Intel recently launched the 4th generation of Intel® Xeon® Scalable processors, a family of high-end, enterprise-focused processors targeted at a diverse range of workloads. To explore how Intel’s new chips measure up, we’ve worked with Intel and others to run benchmarks with Red Hat Enterprise Linux 8.4, 8.5, 8.6, 9.0 and 9.1, as well as CentOS Stream 9.2 (which will become Red Hat Enterprise Linux 9.2).
The new 4th gen (created under the codename Sapphire Rapids) packages include more CPUs per socket – up to 60 cores and 120 threads – compared to the 3rd generation with up to 36 cores and 72 threads. In addition, the 4th generation memory features DDR5 4800 MT/s with four UPI links @ 16 GT/s per socket along with 80 lanes of PCIe gen5 I/O capabilities.
Beyond these expected generational improvements of more cores and faster memory and I/O, Intel's 4th gen systems add many new CPU features and several innovative accelerators including:
- Intel® Advanced Matrix Extensions (Intel® AMX) to speed up low-precision math and accelerate AI/ML
- Intel® Data Streaming Accelerator (Intel® DSA) to copy and move data faster and assist *PDK
- Intel® QuickAssist Technology (Intel® QAT) to accelerate compression, encryption, and decryption
- Intel® In-memory Analytics Accelerator (Intel® IAA) to speed up query processing performance
- Intel® Dynamic Load Balancer (Intel® DLB) to help speed up data queues
Additionally, the Intel® Xeon® CPU Max Series processors systems add 64GB of high bandwidth memory (HBM2e) on-die per package for ultrahigh memory bandwidth.
RHEL 9.1 compression performance with Intel® QuickAssistTechnology (Intel® QAT)
Intel® QAT is a set of hardware and software technologies that are designed to improve the performance of computing and networking workloads. Intel® QAT includes accelerators that are optimized for symmetric and asymmetric cryptography, compression/decompression, and other compute-intensive tasks. The Intel® QAT accelerator offloads compute-intensive tasks from the CPU, freeing up processing resources for other tasks.
On the latest 4th generation of Intel® Xeon Scalable processors, Intel® QAT is built into the processor. Up to 4 QAT endpoints are available per processor, depending on the exact SKU. This section looks at compression performance of the Intel® QAT accelerator on the new Intel chips. The system we used had two sockets containing Intel® Xeon® Platinum 8480+ processors; each processor had a single Intel® QAT endpoint. [10]
Firmware configuration
At the time of writing, RHEL 9.1 does not yet include the QAT firmware files and needs to be installed manually. Future Red Hat Enterprise Linux updates will include the QAT firmware out of the box.
# Make sure the QAT service is installed dnf install -y qatlib # Download the quickassist firmware # cd /lib/firmware # wget https://git.kernel.org/pub/scm/linux/kernel/git/firmware/linux-firmware.git/plain/qat_4xxx.bin # wget https://git.kernel.org/pub/scm/linux/kernel/git/firmware/linux-firmware.git/plain/qat_4xxx_mmp.bin # Unload and reload qat driver so the new firmware gets loaded modprobe -r qat_4xxx modprobe qat_4xxx # Restart the QAT service systemctl restart qat
See footnotes [10] and [12] for additional hardware and software configuration details.
Workload Configuration
- We used the “test” tool from the QATzip sources (https://github.com/intel/QATzip/tree/master/test) to test the performance of compression
- We compressed a file containing all the files from the Silesia corpus data set (http://sun.aei.polsl.pl/~sdeor/corpus/silesia.zip)
- We used multiple compression processes to compress files in parallel, using taskset to pin each compression process to a separate core
- We tried compression using 1/2/4/8/16/32 cores, dividing the cores used between both sockets
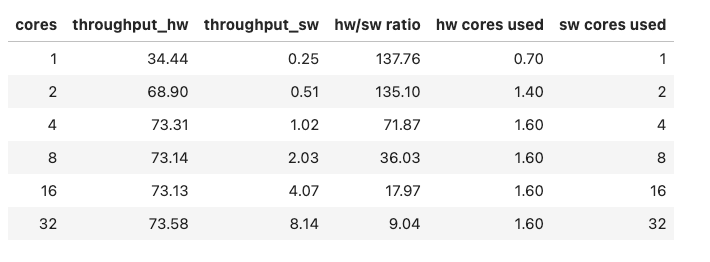
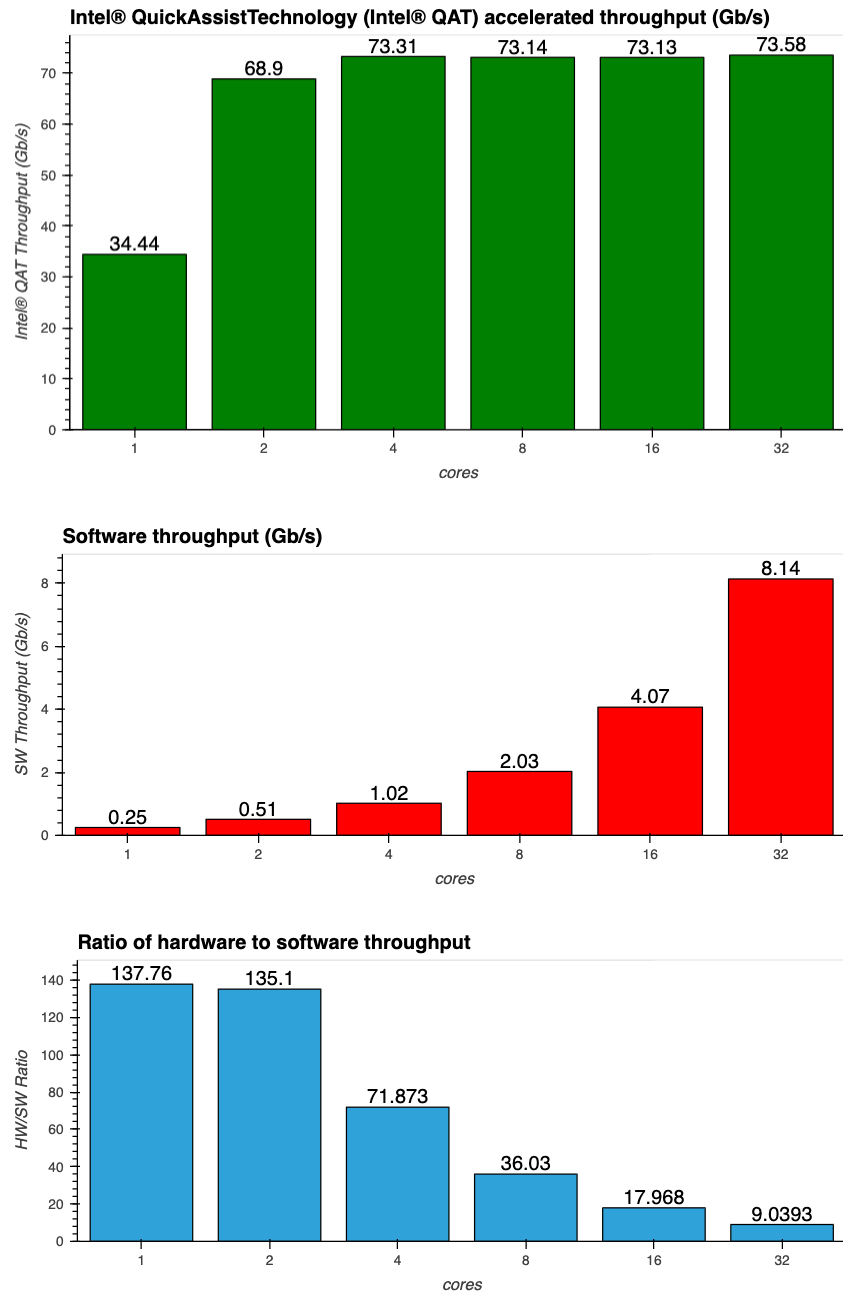
Throughput (Gb/s) for Silesia corpus
For the Silesia corpus data, the peak throughput was 73 Gb/s, for a configuration using four or more compression processes. When not using Intel QAT hardware acceleration, the 1 process compression rate is 0.25 Gb/s whereas the 1 process compression rate when using Intel QAT HW is 34 Gb/s. The software compression scales with additional cores, whereas the hardware compression rate peaks using four cores because the SKU we were using only had one Intel QAT endpoint per socket.
The "hw cores used" column indicates the number of cores used when using Intel QAT hardware compression. We used only 1.6 cores to achieve the peak compression of 73 Gb/s, because most of the CPU work is being offloaded to the Intel QAT hardware. By contrast, when using software compression we are using the entire core, thus reducing the CPU bandwidth available for non-compression tasks.
We saturated the two QAT endpoints with 4 compression processes, which is why the hardware throughput remains flat for 4/8/16/32 cores, whereas the software throughput continues to scale up
RHEL 9.1 Intel® QAT Compression performance summary
The data we gathered for Intel® QAT compression performance shows that Intel® QAT hardware accelerated compression can be significantly faster than using software compression (ranging from 9X to 137X faster). Using Intel® QAT for offloading compression also uses significantly less processor CPU, which allows more CPU cycles to be available for other computing tasks.
RHEL 9.2 AI/ML performance with Intel® AMX
The new 4th Gen Intel® Xeon® Scalable processors inherit Intel® Advanced Vector Extensions 512 (Intel® AVX-512) instructions including VNNI, and add new Intel® Advanced Matrix Extensions (Intel® AMX) features to accelerate vector and matrix math. Linear algebra is fundamental to many HPC and AI/ML application codes. The new Intel AMX features supporting low precision data types, like BF16 and INT8,are especially useful in AI/ML applications. Many of the new AI/ML computational capabilities are thoroughly explained in Intel’s excellent Tuning Guide for AI on the 4th Generation Intel® Xeon® Scalable Processors. Intel has been busily working with upstream versions of PyTorch and TensorFlow to integrate the latest capabilities of the 4th Gen Intel® Xeon® Scalable processors.
Here we explore some of Intel’s 4th gen processor AI/ML capabilities by comparing performance to the previous 3rd Generation Intel® Xeon® Scalable Processor (created under the codename Cooper Lake) using Phoronix Test Suite (PTS) benchmarks for TensorFlow, Intel® oneAPI Deep Neural Network (oneDNN), OpenVINO™, and ONNX. These four benchmark suites have more than 75 subtests between them. (See [13] for more PTS information and instructions about how to reproduce our experimental results). Our results show 4th gen speedup factors ranging from an average of 1.5x up to 10x faster.
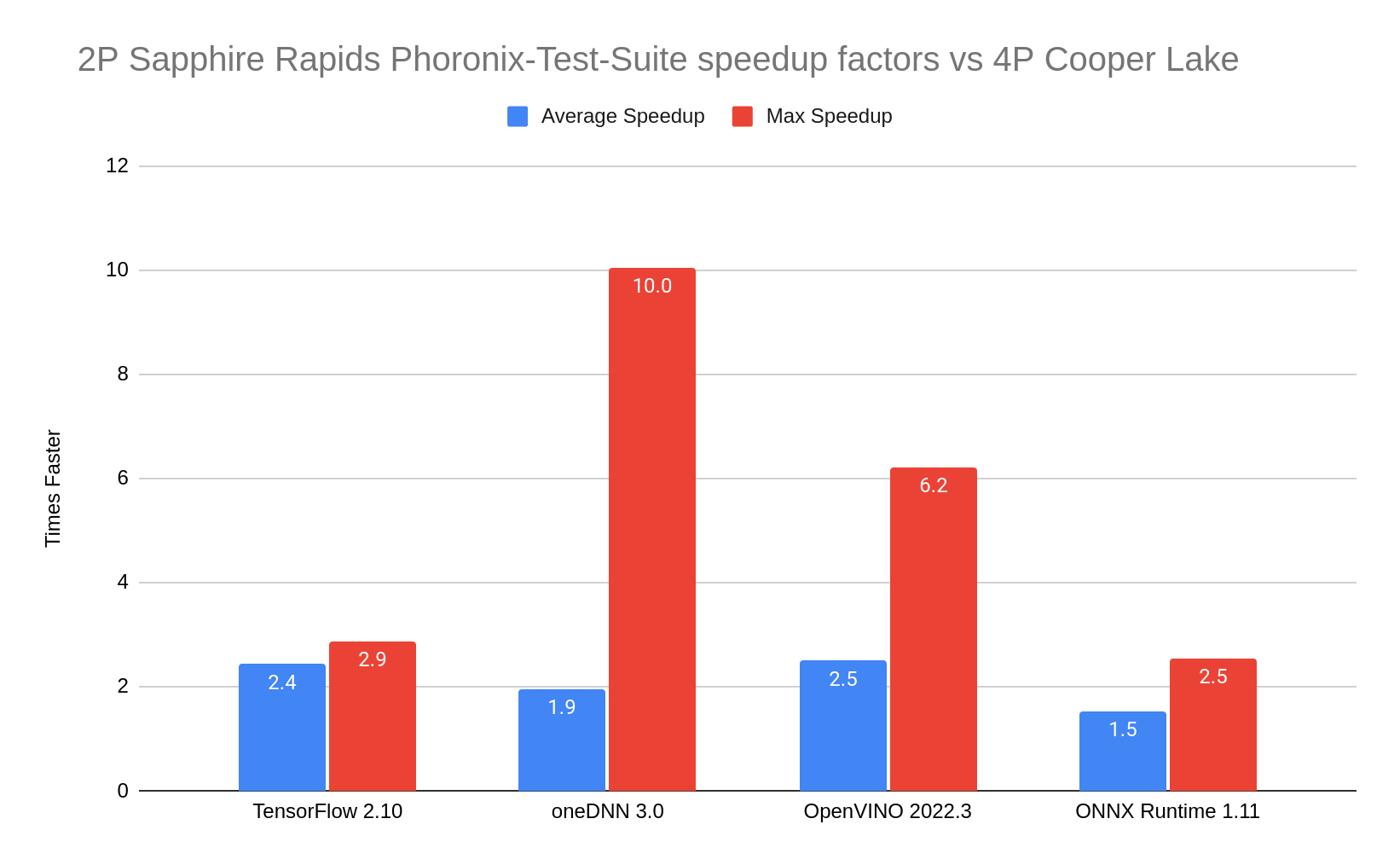
We used CentOS Stream 9.2 containers running on a system with 4th Gen Intel Xeon Scalable Processors and a system with 3rd Gen Intel Xeon Scalable Processors. (See [10] and [11] for the system configurations). Comparing these 4th and 3rd Gen Intel Xeon Scalable Processor systems is somewhat of an apple to orange comparison, especially since there are a different number of sockets and cores. However, the 3rd Gen Intel Xeon Scalable Processor system does have some BF16 and VNNI features, and is still highly performant. In fact, about 10 of the 75 or so results from the 3rd Gen Intel Xeon Scalable Processor subtests are actually still in the top 10 percent of known recent CPU results for those respective tests. No special settings or adjustments were made while running the benchmark suites. This 3rd Gen versus 4th Gen Intel Xeon Scalable Processor comparison highlights out-of-the-box PTS performance results that anyone should be able to easily reproduce.
RHEL 8.6 SAP HANA Leadership on Intel® 4th Generation Xeon® Scalable Processor
Leaning on our long history of collaboration, Red Hat and Intel once again worked together to deliver state-of-the-art performance to enterprise data centers and beyond. Red Hat’s development and performance engineering teams have been working on hardware enablement and validation of these new scalable processors for more than a year running a variety of benchmarks prior to the GA release of Red Hat Enterprise Linux.
Higher per-core performance, faster memory and storage combined with workload-optimized cores benefit overall system performance. To demonstrate performance and provide additional scalability and sizing information for SAP HANA applications and workloads, SAP introduced the Business Warehouse (BW) edition of SAP HANA Standard Application Benchmark [1]. Presently on version 3, this benchmark simulates a variety of users with different analytical requirements and measures the key performance indicator (KPI) relevant to each of the three benchmark phases, which are defined below:
- Data load phase, testing data latency and load performance (lower is better)
- Query throughput phase, testing query throughput with moderately complex queries (higher is better)
- Query runtime phase, testing the performance of running very complex queries (lower is better)
Red Hat Enterprise Linux (RHEL) was used in several recent publications of the above benchmark. Specifically, three separate initial record sizes (2.6, 3.9, and 6.5 billion records) using a Dell PowerEdge R760 server with 4th Gen Intel® Xeon® Scalable processors, demonstrated that running the workload on Red Hat Enterprise Linux could deliver the overall world record across all three benchmark KPIs and outperform similarly configured servers (see Table 1).
Table 1. Results in scale-up category running SAP BW Edition for SAP HANA Standard Application Benchmark, Version 3 on SAP NetWeaver 7.50 and SAP HANA 2.0
| Initial Records (Billions) | Phase 1 (lower is better) | Phase 2 (higher is better) | Phase 3 (lower is better) | |
| Red Hat Enterprise Linux 8.6 [2] | 2.6 | 7,385 sec | 11,648 | 71 sec |
| SUSE Linux Enterprise Server 15 [3] | 2.6 | 8,750 sec | 11,560 | 78 sec |
| Red Hat Enterprise Linux advantage | 16.9% | .8% | 9.4% | |
| Red Hat Enterprise Linux 8.6 [4] | 3.9 | 8,136 sec | 9,699 | 74 sec |
| SUSE Linux Enterprise Server 15 [5] | 3.9 | 9,500 sec | 9,251 | 84 sec |
| Red Hat Enterprise Linux advantage | 15.5% | 4.7% | 12.7% | |
| Red Hat Enterprise Linux 8.6 [6] | 6.5 | 10,532 sec | 6,030 | 82 sec |
| SUSE Linux Enterprise Server 15 [7] | 6.5 | 12,463 sec | 5,136 | 96 sec |
| Red Hat Enterprise Linux advantage | 16.8% | 16.0% | 15.7% |
Additionally, using a dataset size of 5.2 billion initial records, a Dell EMC PowerEdge R760 server running Red Hat Enterprise Linux also outscored a similarly configured server on two out of three benchmark KPIs demonstrating better dataset load time and complex query runtime (see Table 2).
Table 2. Results in scale-up category running SAP BW Edition for SAP HANA Standard Application Benchmark, Version 3 on SAP NetWeaver 7.50 and SAP HANA 2.0
| Initial Records (Billions) | Phase 1 (lower is better) | Phase 2 (higher is better) | Phase 3 (lower is better) | |
| Red Hat Enterprise Linux 8.6 [8] | 5.2 | 9,269 sec | 7,600 | 76 sec |
| SUSE Linux Enterprise Server 15 [9] | 5.2 | 10,437 sec | 6,661 | 81 sec |
| Red Hat Enterprise Linux advantage | 11.9% | 13.2% | 6.4% |
These results demonstrate Red Hat’s commitment to helping OEM partners and ISVs deliver high-performing solutions to our mutual customers and showcase close alignment between Red Hat and Dell that, in collaboration with SAP, led to the creation of certified, single-source solutions for SAP HANA. Available in both single-server and larger, scale-out configurations, Dell’s solution is optimized with Red Hat Enterprise Linux for SAP Solutions.
Learn more
- Red Hat and Dell Technologies solutions
- Red Hat Enterprise Linux for SAP Solutions
Footnotes
[1] SAP Results as of March 1, 2023, SAP and SAP HANA are the registered trademarks of SAP AG in Germany and in several other countries. See www.sap.com/benchmark for more information.
[2] Dell PowerEdge R760 (2 processor / 112 cores / 224 threads, Intel Xeon
Platinum 8480+ processor, 2.0 GHz, 80 KB L1 cache and 2048 KB L2 cache per core, 105 MB L3 cache per processor, 2048 GB main memory). Certification number #2023011
[3] FUJITSU Server PRIMERGY RX2540 M7 (2 processor / 112 cores / 224 threads, Intel Xeon
Platinum 8480+ processor, 2.0 GHz, 80 KB L1 cache and 2048 KB L2 cache per core, 105 MB L3 cache per processor, 2048 GB main memory). Certification number #2023001
[4] Dell PowerEdge R760 (2 processor / 112 cores / 224 threads, Intel Xeon
Platinum 8480+ processor, 2.0 GHz, 80 KB L1 cache and 2048 KB L2 cache per core, 105 MB L3 cache per processor, 2048 GB main memory). Certification number #2023012
[5] FUJITSU Server PRIMERGY RX2540 M7 (2 processor / 112 cores / 224 threads, Intel Xeon
Platinum 8480+ processor, 2.0 GHz, 80 KB L1 cache and 2048 KB L2 cache per core, 105 MB L3 cache per processor, 2048 GB main memory). Certification number #2023006
[6] Dell PowerEdge R760 (2 processor / 112 cores / 224 threads, Intel Xeon
Platinum 8480+ processor, 2.0 GHz, 80 KB L1 cache and 2048 KB L2 cache per core, 105 MB L3 cache per processor, 2048 GB main memory). Certification number #2023014
[7] FUJITSU Server PRIMERGY RX4770 M6 (4 processor / 112 cores / 224 threads, Intel Xeon
Platinum 8380HL processor, 2.9 GHz, 64 KB L1 cache and 1024 KB L2 cache per core, 38.5 MB L3 cache per processor, 768 GB main memory, 3072 GB persistent memory). Certification number #2020039
[8] Dell PowerEdge R760 (2 processor / 112 cores / 224 threads, Intel Xeon
Platinum 8480+ processor, 2.0 GHz, 80 KB L1 cache and 2048 KB L2 cache per core, 105 MB L3 cache per processor, 2048 GB main memory). Certification number #2023013
[9] Lenovo ThinkSystem SR860 V2 (4 processor / 112 cores / 224 threads, Intel Xeon
Platinum 8380HL processor, 2.9 GHz, 64 KB L1 cache and 1024 KB L2 cache per core, 38.5 MB L3 cache per processor, 3072 GB main memory). Certification number #2021017
[10] Sapphire Rapids Hardware Configuration
Processor: 2 x Intel Xeon Platinum 8480+ @ 3.80GHz (112 Cores / 224 Threads)
Motherboard: Intel D50DNP1SBB (SE5C7411.86B.9525.D13.2302071332 BIOS)
Memory: 512GB @ 4800 MT/s
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 52 bits physical, 57 bits virtual
Byte Order: Little Endian
CPU(s): 224
On-line CPU(s) list: 0-223
Vendor ID: GenuineIntel
BIOS Vendor ID: Intel(R) Corporation
Model name: Intel(R) Xeon(R) Platinum 8480+
BIOS Model name: Intel(R) Xeon(R) Platinum 8480+
CPU family: 6
Model: 143
Thread(s) per core: 2
Core(s) per socket: 56
Socket(s): 2
Stepping: 6
CPU max MHz: 3800.0000
CPU min MHz: 800.0000
BogoMIPS: 4000.00
Flags:
fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf tsc_known_freq pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb cat_l3 cat_l2 cdp_l3 invpcid_single intel_ppin cdp_l2 ssbd mba ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid cqm rdt_a avx512f avx512dq rdseed adx smap avx512ifma clflushopt clwb intel_pt avx512cd sha_ni avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local split_lock_detect avx_vnni avx512_bf16 wbnoinvd dtherm ida arat pln pts hwp hwp_act_window hwp_epp hwp_pkg_req avx512vbmi umip pku ospke waitpkg avx512_vbmi2 gfni vaes vpclmulqdq avx512_vnni avx512_bitalg tme avx512_vpopcntdq la57 rdpid bus_lock_detect cldemote movdiri movdir64b enqcmd fsrm md_clear serialize tsxldtrk pconfig arch_lbr ibt amx_bf16 avx512_fp16 amx_tile amx_int8 flush_l1d arch_capabilities
Virtualization features:
Virtualization: VT-x
Caches (sum of all):
L1d: 5.3 MiB (112 instances)
L1i: 3.5 MiB (112 instances)
L2: 224 MiB (112 instances)
L3: 210 MiB (2 instances)
NUMA:
NUMA node(s): 2
NUMA node0 CPU(s): 0-55,112-167
NUMA node1 CPU(s): 56-111,168-223
Vulnerabilities:
Itlb multihit: Not affected
L1tf: Not affected
Mds: Not affected
Meltdown: Not affected
Mmio stale data: Not affected
Retbleed: Not affected
Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl
Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Spectre v2: Mitigation; Enhanced IBRS, IBPB conditional, RSB filling, PBRSB-eIBRS SW sequence
Srbds: Not affected
Tsx async abort: Not affected
[11] Cooper Lake Hardware Configuration
Processor: 4 x Intel Xeon Platinum 8353H @ 3.80GHz (72 Cores / 144 Threads)
Motherboard: Intel WHITLEY CPX (WLYDCRB1.SYS.0018.P25.2101120402 BIOS)
Memory: 1136GB @ 3200 MT/s
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 46 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 144
On-line CPU(s) list: 0-143
Vendor ID: GenuineIntel
BIOS Vendor ID: Intel(R) Corporation
Model name: Intel(R) Xeon(R) Platinum 8353H CPU @ 2.50GHz
BIOS Model name: Intel(R) Xeon(R) Platinum 8353H CPU @ 2.50GHz
CPU family: 6
Model: 85
Thread(s) per core: 2
Core(s) per socket: 18
Socket(s): 4
Stepping: 11
CPU max MHz: 3800.0000
CPU min MHz: 1000.0000
BogoMIPS: 5000.00
Flags:
fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb cat_l3 cdp_l3 invpcid_single intel_ppin ssbd mba ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid cqm mpx rdt_a avx512f avx512dq rdseed adx smap clflushopt clwb intel_pt avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local avx512_bf16 dtherm ida arat pln pts hwp hwp_act_window hwp_epp hwp_pkg_req pku ospke avx512_vnni md_clear flush_l1d arch_capabilities
Virtualization features:
Virtualization: VT-x
Caches (sum of all):
L1d: 2.3 MiB (72 instances)
L1i: 2.3 MiB (72 instances)
L2: 72 MiB (72 instances)
L3: 99 MiB (4 instances)
NUMA:
NUMA node(s): 4
NUMA node0 CPU(s): 0-17,72-89
NUMA node1 CPU(s): 18-35,90-107
NUMA node2 CPU(s): 36-53,108-125
NUMA node3 CPU(s): 54-71,126-143
Vulnerabilities:
Itlb multihit: Not affected
L1tf: Not affected
Mds: Not affected
Meltdown: Not affected
Mmio stale data: Mitigation; Clear CPU buffers; SMT vulnerable
Retbleed: Mitigation; Enhanced IBRS
Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl
Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Spectre v2: Mitigation; Enhanced IBRS, IBPB conditional, RSB filling, PBRSB-eIBRS SW sequence
Srbds: Not affected
Tsx async abort: Not affected
[12] QAT Configuration Details
QAT OS Version
Red Hat Enterprise Linux release 9.1 (Plow)
Kernel Version
Linux spr-host 5.14.0-162.6.1.el9_1.x86_64 #1 SMP PREEMPT_DYNAMIC Fri Sep 30 07:36:03 EDT 2022 x86_64 x86_64 x86_64 GNU/Linux
Note that the kernel should be booted with the intel_iommu=on command line option.
Additional QAT Configuration Steps
[root@spr-host ~]# cat /etc/sysconfig/qat
POLICY=1
ServicesEnabled=dc
[13] Using Phoronix-Test-Suites in Containers
The PTS framework is an extremely convenient way to run performance tests, and it has a large ecosystem with many recorded results available for comparison. For official information, including official instructions explaining how to run PTS tests, see Phoronix Test Suite and OpenBenchmarking.org.
We ran the AI/ML related tests in Centos Stream 9.2 containers to avoid any accidental modifications to the host system environment and to enforce a clean slate for each repeated trial
Steps to reproduce the AI/ML related test results on your system:
podman run -it --rm --net=host --privileged centos:stream9 /bin/bash
sed -i "/\[crb\]/,+9s/enabled=0/enabled=1/" /etc/yum.repos.d/centos.repo
dnf -y install https://dl.fedoraproject.org/pub/epel/epel-release-latest-9.noarch.rpm
dnf -y install autoconf automake binutils bzip2 cmake expat-devel findutils gcc gcc-c++ git gmock-devel gzip iputils libusb-devel libusbx-devel make nfs-utils opencv openssl-devel patch pciutils php-cli php-json php-xml procps-ng python3 python3-pip python3-yaml tar unzip vim-enhanced wget xz zip
At this point you might mount a shared volume with phoronix-test-suite already installed, or you can just download and unpack it in the container with steps like these:
wget https://phoronix-test-suite.com/releases/phoronix-test-suite-10.8.4.tar.gz
tar xvzf phoronix-test-suite-10.8.4.tar.gz
cd phoronix-test-suite
./phoronix-test-suite install onednn-3.0.0 onnx-1.5.0 openvino-1.2.0 tensorflow-2.0.0
./phoronix-test-suite benchmark onednn-3.0.0 onnx-1.5.0 openvino-1.2.0 tensorflow-2.0.0
About the authors

Michey is a member of the Red Hat Performance Engineering team, and works on bare metal/virtualization performance and machine learning performance.. His areas of expertise include storage performance, Linux kernel performance, and performance tooling.

More like this
A decade of open innovation: Red Hat continues to scale the open hybrid cloud with Microsoft
Red Hat Device Edge now available to run on NVIDIA Jetson Orin
OS Wars_part 1 | Command Line Heroes
OS Wars_part 2: Rise of Linux | Command Line Heroes
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds