In part 1 of the blog series, we looked at how the Red Hat OpenShift Scale-CI evolved. In part 2, we looked at various components of the Scale-CI framework. In part 3, we looked at the highlights from OpenShift 4.1 and 4.2 scale test runs on public clouds including Amazon Web Services and Google Cloud Platform. In part 4, we looked at the need for building a tool called Cerberus to be able to monitor the cluster and take action when the cluster health starts degrading. In this blog post, we will look at how we, the Performance and Scalability team at Red Hat, pushed the limits of OpenShift 4.3 at scale.
What’s New in OpenShift 4.3?
It is the third release of the OpenShift 4.x series and is based on kubernetes 1.16. It includes a bunch of features, bug fixes and enhancements for various components including install, upgrades, Machine API, cluster monitoring, scale, operators etc.as discussed in the release notes and the blog. Let’s jump straight into the scale test run, a single blog won’t be enough to walk through the features in OpenShift 4.3.
OpenShift 4.3 Scale Test Run
After we wrapped up the OpenShift 4.2 scale test run, we started gearing up for the next mission which is to see how well the OpenShift 4.3 release is going to scale. Part of the preparation included making sure the dashboards are graphing all the metrics of interest especially the ones related to Master and Etcd as they are critical for the functionality of the cluster. What are some of the critical metrics,, one might ask? The cluster and etcd dashboards tracks metrics including ApiServer Queries/Requests per second, Inflight API requests, Etcd backend DB size, Etcd leader changes ( Quite disruptive when the count is high ), resource usage, fsync ( critical for Etcd read and write operations to be fast enough ) etc.
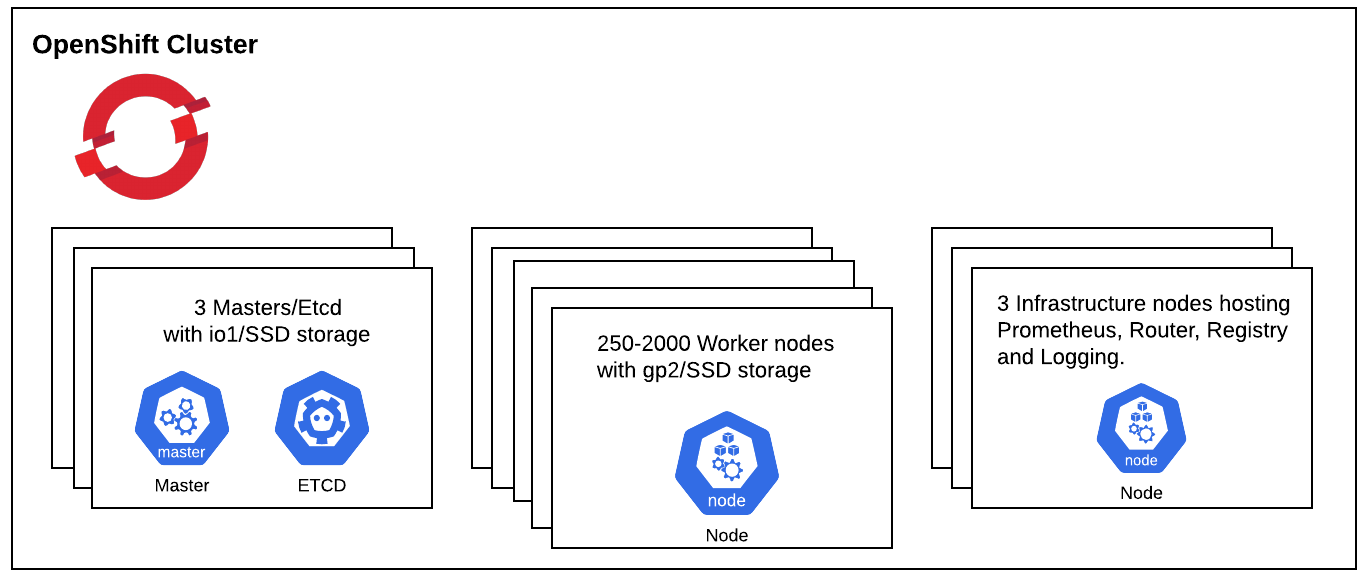
We started the run with a base cluster consisting of three Masters/Etcds, three Infrastructure nodes to host the Ingress, Registry and Monitoring stack, and three worker nodes and went on to scale up the cluster to 2000 nodes. The Performance and Scale tests were run at various node scales ( 25/100/250/2000 ) as shown below:
Any Recommendations or Tweaks Needed to Get to 2000 Nodes?
Most of the tunings and tweaks needed to help with running large clusters are now shipped as defaults in OpenShift 4.3. They include:
- ApiServer MaxInflight requests (600/1200)
- Kubelet QPS/Burst (50/100) rates
- watch based ConfigMap change strategy for Kubelet
- Watch based secret change strategy for Kubelet
These default tunings are critical for large and dense clusters to avoid getting overloaded when there are thousands of OpenShift objects and nodes running in the cluster.
Here are few of the other tweaks and recommendations:
- When installing large clusters or scaling the cluster to larger node counts, the cluster network CIDR needs to set accordingly in the `install-config.yaml` file before we install the cluster as it cannot be changed post install. The default clusterNetwork CIDR 10.128.0.0/14 cannot be used if the cluster size is more than 500 nodes. It must be set to 10.128.0.0/12 or 10.128.0.0/10 to get to larger node counts beyond 500 nodes as documented.
- When scaling up the cluster to higher node counts:
- Spread nodes across all of the available zones for higher availability.
- Scale up by no more than 25 to 50 machines at once.The machine controller might not be able to create the machines if the replicas in the MachineSets are set to higher numbers all at one time as Cloud providers might implement a quota for API services and the number of requests the cloud platform, which OpenShift Container Platform is deployed on top of, is able to handle impacts the process. The controller will start to query more while trying to create, check, and update the machines with the status. The cloud platform on which OpenShift Container Platform is deployed has API request limits, and excessive queries might lead to machine creation failures due to such cloud platform limitations. Therefore, gradually scale the cluster.
- Enable machine health checks when scaling to large node counts. In case of failures, the health checks monitor the condition and automatically repair unhealthy machines as documented.
- When running performance and scale tests at large scale, we found out that running and concurrent deletion of a huge number of projects might lead to an unstable API server due to lack of resources on the master nodes. The idle cluster with just the system components running and no applications deployed was using about 10 cores CPU at 2000 node scale, so it’s important to size the master nodes keeping this in mind to make sure the applications have enough resources to run. Note that they can’t be resized after the install.
- We also observed that Prometheus uses large amounts of resources as we get to high node counts, so we recommend hosting Prometheus on Infrastructure nodes with a significant amount of resources to make sure it does not starve. Procedure to create Infrastructure nodes is documented here.
Tested Cluster Maximums
We have tested and validated the cluster maximums including number of nodes, pods per node, number of namespaces e.t.c. to help users and customers plan their environments accordingly. Note that these maximums can be achieved, provided the environment is similar in terms of cloud platform, node type, disk size, disk type, IOPS etc. especially for Masters/Etcd nodes since Etcd is I/O intensive and latency sensitive. The tested cluster maximums as well as the environment details are documented as part of the Scalability and Performance Guide.
There have been requests from the users and field about supporting more than 250 pods per node especially for the cases where OpenShift is running on bare metal machines. The default pods per node limit is 250, but Robert Krawitz published a blog with detailed insights on how we at Red Hat tested running 500 pods per node on OpenShift 4.3.
Ensuring Node/Service Availability During Scale Down
We used to scale down the cluster during the weekends when it’s not in use. There might be a need to run services on specific nodes, but those nodes might get terminated by the machine controller when scaling down the cluster to lower node counts since the nodes to terminate gets picked randomly. How can we get around this?
Custom MachineSets can be used for use cases requiring that services run on specific nodes and that those services are ignored by the controller when the worker MachineSets are scaling down. This prevents service disruption.
The nodes termination can be prioritized during the cluster scale down, and here are the ways to mark MachineSets for the controller to take them into consideration:
- Random, Newest, and Oldest are the three supported MachineSet delete policies. The default is Random, meaning that random machines are chosen and deleted when scaling MachineSets down. The delete policy can be set according to the use case by modifying the particular MachineSet:

- Specific machines can also be prioritized for deletion by adding the annotation `machine.openshift.io/cluster-api-delete-machine` to the machine of interest, regardless of the delete policy.
Other Findings
We ran a number of tests to look at the Performance and Scalability of various components of OpenShift including Networking, Kubelet, Router, Control Plane, Logging, Monitoring, Storage and Cluster Maximums. Here are some of the findings:
- There’s no performance regression for Router when compared to the previous release since the HAproxy version (1.18.17) is the same as in OpenShift 4.2.
- Pipeline build strategy is deprecated as of OCP 4.3, so it’s recommended to use Source-to-Image (S2I) strategy for builds.
- The control plane, or rather API server and Etcd, performed better with thousands of objects/nodes running in the cluster. There has been a lot of work that Red Hat did on OpenAPI merging code inside of kube-apiserver in the upstream community, including avoiding deep copy. Watch-based ConfigMap and Secret Change Detection Strategy for kubelet, which is the default in OpenShift 4.3, also helped with the API server load. Etcd’s 7GB backend storage quota (default) is good enough to run and remain stable even when we hit cluster maximums. Cluster Etcd Operator is going to be part of the upcoming release (OpenShift 4.4) to manage the lifecycle of the Etcd members. It is going to make the disaster recovery much easier as well as reduce the bootstrap timing leading to faster cluster installs when compared to OpenShift 4.3. It’s important to use the disks with low fync timings for Masters and Etcds nodes as it’s critical for Etcd’s performance.
- OCS v4.3 is stable and scales well. With OCS v4.3, we can achieve higher density of pods with persistent volume claims (PVCs) per node than for cases when cloud provider storage classes are used as storage providers for applications. Also, deleting PVC (and backend storage) is fast and reliable.
- No major regression in terms of networking with OpenShift SDN as the network plugin (default) when compared to OpenShift 4.2. The blog post by Courtney Pacheco and Mohit Sheth walks through the process of benchmarking network performance on OpenShift using Ripsaw as well as the results.
- We did not observe any major performance differences for the logging component since Elasticsearch's major version was unchanged in OpenShift 4.3 when compared to OpenShift 4.2.
- During the upgrades, the Cluster Version Operator (CVO) in the cluster checks with the OpenShift Container Platform update service to see the valid updates and update paths based on current component versions. During the upgrade process, the Machine Config Operator (MCO) applies the new configuration to the cluster machines. It cordons the number of nodes that are specified by the maxUnavailable field on the machine configuration pool, so they are drained. Once the drain is finished, it applies the new configuration and reboots them. This operation is applied on a serial basis, and the number of nodes that can be unavailable at a given time is one by default, meaning it is going to take a long time when there are hundreds or thousands of nodes. That is because upgrading each node would need to drain and reboot each node after applying the latest ostree layer. Tuning the maxUnavailable parameter of the worker’s MachineConfigPool should speed up node upgrade time. We need to make sure to set it to a value that avoids causing disruption to any services.
Refer to the Scalability and Performance Guide for more information on how to plan the OpenShift environments to be more scalable and performant.
What’s Next?
Stay tuned for the upcoming blog posts on more tooling and automation enhancements, including introducing chaos experiments into the test suite to ensure the reliability of OpenShift during turbulent conditions as well as highlights from the next large scale test runs on clusters ranging from 250 to 2000 nodes. As always, feel free to reach us out on Github - https://github.com/cloud-bulldozer, https://github.com/openshift-scale or sig-scalability channel on Kubernetes Slack.
About the author

Naga Ravi Chaitanya Elluri leads the Chaos Engineering efforts at Red Hat with a focus on improving the resilience, performance and scalability of Kubernetes and making sure the platform and the applications running on it perform well under turbulent conditions. His interest lies in the cloud and distributed computing space and he has contributed to various open source projects.
More like this
A decade of open innovation: Red Hat continues to scale the open hybrid cloud with Microsoft
Stop managing the past and start building IT’s future
Crack the Cloud_Open | Command Line Heroes
Edge computing covered and diced | Technically Speaking
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds