By Sayandeb Saha, Director, Product Management
The Container-Native Storage (CNS) offering for OpenShift Container Platform from Red Hat has seen wide customer adoption in the past year or so. Customers are deploying it in a wide variety of environments that include bare metal, virtualized, and private and public clouds. It mimics the diverse spread of environments in which OpenShift itself gets deployed—which is also CNS’s key strength (i.e., being able to back OpenShift wherever it runs—see the following graphic).
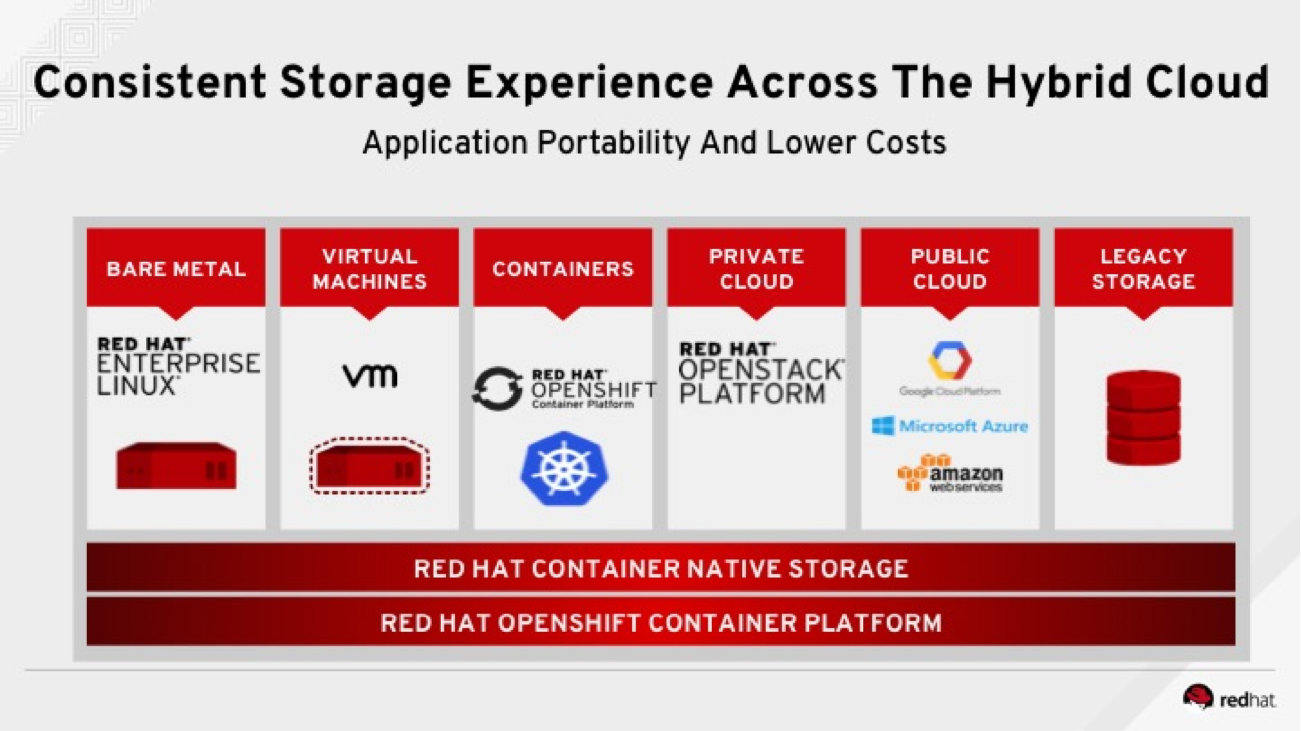
During the past of year of customer adoption of CNS, we've observed some key trends that are unique for OpenShift/Kubernetes storage and that we’ll highlight in a series of blogs. This blog series will also include business and technical solutions that have worked for our customers.
In this blog post, we examine a trend where customers have adopted CNS as a storage management fabric that sits in between the OpenShift Container Platform and their classic storage gear. This particular adoption pattern continues to have a really high uptake, and there are sound business and technical reasons for doing this, which we'll explore here.
First the Solution (The What): We've seen a lot of customers deploying CNS to serve out storage from their existing storage arrays/SANs and other traditional storage, as illustrated in the following graphic. In this scenario, block devices from existing storage arrays are served out with our CNS software running in VMs or containers/pods to OpenShift. In this case, the storage for the VMs that runs OpenShift is still served by the arrays.
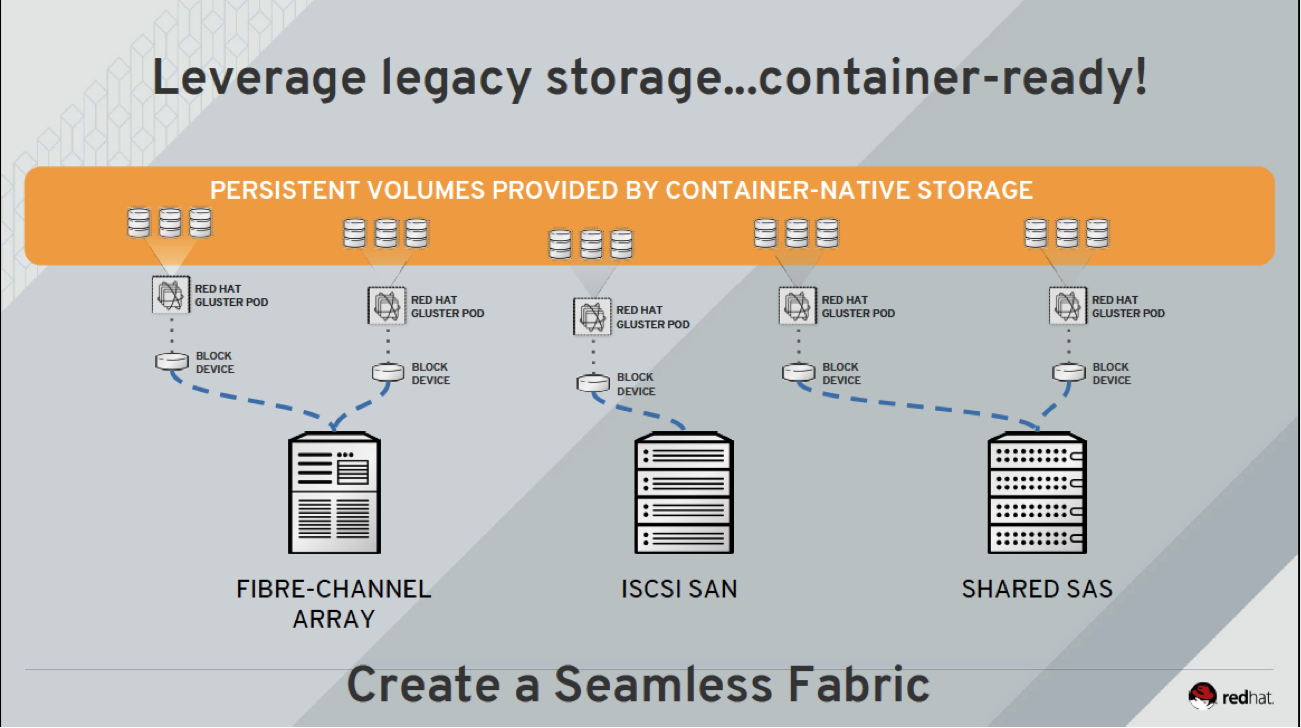
Now the Why: Initially, it seemed backward as to why customers would be doing this; after all, software-defined storage solutions like CNS are meant to run on x86 bare metal (on premise) or in the public cloud, but further investigation revealed some interesting discoveries.
While OpenShift users and ops teams consume infrastructure, they typically do not manage infrastructure. In on-premise environments, OpenShift ops teams are highly dependent on other infrastructure teams for virtualization, storage, and operating systems for the infrastructure on which they run OpenShift. Similarly, in public clouds they consume the native compute and storage infrastructure available in these clouds.
As a consequence, they are highly dependent on storage infrastructure that is already in place. Typically, it's very difficult to justify a storage server purchase when storage has been already procured a year or more ago from a traditional storage vendor for a new use case (OpenShift storage in this case). The issue is that this traditional storage was not designed for nor intended to be used with containers and the budget for storage has mostly been spent. This has driven the OpenShift operations teams to adopt CNS effectively as a storage management fabric that sits between their OpenShift Container Platform deployment and their existing storage array. The inherent flexibility of Red Hat Gluster Storage in this case is the form of CNS being leveraged, which enables it to aggregate and pool block devices that are attached to a VM and serve that out to OpenShift workloads. OpenShift operations teams can now have the best of both worlds. They can repurpose their existing storage array that is already in place/on premise but actually consume CNS which operates as a management fabric offering the latest and greatest in terms of feature, functionality, and manageability with a deep integration with the OpenShift platform.
In addition to business reasons, there are also various technical reasons that these OpenShift operations teams are adopting CNS. These include, but are not limited to:
- Lack of deep integration of their existing storage arrays with OpenShift Container Platform
- Even if their traditional storage array has rudimentary integration with OpenShift, very likely it has limited feature support, which renders it unusable with many OpenShift workloads (like lack of dynamic provisioning)
- The roadmap of their storage arrays vendor may not match their current (or future) OpenShift/Kubernetes storage feature support needs, like lack of availability of a Persistent Volume (PV) resize feature
- Needing a fully featured OpenShift Storage solution for OpenShift workloads as well as the OpenShift infrastructure itself. Many existing storage platforms can support one or the other, but not both. For instance, a storage array serving out Fiber Channels LUNs (plain block storage) can’t back an OpenShift registry as one needs shared storage access for it usually provided by a file or object storage back end.
- They seek a consistent storage consumption and management experience across hybrid and multiple clouds. Once they learn to implement and manage CNS from Red Hat in one environment, it’s repeatable in all other environments. They can’t use their storage array in the public cloud.
Using CNS from Red Hat is a win for OpenShift ops teams. They can get started with a state-of-the-art storage back end for OpenShift apps and infrastructure without needing to acquire new infrastructure for OpenShift Storage right away. They have the option to move to x86-based storage servers during the following budget cycle as they grow their OpenShift footprint and onboard more apps and customers to it. The experience with CNS serves them well if they choose to implement OpenShift and CNS in other environments like AWS, Azure, and Google Cloud.
Want to learn more?
For hands-on experience combining OpenShift and CNS, check out our test drive, a free, in-browser lab experience that walks you through using both.
About the author

More like this
The new reality of supply chain trust: Why platform-native security is non-negotiable
Context-aware advisor recommendations in Red Hat Lightspeed
Collaboration In Product Security | Compiler
Keeping Track Of Vulnerabilities With CVEs | Compiler
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds