
Republished from the original blog post by Matthew Demyttenaere on the CoScale Container Monitoring blog
OpenShift provides a basic monitoring layer to watch the health and resource usage of your containers, but you may have a need for more detailed application performance metrics. Like with all container platforms, the challenge is how you can provide performance visibility across the entire stack without overloading your containers with intrusive monitoring agents or without manual labor to push metrics to a centralized service. Ideally, you would like to have one agent that automatically watches all containers running on the host, and scales out its monitoring as needed. And you would also like that one agent to look inside your containers and talk to your orchestrator to understand service relationships.
Introducing CoScale, a Red Hat Certified Technology Partner for monitoring OpenShift. CoScale integrates with Red Hat OpenShift to gather OpenShift-specific metrics and events. Together with Docker, Kubernetes, and in-container monitoring capabilities, CoScale can provide a detailed view into the inner workings of OpenShift, the containers managed, and the services inside the containers.
In this post, we'll go into the details of how to set up CoScale specifically for monitoring OpenShift.
Creating a Monitoring Agent
To start monitoring your OpenShift cluster with CoScale, you first have to add an agent to it. Our agent runs as a DaemonSet with one containerized agent per node in your cluster. Starting the agent is as simple as copy and pasting the YAML configuration, which is automatically generated in the CoScale UI when you select to install CoScale on OpenShift. Prior to this, you will need to set up the Cocale service account with the correct administrative and security permissions. This is documented as part of our install process. Here is an example configuration of the agent:
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
labels:
name: coscale-agent
name: coscale-agent
spec:
template:
metadata:
labels:
name: coscale-agent
spec:
serviceAccount: coscale
hostNetwork: true
containers:
- image: coscale/coscale-agent
imagePullPolicy: Always
name: coscale-agent
securityContext:
privileged: true
env:
- name: APP_ID
value: "01234567-1234-5678-9876-123456789101"
- name: ACCESS_TOKEN
value: "01234567-1234-5678-9876-123456789101"
- name: TEMPLATE_ID
value: "12"
volumeMounts:
- name: dockersocket
mountPath: /var/run/docker.sock
- name: hostroot
mountPath: /host
readOnly: true
volumes:
- hostPath:
path: /var/run/docker.sock
name: dockersocket
- hostPath:
path: /
name: hostroot
EOF
Once you execute this command on one of the master nodes of your Kubernetes cluster, the agent will automatically run on each node in your cluster and a new agent will automatically be started on each newly added node. That’s it! No additional steps are required. The agent is installed and it will start gathering metrics about your the OpenShift cluster. After a couple of minutes, new dashboards will appear in your CoScale application. This is one of the strong points of CoScale: You don’t have to create dashboards manually, but default dashboards are automatically created for you, depending on the technologies recognized.
OpenShift Dashboards
Let’s show off these new dashboards that have automatically been created for you. Specifically, we are interested in the OpenShift dashboards, as they show you the underlying metrics for OpenShift. CoScale provides you information on a server-centric and service-centric level, meaning you can filter to see the containers running on a node in your cluster or you can filter on a Replica Set/Service/Daemon Set/Stateful Set level.
The first dashboard that you will see is the Openshift Cluster Overview. As the name implies, this dashboard gives you a broad overview of the entire OpenShift cluster. This is not a standalone dashboard with isolated information, but it is an interactive dashboard with clickable widgets. Clicking on specific parts of the widgets will allow you to drill down and view more detailed information. This is a very powerful workflow, allowing you to start from a high-level overview and then drilling in as needed.

One of those detailed dashboards is the Replica Sets Overview. Within this dashboard you can see an overview of the important events for your replicas. In the example below, you can clearly see one important event, where one of the Replica Sets in your cluster has fewer replicas than you specified (desired vs. actual pods). When such important events occur, we allow you to click on the event to drill down and see detailed information about what is causing the missing pods.
Another interesting visualization on this dashboard is the Container topology widget, which shows you clearly how many Pods are running in each of the replica sets on your cluster. We also allow you to filter by namespace so you only see the replication controllers that are relevant to you. If anything starts to pique your interest here, you can drill down for more detailed information. For example, you can click on an individual container to see more details about its resource usage, or click on the green circle of the replica set for an aggregated view for all containers of a service.
To get a more detailed view of a service you can also click on the name inside the Replication controller overview widget. This will bring you to another dashboard containing metrics specific to the image that you have selected. Below you can see an example of this.
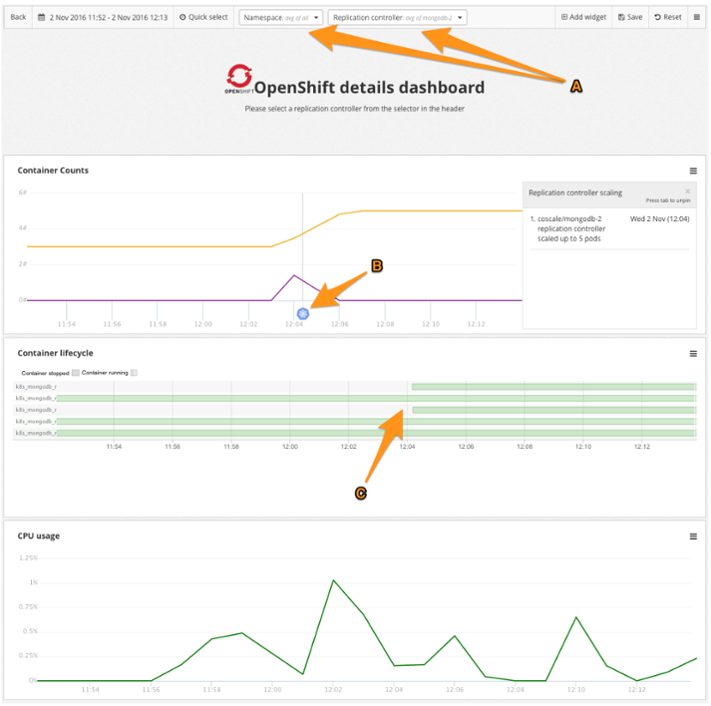
There are some special things to note here:
- The CoScale application has automatically selected the right replication controller and namespace for the service that was selected on the previous dashboard. It is always possible to change these simply by clicking one of the two dropdowns.
- The CoScale event system allows you to view changes in our environment. In this case, you can see that at a certain time the number of pods was scaled from 3 to 5 and this is clearly visible in the "Container Counts" widget.
- CoScale automatically keeps track of the containers running for a certain service, including start time, stop time, image name, tag, and exit code. You can see two new containers starting around the same time as the scale up.
We also have a CPU graph that shows you the CPU usage for this container group. These metrics come from the underlying Kubernetes service that manages the containers for Kubernetes.
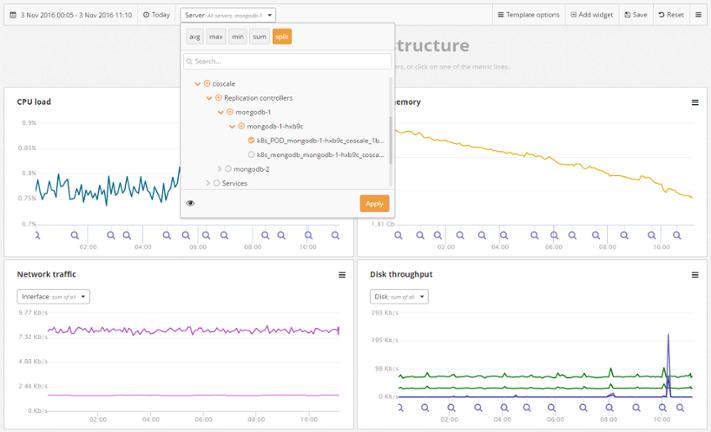
Besides CPU, CoScale also gathers storage, memory, network, and filesystem usage metrics.
It is also possible to see this information from a server level, all the way down to a single container. Which permits you to quickly identify services or containers that are not performing as expected.
To manage all the metrics coming from your containers, CoScale also provides automatic anomaly detection on all incoming metrics. This provides alerts on your container metrics without the need to monitor them all with static alerts or by having to constantly look at dashboards. This is especially challenging in these dynamic container environments. As a result, you can detect issues more proactively and solve them faster. In the example below, we show an anomaly where a specific container started using more CPU resources as usual.

What is Going On Inside Your Containers?
Up till now, we have just discussed the metrics and events coming from OpenShift and your containers. To go even deeper, you can also set up the CoScale in-container monitoring service to see what is happening inside the containers. With the agent plugins, you can gather application metrics from your web services (NGINX, Apache, Tomcat, etc.), your databases (MySQL, PostgreSQL, Redis, ElasticSearch, etc.) and many more. To start gathering these detailed metrics, check out previous blog posts on the CoScale blog on in-container monitoring and monitoring based on Docker labels. We also support Prometheus endpoints for monitoring your images.
Conclusion
CoScale’s OpenShift monitoring capabilities allow you to get detailed performance and application insights from a Red Hat OpenShift environment. The easy-to-install agent via DaemonSet auto scales together with your environment. Our automatically created dashboards let you drill into any aspect of your cluster, individual containers, or services, to monitor your entire environment. On top of that, our anomaly detection will automatically alert you when performance issues occur.
Do you want to know more? Then check out our OpenShift Commons webinar recording on Proactive Performance Management of OpenShift.
About the author

Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges

Original shows
Entertaining stories from the makers and leaders in enterprise tech
Products
- Red Hat Enterprise Linux
- Red Hat OpenShift
- Red Hat Ansible Automation Platform
- Cloud services
- See all products
Tools
- Training and certification
- My account
- Customer support
- Developer resources
- Find a partner
- Red Hat Ecosystem Catalog
- Red Hat value calculator
- Documentation
Try, buy, & sell
Communicate
About Red Hat
We’re the world’s leading provider of enterprise open source solutions—including Linux, cloud, container, and Kubernetes. We deliver hardened solutions that make it easier for enterprises to work across platforms and environments, from the core datacenter to the network edge.
Select a language
Red Hat legal and privacy links
- About Red Hat
- Jobs
- Events
- Locations
- Contact Red Hat
- Red Hat Blog
- Diversity, equity, and inclusion
- Cool Stuff Store
- Red Hat Summit