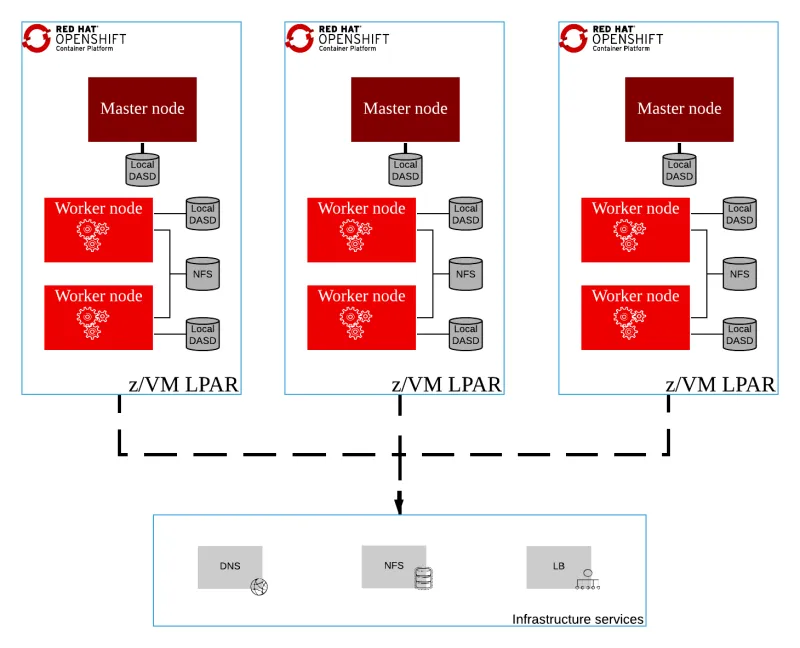
Figure 2
In the following table the differences between the minimum system requirements and the preferred ones can be compared:
|
Minimum system requirements |
Preferred system requirements |
|
Hardware capacity |
|
|
1 LPAR with 3 IFLs supporting SMT2 |
3 LPARs with 6 IFLs supporting SMT2 |
|
1 OSA and/or RoCE card |
1-2 OSA and/or RoCE card |
|
Operating System |
|
|
zVM 7.1 |
zVM 7.1 - 3 instances for HA purposes |
|
3 VMs for the control plane nodes |
3 VMs for the control plane nodes (one per instance) |
|
2 VMs for the compute nodes |
+6 VMs for the compute nodes (across instances) |
|
1 VM for the temporary bootstrap node |
1 VM for the temporary bootstrap node |
|
Disk storage |
|
|
FICON attached disk storage (DASDs) |
|
|
Minidisks, fullpack minidisks or dedicated DASDs |
|
|
FCP attached disk storage |
|
|
Network |
|
|
Single z/VM virtual NIC in layer 2 mode, one of: |
Single z/VM virtual NIC in layer 2 mode, one of: |
|
Direct-attached OSA or RoCE |
Direct-attached OSA or RoCE |
|
z/VM VSwitch |
z/VM VSwitch (using OSA link aggregation) |
|
Memory |
|
|
16GB for the control plane nodes |
+16GB for the control plane nodes |
|
8GB for the compute nodes |
+8GB for the compute nodes |
|
16GB for the bootstrap node |
16GB for the bootstrap node |
Table 1: Requirements
Refer to the following link for more information on performance and sizing: the scalability and performance best practices documentation
In this example a helper server is going to be used, running RHEL8.1 and providing infrastructure services. It is installed as a guest virtual machine on the same LPAR as the OCP nodes. For more information on how to install RHEL on IBM Z, refer to the official documentation. The following tools must be available on the helper server:
- s390utils-base-2
- firewalld
Software configuration for OCP
Existing infrastructure environments vary far too widely to make a recommendation on a load balancing solution in this blog post. Most IT installations will already have their own solutions for DNS and load balancing, and providing a configuration that will be applicable to any existing DNS service or load balancing infrastructure in the market is beyond the scope of this blog post. The DNS and Load Balancer configurations used in this blogpost are shown as a point from where to start with your own customization.
Important
The DNS/Load Balancing configuration shown is intended for simplicity of understanding. It does not provide the performance or redundancy to be suitable for a production deployment of OpenShift.
The software and system requirements are as follows:
- Infrastructure services
- Static IP address assignment
- DNS server
- Load balancers
- A helper server for installation (temporary)
- Internet connectivity
- Operating system
- RHEL CoreOS for control plane nodes, bootstrap and compute nodes
- Persistent Storage
- 100GB minimum for internal image registry
- NFSv4 server with >100GB disk storage
- Bootstrap and control plane nodes
- 4 vCPUs
- +16GB main memory
- 120GB disk storage
- Compute nodes
- 2 vCPUs
- +8GB main memory
- 120GB disk storage
For more information about the OCP cluster limits the recommended best practices documentation can be checked.
Network configuration
At the moment of writing this blogpost there are two options to configure the network in the zVMs:
- The first option is to use a single vNIC for the z/VM virtual machines, direct-attached OSA or RoCE to each guest virtual machine.
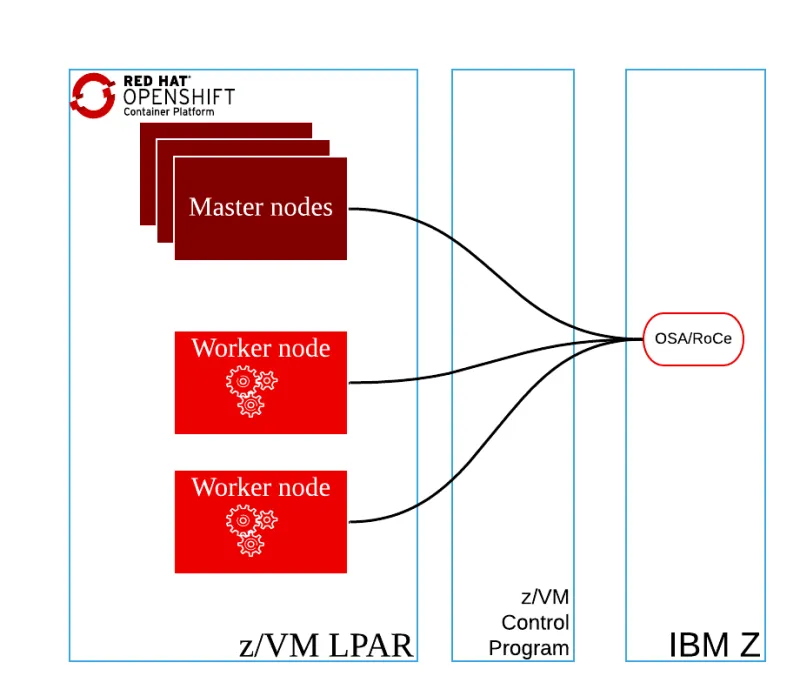 Figure 3
Figure 3 - The second option is to use a single vNIC for the z/VM virtual machines, z/VM VSwitch with OSA (optionally, using link aggregation)
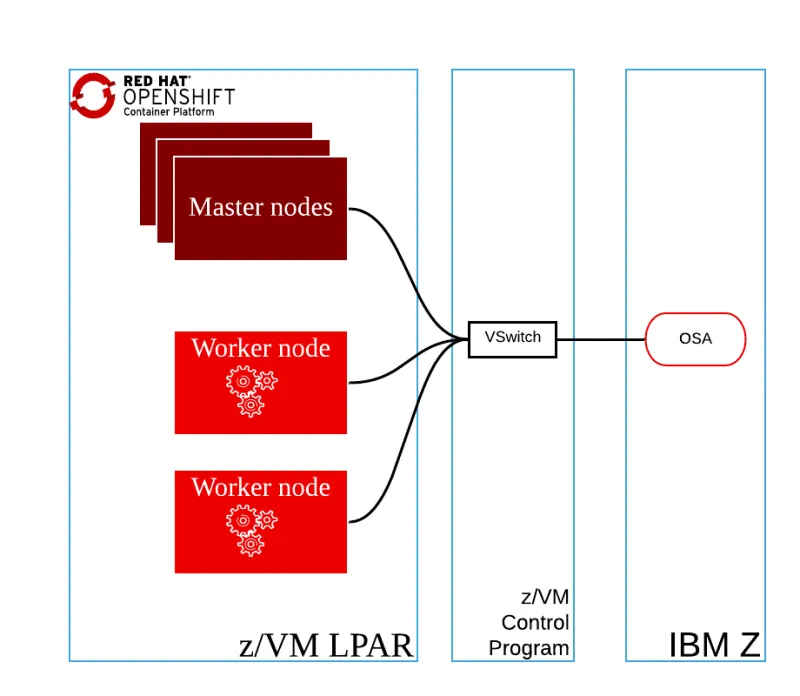 Figure 4
Figure 4
In both cases one vNIC is used for the two networks:
- External communication
- Internal communication - software-defined network for Kubernetes pod communication
The software configuration described in the example deployment of this blog post is compatible with either network option.
Storage options
For installing CoreOS on each node, disks must be configured for each zVM guest. Minidisks will be used as an example. Minidisks are z/VM virtual resources that represent smaller chunks on a DASD; Linux sees them as individual disks (DASDs). Other options available for consideration are HyperPAV for ECKD storage or DASDs/FCP devices in “pass-through” configuration if it is desired to have dedicated disks for each z/VM guest.
Some considerations need to be taken into account:
- The internal OpenShift cluster image registry requires persistent storage for the container images.
- Other use cases may take advantage of the shared storage such as a shared data pool for container instances (persistent containers storage), or applications or workloads which require shared storage.
- For the initial release of OCP on IBM Z-series, only NFS persistent storage is supported.
Example Deployment Scenario
To showcase the installation, one z/VM LPAR will contain guests including three OCP control plane nodes running RHEL CoreOS and two OCP compute nodes also running RHEL CoreOS. In this case the infrastructure services (DNS, load balancer, HTTP) are prepared on the helper node. In a real world scenario these services would be already running somewhere in the environment. Preparing existing infrastructure services may require coordination with the teams that manage these services.
Procedure
Infrastructure services
In this example we are assuming that there are no existing services to handle the DNS configuration, load balancing, or provide local HTTP downloads for the CoreOS files. Table x, shown below, provides the IP address configuration details for each node used in this example.
|
Node |
Key |
Value |
|
Helper/Bastion |
IP address |
192.168.0.11 |
|
Network |
Gateway |
192.168.0.10 |
|
Netmask |
255.255.255.0 |
|
|
CIDR |
192.168.0.0/24 |
|
|
Bootstrap |
IP address |
192.168.0.2 |
|
Control plane 0 |
IP address |
192.168.0.3 |
|
Control plane 1 |
IP address |
192.168.0.4 |
|
Control plane 2 |
IP address |
192.168.0.5 |
|
Compute 0 |
IP address |
192.168.0.6 |
|
Compute 1 |
IP address |
192.168.0.7 |
Table 2: Network data
DNS configuration
The User-provisioned DNS requirements for installing Red Hat OpenShift in the IBM Z are as follows:
|
Component |
Record |
Description |
Kubernetes API |
api.<cluster_name>.<base_domain> |
This DNS A/AAAA or CNAME record must point to the load balancer for the control plane machines. This record must be resolvable by both clients external to the cluster and from all the nodes within the cluster. |
|
api-int.<cluster_name>.<base_domain> |
This DNS A/AAAA or CNAME record must point to the load balancer for the control plane machines. This record must be resolvable from all the nodes within the cluster. The API server must be able to resolve the compute nodes by the host names that are recorded in Kubernetes. If it cannot resolve the node names, proxied API calls can fail, and you cannot retrieve logs from Pods. |
|
|
Routes |
*.apps.<cluster_name>.<base_domain> |
A wildcard DNS A/AAAA or CNAME record that points to the load balancer that targets the machines that run the Ingress router pods, which are the compute nodes by default. This record must be resolvable by both clients external to the cluster and from all the nodes within the cluster. |
etcd |
etcd-<index>.<cluster_name>.<base_domain> |
OpenShift Container Platform requires DNS A/AAAA records for each etcd instance to point to the control plane machines that host the instances. The etcd instances are differentiated by <index> values, which start with 0 and end with n-1, where n is the number of control plane machines in the cluster. The DNS record must resolve to an unicast IPv4 address for the control plane machine, and the records must be resolvable from all the nodes in the cluster. |
|
_etcd-server-ssl._tcp.<cluster_name>.<base_domain> |
For each control plane machine, OpenShift Container Platform also requires a SRV DNS record for etcd server on that machine with priority 0, weight 10 and port 2380. |
Table 3: DNS requirements
For more information check the OpenShift documentation: Table 2. Required DNS records
For this example the DNS service used will be bind: The Berkeley Internet Name Domain (BIND) DNS (Domain Name System) server. To install and start bind run the following commands:
# yum install bind-chroot
# systemctl start named-chroot
# systemctl enable named-chroot
The following configuration files have to be modified or created:
- The bind configuration /etc/named.conf
- The DNS subnet definition /var/named/test.example.com.zone
- The DNS subnet zone /var/named/0.168.192.in-addr.arpa.zone
The bind configuration should contain the following content based in the Table 2: Network data, special attention to the zones at the end of the file:
//
// named.conf
//
// Provided by Red Hat bind package to configure the ISC BIND named(8) DNS
// server as a caching only nameserver (as a localhost DNS resolver only).
//
// See /usr/share/doc/bind*/sample/ for example named configuration files.
//
acl internal_nets { 192.168.0.0; };
options {
listen-on port 53 { 127.0.0.1; 192.168.0.11;};
listen-on-v6 port 53 { none; };
directory "/var/named";
dump-file "/var/named/data/cache_dump.db";
statistics-file "/var/named/data/named_stats.txt";
memstatistics-file "/var/named/data/named_mem_stats.txt";
secroots-file "/var/named/data/named.secroots";
recursing-file "/var/named/data/named.recursing";
allow-query { localhost; internal_nets; };
recursion yes;
allow-recursion { localhost; internal_nets; };
forwarders { 8.8.8.8; };
dnssec-enable yes;
dnssec-validation no;
managed-keys-directory "/var/named/dynamic";
pid-file "/run/named/named.pid";
session-keyfile "/run/named/session.key";
/* https://fedoraproject.org/wiki/Changes/CryptoPolicy */
include "/etc/crypto-policies/back-ends/bind.config";
};
logging {
channel default_debug {
file "data/named.run";
severity dynamic;
};
};
zone "." IN {
type hint;
file "named.ca";
};
include "/etc/named.rfc1912.zones";
include "/etc/named.root.key";
zone "test.example.com" {
type master;
file "test.example.com.zone";
allow-query { any; };
allow-transfer { none; };
allow-update { none; };
};
zone "0.168.192.in-addr.arpa" {
type master;
file "0.168.192.in-addr.arpa.zone";
allow-query { any; };
allow-transfer { none; };
allow-update { none; };
};
For the DNS subnet definition the following DNS registries need to be configured in a new file called /var/named/test.example.com.zone, create the directory /var/named if it doesn’t exist.
$TTL 900
@ IN SOA bastion.test.example.com. hostmaster.test.example.com. (
2019062002 1D 1H 1W 3H
)
IN NS bastion.test.example.com.
bastion IN A 192.168.0.11
api IN A 192.168.0.11
api-int IN A 192.168.0.11
apps IN A 192.168.0.11
*.apps IN A 192.168.0.11
bootstrap-0 IN A 192.168.0.2
master-0 IN A 192.168.0.3
master-1 IN A 192.168.0.4
master-2 IN A 192.168.0.5
worker-0 IN A 192.168.0.6
worker-1 IN A 192.168.0.7
etcd-0 IN A 192.168.0.3
etcd-1 IN A 192.168.0.4
etcd-2 IN A 192.168.0.5
_etcd-server-ssl._tcp IN SRV 0 10 2380 etcd-0.test.example.com.
IN SRV 0 10 2380 etcd-1.test.example.com.
IN SRV 0 10 2380 etcd-2.test.example.com.
And for the DNS subnet zone the new file /var/named/0.168.192.in-addr.arpa.zone has to be created with the following content:
$TTL 900
@ IN SOA bastion.test.example.com hostmaster.test.example.com. (
2019062001 1D 1H 1W 3H
)
IN NS bastion.test.example.com.
154 IN PTR master-0.test.example.com.
155 IN PTR master-1.test.example.com.
156 IN PTR master-2.test.example.com.
157 IN PTR worker-0.test.example.com.
153 IN PTR worker-1.test.example.com.
153 IN PTR bootstrap-0.test.example.com.
If the network is handled by NetworkManager, the following configuration has to be changed, in the file /etc/NetworkManager/NetworkManager.conf the following parameter has to be added:
[main]
dns=none
And also the local resolution in the file /etc/resolv.conf should include the local resolver:
search test.example.com
nameserver 192.168.0.11
To finish this configuration the DNS service has to be added to the firewall in the public zone and the bind and firewall services may be rebooted:
# firewall-cmd --add-service=dns --zone=public --permanent
# systemctl restart named-chroot
# systemctl restart firewalld
LoadBalancer configuration
The requirements for the load balancer state that the following ports must be configured:
|
Port |
Machines |
Description |
|
6443 |
Bootstrap (temporary) and control plane. The bootstrap entry should be removed from the load balancer after the bootstrap machine initializes the cluster control plane. |
Kubernetes API server |
|
22623 |
Bootstrap (temporary) and control plane. The bootstrap entry should be removed from the load balancer after the bootstrap machine initializes the cluster control plane. |
Machine Config server |
|
443 |
The machines that run the Ingress router pods, (compute nodes by default) |
HTTPS traffic |
|
80 |
The machines that run the Ingress router pods (compute nodes by default) |
HTTP traffic |
Table 4. Load balancers
In this case, the software that is going to be used is haproxy:
# yum install haproxy python3-libsemanage
# systemctl start haproxy
# systemctl enable haproxy
The following is an example configuration of the file /etc/haproxy/haproxy.cfg for achieving the requirements shown in Table 3:
global
log 127.0.0.1 local2
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000
user haproxy
group haproxy
daemon
stats socket /var/lib/haproxy/stats
ssl-default-bind-ciphers PROFILE=SYSTEM
ssl-default-server-ciphers PROFILE=SYSTEM
defaults
mode http
log global
option httplog
option dontlognull
option http-server-close
option forwardfor except 127.0.0.0/8
option redispatch
retries 3
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout client 1m
timeout server 1m
timeout http-keep-alive 10s
timeout check 10s
maxconn 3000
frontend ocp4-kubernetes-api-server
mode tcp
option tcplog
bind api.test.example.com:6443
bind api-int.test.example.com:6443
default_backend ocp4-kubernetes-api-server
frontend ocp4-machine-config-server
mode tcp
option tcplog
bind api.test.example.com:22623
bind api-int.test.example.com:22623
default_backend ocp4-machine-config-server
frontend ocp4-router-http
mode tcp
option tcplog
bind apps.test.example.com:80
default_backend ocp4-router-http
frontend ocp4-router-https
mode tcp
option tcplog
bind apps.test.example.com:443
default_backend ocp4-router-https
backend ocp4-kubernetes-api-server
mode tcp
balance source
server boostrap-0 bootstrap-0.test.example.com:6443 check
server master-0 master-0.test.example.com:6443 check
server master-1 master-1.test.example.com:6443 check
server master-2 master-2.test.example.com:6443 check
backend ocp4-machine-config-server
mode tcp
balance source
server bootstrap-0 bootstrap-0.test.example.com:22623 check
server master-0 master-0.test.example.com:22623 check
server master-1 master-1.test.example.com:22623 check
server master-2 master-2.test.example.com:22623 check
backend ocp4-router-http
mode tcp
server worker-0 worker-0.test.example.com:80 check
server worker-1 worker-1.test.example.com:80 check
backend ocp4-router-https
mode tcp
server worker-0 worker-0.test.example.com:443 check
server worker-1 worker-1.test.example.com:443 check
The different ports shown in “Table 3. Load balancers” must be added to the firewall, in the public zone and the haproxy service may be rebooted together with the firewall service:
# firewall-cmd --add-service=http --zone=public --permanent
# firewall-cmd --add-service=https --zone=public --permanent
# firewall-cmd --add-port=6443/tcp --zone=public --permanent
# firewall-cmd --add-port=22623/tcp --zone=public --permanent
# systemctl restart haproxy
# systemctl restart firewalld
To finish this configuration, the following SELinux boolean has to be enabled for allowing HAproxy to connect to any port:
# setsebool -P haproxy_connect_any 1
Note: this SELinux configuration is not suitable for production because it allows the HAproxy process to be able to connect to any port, it’s more secure to enable individual ports instead.
RHCOS images and ignition configurations
Before installing the cluster on the IBM Z infrastructure that has been provisioned, RHCOS must be installed on each z/VM guest. An HTTP server is needed to host the RHCOS images and the ignition configurations. The Apache web server will be used as an example.
# yum install httpd
# systemctl start httpd
# systemctl enable httpd
Because port 80 is already reserved for OpenShift, Apache must be configured to listen on another port. We will use 8080 as an example:
# sed -i 's/Listen .*/Listen 8080/g' /etc/httpd/conf/httpd.conf
# systemctl restart httpd
Next, enable port 8080 in firewalld:
# firewall-cmd --add-port=8080/tcp --zone=public --permanent
# systemctl restart firewalld
Note
The mirrored RHEL CoreOS (RHCOS) images are not updated with every minor update to OpenShift Container Platform. Rather, the mirror generally contains the initial RHCOS images for each major release, and OpenShift applies updates to RHCOS during the install. To ensure compatibility between OpenShift and RHCOS, the major release version of the openshift installer must match the major release version of RHCOS.
Download the latest RHCOS images whose minor release versions are less than or equal to the version of the OpenShift installer you plan to use. At the time of writing this blogpost, the latest mirrored image of RHCOS for s390x is version 4.2.18.
Create a temporary directory to store the RHCOS files and the kernel PARAM files:
# mkdir /root/rhcos-bootfiles
# cd /root/rhcos-bootfiles
# wget
https://mirror.openshift.com/pub/openshift-v4/s390x/dependencies/rhcos/4.2/4.2.18/rhcos-4.2.18-s390x-installer-initramfs.img
# wget https://mirror.openshift.com/pub/openshift-v4/s390x/dependencies/rhcos/4.2/4.2.18/rhcos-4.2.18-s390x-installer-kernel
The raw image to be used with the DASD disks has to be available in the http server. A directory called ignition is created in the root path of the Apache HTTP server, and the dasd version of the RHCOS image is stored in the same directory. Note: if you have configured your environment with FCP disks, you should use the metal-zfcp image instead of metal-dasd.
# mkdir /var/www/html/ignition/
# cd /var/www/html/ignition/
# wget https://mirror.openshift.com/pub/openshift-v4/s390x/dependencies/rhcos/4.2/4.2.18/rhcos-4.2.18-s390x-metal-dasd.raw.gz
The kernel PARAM files will be created in the temporary directory (/root/rhcos-bootfiles). They contain the necessary boot configuration for RHCOS. For each node, an ignition file has to be created, in this example there are five nodes plus the bootstrap, that means that the following files have to be created:
- bootstrap-0.parm: contains the configuration data to boot the bootstrap
- master-0.parm: contains the configuration data to boot the control plane node 0
- master-1.parm: contains the configuration data to boot the control plane node 1
- master-2.parm: contains the configuration data to boot the control plane node 2
- worker-0.parm: contains the configuration data to boot the compute node 0
- worker-1.parm: contains the configuration data to boot the compute node 1
To understand the content of each PARAM file let’s take a look at bootstrap-0.parm:
rd.neednet=1
console=ttysclp0
coreos.inst=yes
coreos.inst.install_dev=dasda coreos.inst.image_url=http://192.168.0.11:8080/ignition/rhcos-4.2.18-s390x-metal-dasd.raw.gz
coreos.inst.ignition_url=http://bastion.test.example.com:8080/ignition/bootstrap.ign
ip=192.168.0.2::192.168.0.254:255.255.255.0:::none
nameserver=192.168.0.11
rd.znet=qeth,0.0.0600,0.0.0601,0.0.0602,layer2=1,portno=0
rd.dasd=0.0.0120
The parameters of that file are:
-
- rd.neednet: indicates that more than one ip option is used.
- console: contains the device that points to the console.
- coreos.inst: flag to indicate that is a CoreOS installation
- coreos.inst.install_dev: contains the storage device where to install CoreOS
- coreos.inst.image_url: points to our HTTP server where the metal-dasd image has been downloaded.
- coreos.inst.ignition_url: indicates the url where the ignition file for the bootstrap will be downloaded from.
- ip: contains the network information for the host installed
- nameserver: points to the DNS server on the helper node.
- rd.znet: has the network configuration:
NETTYPE,SUBCHANNELS,LAYER2,PORTNO
- NETTYPE: qeth, lcs, or ctc. The default is qeth.
- Choose lcs for:
- OSA-2 Ethernet/Token Ring
- OSA-Express Fast Ethernet in non-QDIO mode
- OSA-Express High Speed Token Ring in non-QDIO mode
- Gigabit Ethernet in non-QDIO mode
- Choose eth for:
- OSA-Express Fast Ethernet
- Gigabit Ethernet (including 1000Base-T)
- High Speed Token Ring
- HiperSockets
- ATM (running Ethernet LAN emulation)
- SUBCHANNELS:
- qeth: "read_device_bus_id,write_device_bus_id,data_device_bus_id"
- lcs or ctc: "read_device_bus_id,write_device_bus_id"
- LAYER2: can be 0 or 1
- Use 0 to operate an OSA or HiperSockets device in layer 3 mode (NETTYPE="qeth").
- Use 1 for layer 2 mode. For virtual network devices under z/VM this setting must match the definition of the GuestLAN or VSWITCH to which the device is coupled. To use network services that operate on layer 2 (the Data Link Layer or its MAC sublayer) such as DHCP, layer 2 mode is a good choice.
- PORTNO: It contains the port number of the OSA. It can be used either PORTNO="0" (to use port 0) or PORTNO="1" (to use port 1 of OSA features with two ports per CHPID) to avoid being prompted for the mode.
- rd.dasd: contains the storage device id to be used. If using FCP disks, rd.zfcp should be used instead.
For each node the following ignition_url may be changed:
|
File |
coreos.inst.ignition_url |
|
master-0.parm |
|
|
master-1.parm |
|
|
master-2.parm |
|
|
worker-0.parm |
|
|
worker-1.parm |
Table 5. PARM files
The coreos.inst.image_url is the same for each file. The ip address of each node should be configured per node in each PARAM file as specified in Table 2: Network data. The rd.znet and the rd.dasd are parameters are to be provided by your zVM administrator.
Creating the OpenShift cluster
To create the cluster, the following steps are executed:
- Download the openshift installer
- Download the openshift client
- Download the OCP4 pull_secret file
- Create the working dir
- Generate the install-config.yaml and prepare the ignition files
- Prepare the ssh keys
- Prepare the kubeconfig
- Wait for the bootstrap and nodes to the installation to complete
Download the OpenShift installer
The last version of the openshift-installer should be downloaded, extracted, and copied to a directory in the PATH of the root user. At the time of writing, the version of the openshift-installer is 4.2.20:
# wget https://mirror.openshift.com/pub/openshift-v4/s390x/clients/ocp/latest/openshift-install-linux-4.2.20.tar.gz
# tar zxvf openshift-install-linux-4.2.20.tar.gz
# cp openshift-install /usr/local/sbin/
# chmod 755 /usr/local/sbin/openshift-install
Download the OCP4 pull_secret file
To get the pull_secret you may visit the https://cloud.redhat.com webpage:
https://cloud.redhat.com/openshift/install/ibmz/user-provisioned
Login with your account and click in the button “Copy pull secret”:

Download the OpenShift client
# wget https://mirror.openshift.com/pub/openshift-v4/s390x/clients/ocp/latest/openshift-client-linux-4.2.20.tar.gz
# tar zxvf openshift-client-linux-4.2.20.tar.gz
# cp oc /usr/local/sbin/
# chmod 755 /usr/local/sbin/oc
Prepare the ssh keys
Generate the ssh keys. The key generation parameters may be tuned as desired.
# ssh-keygen -t rsa -b 2048 -N '' -C 'OCP-4-Admin' -f /root/.ssh/id_rsa
Create the working dir
The OpenShift workdir is going to be the directory where the openshift-installer stores the installation files. To create it execute the following command:
# mkdir /root/ocp4-workdir
# cd /root/ocp4-workdir
Create the install-config.yaml and prepare the ignition files
The install-config.yaml file has to be created in the workdir. The openshift installer consumes/deletes the install-config file during the installation, so it is recommended you backup a copy of the file at this point. Here is an example install-config for a cluster whose domain name is test.example.com:
apiVersion: v1
baseDomain: "example.com"
compute:
- hyperthreading: Enabled
name: worker
replicas: 0
controlPlane:
hyperthreading: Enabled
name: master
replicas: 3
metadata:
name: "test"
networking:
clusterNetworks:
- cidr: 10.128.0.0/14
hostPrefix: 23
networkType: OpenShiftSDN
serviceNetwork:
- 172.30.0.0/16
platform:
none: {}
pullSecret: ‘<paste here your pullSecret>’
sshKey: ‘<paste here the content of the pub key from /root/.ssh/id_rsa.pub>’
Use the openshift-installer to create the ignition configs:
# openshift-install --dir=/root/ocp4-workdir create ignition-configs
# ls /root/ocp4-workdir
auth bootstrap.ign master.ign metadata.json worker.ign
Now the ignition files can be copied to the HTTP server RootPath directory:
# cp /root/ocp4-workdir/*.ign /var/www/html/ignition
Prepare the kubeconfig
The kubeconfig has to be copied in the correct PATH:
# mkdir ~/.kube
# cp /root/ocp4-workdir/auth/kubeconfig /root/.kube/config
Wait for the bootstrap and nodes to the installation to complete
Now it’s time to load and activate the punch cards:
# load the virtual punch card devices
cio_ignore -r c-e
# activate the virtual punch card devices
chccwdev -e c-e
After the virtual punch card devices have been activated, the upload of the boot files to the zVM guests can take place. A tool called vmur (Work with z/VM spool file queues) can be used to upload the needed files, otherwise, check the RHEL installation guide - Using the z/VM Reader for upload alternatives.
The RHEL guest that is being used as a helper must be on the same LPAR as the zVM guests to run VMUR. If installing a cluster across multiple z/VM LPARS, a RHEL guest must exist on each LPAR to upload the boot files to the z/VM guests on that LPAR.
The vmur command is part of the s390utils-base-2 rpm and the parameters that we need are as follows:
vmur vmur_command [command_options] [command_args]
vmur pun -r -u ZVMUSER -N REMOTEFILE LOCALFILE
- Vmur_command pun: creates a file on the punch queue.
- -r: specifies that the punch or printer file is to be transferred to a reader.
- -u: specifies the z/VM user ID to whose reader the data is to be transferred.
- ZVMUSER: the z/VM user ID.
- -N: specifies a name and, optionally, a type for the z/VM spool file to be created by the punch or print function.
- REMOTEFILE: the name of the file once punched
- LOCALFILE: the name of the local file to punch
The order of punching the kernel.img, generic.prm, and initrd.img is very important. The three files must be punched in order on each zVM guest. You may want to check the ipl-boot-rhcos-on-zvm point in the upstream OpenShift GitHub documentation. For example:
# cd /root/rhcos-bootfiles
# echo “configuring bootstrap node”
# vmur pun -r -u zvmuser1 -N kernel.img rhcos-4.2.18-s390x-installer-kernel
# vmur pun -r -u zvmuser1 -N generic.prm bootstrap-0.parm
# vmur pun -r -u zvmuser1 -N initrd.img rhcos-4.2.18-s390x-installer-initramfs.img
# echo “configuring control plane node 0”
# vmur pun -r -u zvmuser2 -N kernel.img rhcos-4.2.18-s390x-installer-kernel
# vmur pun -r -u zvmuser2 -N generic.prm master-0.parm
# vmur pun -r -u zvmuser2 -N initrd.img rhcos-4.2.18-s390x-installer-initramfs.img
# echo “configuring control plane node 1”
# vmur pun -r -u zvmuser3 -N kernel.img rhcos-4.2.18-s390x-installer-kernel
# vmur pun -r -u zvmuser3 -N generic.prm master-1.parm
# vmur pun -r -u zvmuser3 -N initrd.img rhcos-4.2.18-s390x-installer-initramfs.img
# echo “configuring control plane node 2”
# vmur pun -r -u zvmuser4 -N kernel.img rhcos-4.2.18-s390x-installer-kernel
# vmur pun -r -u zvmuser4 -N generic.prm master-2.parm
# vmur pun -r -u zvmuser4 -N initrd.img rhcos-4.2.18-s390x-installer-initramfs.img
# echo “configuring compute node 0”
# vmur pun -r -u zvmuser5 -N kernel.img rhcos-4.2.18-s390x-installer-kernel
# vmur pun -r -u zvmuser5 -N generic.prm worker-0.parm
# vmur pun -r -u zvmuser5 -N initrd.img rhcos-4.2.18-s390x-installer-initramfs.img
# echo “configuring compute node 1”
# vmur pun -r -u zvmuser6 -N kernel.img rhcos-4.2.18-s390x-installer-kernel
# vmur pun -r -u zvmuser6 -N generic.prm worker-1.parm
# vmur pun -r -u zvmuser6 -N initrd.img rhcos-4.2.18-s390x-installer-initramfs.img
After running the commands it can be verified in each guest that the files have been uploaded. Using a 3270 console, connect to each guest:
Login with the zVM guest credentials and run the following command:
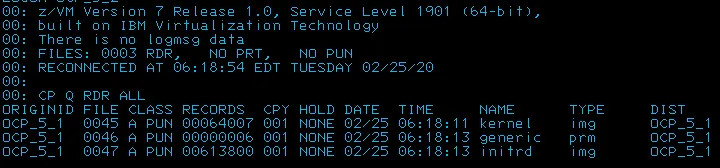
CP Q RDR ALL
It may show the reader files loaded by the vmur command (kernel, generic, initrd):
Otherwise it will say NO RDR FILES and it means that something went wrong and the files were not uploaded, you may upload the files to that zVM guest again with the vmur command.

On the Mainframe, to boot or reboot an LPAR or a zVM guest is called to IPL (initial program load). The IPL command needs to know from what device it has to boot while rebooting. The second parameter (00c) indicates the device from where to boot the guest, which in this case is the device ID of the punch card reader of each guest. Additionally, before closing the console we have to be sure that the command “cp set run on” is executed, otherwise if we close the console the VM would be powered off. To disconnect, the command “cp disc” has to be executed. These commands must be executed on each node, bootstrap, control plane, and computes.
cp ipl 00c
cp set run on
cp disc
Once each guest is booted, the OpenShift installation will begin automatically. To monitor the progress, you can execute the openshift-installer with the ’wait-for bootstrap-complete’ parameters as shown in the following example. The command succeeds when it notices the ‘bootstrap-complete’ event from the Kubernetes APIServer. This event is generated by the bootstrap machine after the Kubernetes APIServer has been bootstrapped on the control plane machines:
$ openshift-install --dir ~/ocp4-workdir wait-for bootstrap-complete
INFO Waiting up to 30m0s for the Kubernetes API at https://api.test.example.com:6443...
INFO API v1.14.6+cd3a7d0 up
INFO Waiting up to 30m0s for bootstrapping to complete...
INFO It is now safe to remove the bootstrap resources
Once the bootstrap phase has completed, the bootstrap machine can be removed from the load balancer.
As this cluster is a non-production one, to configure the storage for the image registry Operator, the image registry can initially be set to an empty directory as temporary storage. Note that when using emptyDir as the image registry backing storage, all images are lost if the registry is restarted. The image registry operator must appear in the list of cluster operators before this command is run, otherwise it will fail.
$ oc patch configs.imageregistry.operator.openshift.io cluster --type merge --patch '{"spec":{"storage":{"emptyDir":{}}}}'
Later in the deployment, the registry storage will be patched to use NFS.
To proceed monitoring the installation phase, the following command can be executed to follow the installation:
$ openshift-install --dir ~/ocp4-workdir wait-for install-complete
INFO Waiting up to 30m0s for the cluster at https://api.test.example.com:6443 to initialize…
INFO Install complete!
INFO To access the cluster as the system:admin user when using 'oc', run 'export KUBECONFIG=/root/ocp4-workdir/auth/kubeconfig'
INFO Access the OpenShift web-console here: https://console-openshift-console.apps.test.example.com
INFO Login to the console with user: kubeadmin, password: FmS4U-2VV9N-x6vZP-bNz6r
You can also follow the bootstrap process details with oc commands. It is also possible to ssh to the bootstrap node and check the journal output of the bootkube service:
$ ssh core@192.168.0.2
$ journal -b -f -u bootkube.service
It’s important to check the pending certificate signing requests (CSRs) and ensure that the server request with Pending are Approved for each machine that has been added to the cluster:
$ oc get csr -ojson | jq -r '.items[] | select(.status == {} ) | .metadata.name' | xargs oc adm certificate approve
To configure the registry storage using a NFS resource in the helper node, the following steps need to be executed:
- Install the required packages and enable the services in the firewall:
# yum install nfs-utils
# systemctl enable nfs-server
# systemctl start nfs-server
# firewall-cmd --permanent --add-service=nfs
# firewall-cmd --permanent --add-service=rpc-bind
# firewall-cmd --permanent --add-service=mountd
# firewall-cmd --reload
- Prepare the NFS directory, ensure it has enough disk capacity (100Gi in this example):
# mkdir /nfs
- Add the cluster nodes with the nfs directory:
# vim /etc/exports
/nfs 192.168.0.11(rw)
/nfs 192.168.0.3(rw)
/nfs 192.168.0.4(rw)
/nfs 192.168.0.5(rw)
/nfs 192.168.0.6(rw)
/nfs 192.168.0.7(rw)
- Check if it works from the helper:
# showmount -e 192.168.0.11
- Create the PV and the PVC for use with the registry:
# cat registry_nfs_pv.yml
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv0001
spec:
capacity:
storage: 100Gi
accessModes:
- ReadWriteOnce
nfs:
path: /nfs
server: 192.168.0.11
persistentVolumeReclaimPolicy: Retain
# oc apply -f registry_nfs_pv.yml -n openshift-image-registry
# cat registry_nfs_pvc.yml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: nfs-claim1
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 100Gi
# oc apply -f registry_nfs_pvc.yml -n openshift-image-registry
- Configure the registry to use the PVC nfs-claim1
# oc edit configs.imageregistry.operator.openshift.io
...
storage:
pvc:
claim: nfs-claim1
Once the cluster is up and running take into account that your control plane nodes are schedulable and they can host application containers, if you want to avoid that the following command can be used, it is documented in the OpenShift GitHub:
$ oc patch schedulers.config.openshift.io/cluster --type merge --patch '{"spec":{"mastersSchedulable": false}}'
After finishing the installation you may want to check the documentation to learn the basics about how to login in OpenShift from the console, approving the CSRs of the machines, how to configure the storage for the registry or how to complete the installation on user-provisioned infrastructure.
Conclusions
In this article a Red Hat OpenShift cluster has been deployed in 5 z/VM guests running in a Mainframe. Each environment has a different setup, some requirements have to be met and the collaboration of other Mainframe teams (like networking, storage or virtualization) would be necessary to get the cluster up and running in the Mainframe. Also, the configuration of some external services would be needed, if your IT environment already has them running you don’t need to create new ones. This blogpost showed how to create those services as an example but you can configure your corporate DNS server to meet OpenShift requirements and also you can use your existing load balancer like F5 or HAProxy to handle the load of the cluster.
References
https://docs.openshift.com/container-platform/4.2/installing/installing_ibm_z/installing-ibm-z.html
https://blog.openshift.com/deploying-a-upi-environment-for-openshift-4-1-on-vms-and-bare-metal/
About the author

More like this
Looking ahead to 2026: Red Hat’s view across the hybrid cloud
Red Hat to acquire Chatterbox Labs: Frequently Asked Questions
Crack the Cloud_Open | Command Line Heroes
Edge computing covered and diced | Technically Speaking
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds