In part one of the series, we discussed how the Red Hat OpenShift Scale-CI evolved. In part two of the series, we looked at the deep dive and various components of Scale-CI. In this post, we will look at the highlights of how we used OpenShift Scale-CI to test and push the limits of OpenShift 4.1 which is the first OpenShift 4.x release and OpenShift 4.2 at scale.
We typically use hardware resources from the scale lab, a datacenter built and managed by Red Hat’s Performance and Scale team with the goal to provide compute resources on demand to various teams across Red Hat to solve problems related to Performance and Scalability. We install OpenStack on the bare metal machines to manage the resources and then install OpenShift on the virtual machines. In OpenShift 3.x, the installer doesn't take care of provisioning which means that we need to build wrapper scripts to create virtual machines for installing and scaling up OpenShift whereas the OpenShift 4.x IPI (Installer Provisioned Infrastructure) based installer takes care of provisioning and scaling up the cluster to higher node counts literally takes minutes versus hours. Redhat Enterprise Linux CoreOS is the default base operating system for OpenShift 4.x, It is immutable which means that configurations and packages can’t be changed or installed on the host, everything needs to run as a container. The cluster has full control over the nodes, this will avoid configuration drifts leading to easier upgrades and achieves repeatability and auditability. The following diagram shows the fully automated day 1 and day 2 operations:
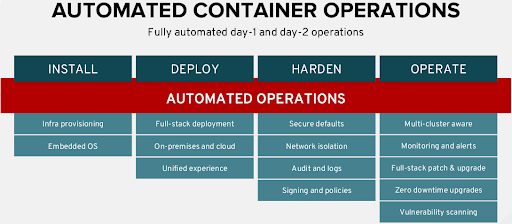
A single blog post won't be sufficient to elaborate on the amazing features and enhancements including the operators, you can refer to the 4.1 release notes and 4.2 release notes to know about all the features.
Let's jump straight into the OpenShift 4.1 and 4.2 scale test run highlights. We picked AWS and GCP as the cloud platforms to host OpenShift 4.1 and 4.2 clusters respectively. AWS is the only supported provider ( Installer Provisioned Infrastructure ) for the OpenShift 4.1 release while GCP, Azure and Red Hat OpenStack Platform are also supported in OpenShift 4.2. Here is the cluster configuration:
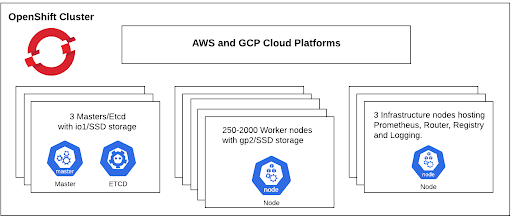
The 4.1 and 4.2 clusters consisted of 3 Masters/Etcd with io1 and SSD storage in the case of AWS and GCP respectively, etcd is i/o intensive especially when the cluster consists of large number of nodes and objects. We create infrastructure nodes using custom machinesets as part of day 2 operation to host prometheus, router, registry and logging instead of using bigger worker nodes and setting the limits on the deployments for the infrastructure components to be scheduled on nodes with the available resources.
We ran a bunch of scale tests including:
- Kubelet density focused test which spawns maximum pods across the worker nodes which is 250 ( current cluster limits for OpenShift 4.1 and 4.2 ).
- Control plane density focused tests which creates a bunch of projects with secrets, configmaps, routes, builds, deployments e.t.c across the cluster to stress the apiserver, etcd and controller on masters/etcd nodes.
- HTTP/Router scale test, a data-plane workload generator that runs http requests through through HAProxy into deployed pods.
- Cluster Limits, we ran a bunch of tests to validate and push the limits for the OpenShift 4.1 and 4.2 releases. The findings have been documented as part of the Scalability and Performance guide to help users/customers plan their environment according to the object limits. The following table shows the cluster limits for various OpenShift releases:

- Networking scale tests which runs uperf benchmarks testing node to node, pod to pod, and svc to svc throughput and latency for TCP and UDP protocols.
We also ran scale tests focusing on Monitoring ( Prometheus ), Logging ( Fluentd and Elasticsearch ), Storage and Registry. The scale tests are all hosted in workloads and svt repositories and are triggered using the pipeline. Here are some of the interesting findings, tunings and recommendations from the runs:
- Etcd is a critical component of OpenShift, It stores and replicates the cluster state.
For large and dense clusters, etcd can suffer from poor performance if the keyspace grows excessively large and exceeds the space quota. Periodic maintenance of etcd including defragmentation needs to be done to free up space in the data store. It is highly recommended that we monitor Prometheus for etcd metrics and defragment it when needed before etcd raises a cluster-wide alarm that puts the cluster into a maintenance mode, which only accepts key reads and deletes. Some of the key metrics to monitor are etcd_server_quota_backend_bytes which is the current quota limit, etcd_mvcc_db_total_size_in_use_in_bytes which indicates the actual database usage after a history compaction, and etcd_debugging_mvcc_db_total_size_in_bytes which shows the database size including free space waiting for defragmentation. The default Etcd space quota is 7GB, it should be good enough to support large and dense clusters. Etcd maintenance is a day 2 operation as the defragmentation is not done automatically, it is essential to monitor the metrics mentioned and act accordingly.
- Some users have requirements especially when running OpenShift on bare metal nodes might not have the luxury to use thousands of nodes in case they want to run thousands of pods. This motivated us to work on pushing the pods per node limit beyond the current supported limit of 250 pods per node - the work is still in progress.
- Scaling up the cluster to higher node counts is as simple as changing the replica count of the worker machinesets. The worker nodes are distributed across various zones of a region in the public cloud ( AWS and GCP in our case ), it’s recommended to spread them across the availability zones evenly during the scaleup as well for higher availability.
- We ran baseline workload to collect data on a base cluster with no applications running except the system components. As we keep adding enhancements to make OpenShift self healing/managed by operators, support over the air upgrades to make our life easy and also have a better user experience, the number of containers/components which run by default on the cluster increased when compared to OpenShift 3.x. The document has details about the recommended master node sizes for various node scale.
- ROUTER_THREADS is 4 by default in OpenShift 4.x, the router performance optimizations have been documented as part of the OpenShift Scalability and Performance Guide.
- The new fluentd version 1.2.x used in OpenShift 4.1 and 4.2 provides over twice the single node message throughput as the version used in OpenShift 3.x.
- The Elasticsearch version used in OpenShift 4.1 and 4.2 is unchanged from OpenShift 3.11 and message indexing throughput is comparable to that release.
- Source-to-image (S2I) build times in OpenShift 4.1 were longer than previous releases for several reasons related to how s2i builds are run and pushed to the internal registry. In OpenShift 4.2, the times were improved by 2x - 3x.
- There might be a need to tweak the kubelet config for example the qps/burst rates or the pods per node, it takes hours for the change to take effect on a cluster with large number of nodes as the change triggers a reboot of the nodes to apply the configuration and the number of nodes which can be unavailable at a given time by default is 1, it can be tweaked to speed up the process as documented in the Scalability and Performance Guide.
NOTE: When setting the value, consider the number of worker nodes that can be unavailable without affecting the applications running on the cluster.
- We ran tests focusing on Cluster Monitoring Operator to come up with the Prometheus Database storage requirements based on number of nodes/pods in the cluster, the recommendations have been documented as part of the OpenShift Scalability and Performance Guide.
- The rate at which the kubelet talks to the API server depends on queries per second (QPS) and burst values. The default values, 5 for kubeAPIQPS and 10 for kubeAPIBurst, are good enough if there are limited pods running on each node. Updating the kubelet QPS and burst rates is recommended when there are a large number of objects provided there are enough CPU and memory resources on the node, the information on how to tweak the values is discussed in the guide.
- Scaling pods with attached PVC was very reliable and consistent with only limitation being the imposition by the public cloud providers on the number of block devices per cloud instance.
- The upgrades got much easier and reliable. The machine-config operator will start complaining during the upgrades even if a single file/config is changed on the host.
Look out for part 4: Tooling/Automation Enhancements and Highlights of OpenShift 4.3 Scale Test Run. As always, feel free to reach us on sig-scalability kubernetes slack or on github. Any feedback and contributions are most welcome.
About the author

Naga Ravi Chaitanya Elluri leads the Chaos Engineering efforts at Red Hat with a focus on improving the resilience, performance and scalability of Kubernetes and making sure the platform and the applications running on it perform well under turbulent conditions. His interest lies in the cloud and distributed computing space and he has contributed to various open source projects.
More like this
A decade of open innovation: Red Hat continues to scale the open hybrid cloud with Microsoft
Stop managing the past and start building IT’s future
Crack the Cloud_Open | Command Line Heroes
Edge computing covered and diced | Technically Speaking
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds