Enterprises can now serve Earth and space AI models—like those developed by NASA and IBM—on Red Hat AI Inference Server, with autoscaling on Red Hat OpenShift AI.
Earth and space AI is moving from research to production—extreme weather risk, solar flare forecasting, disaster response, precision agriculture, and urban planning all depend on turning petabytes of satellite and sensor data into decisions. New foundation models, like those developed by NASA and IBM, bring high-accuracy, multimodal representations of the systems captured by these petabytes of data. This includes Prithvi-EO for tasks such as flood detection and landslide mapping, Prithvi-WxC for weather and climate modelling, and Surya, the first foundation model for the Sun, for predicting space weather events that can disrupt critical infrastructure on Earth.
Red Hat AI Inference Server provides a hardened, supported vLLM distribution to serve these models anywhere, while Red Hat OpenShift AI delivers on-demand autoscaling (including scale to zero) to match bursty workloads typical of the geospatial domain. In this blog post, we show the performance and scaling benefits of running Prithvi-EO-2.0 via AI Inference Server and OpenShift AI, the first Earth and space foundation model to be fully enabled within the Red Hat AI stack.
What Earth and space AI models are available today?
IBM Research’s TerraTorch is an open source framework enabling fine-tuning and inference for a growing set of Earth and space foundation models. Designed for scientific workloads, TerraTorch is part of TerraStackAI and supports multimodal, multitemporal, and non-autoregressive architectures commonly used in Earth and space science. To support these models in production, IBM Research contributed new capabilities to vLLM that enable efficient serving of any modality, non-autoregressive decoder models. A TerraTorch backend was also added to vLLM, allowing any TerraTorch-compatible models to be served directly by vLLM.
The capability to serve TerraTorch compatible models is now available in AI Inference Server 3.3. A key example is Prithvi-EO-2.0 and its fine-tuned variants. Prithvi-EO-2.0 is a multitemporal Vision Transformer (ViT) trained on 4.2 million harmonized Landsat Sentinel-2 images. It uses 3D patch and positional embeddings to capture spatiotemporal context, applying various computer vision techniques (such as pixel-wise regression, semantic segmentation, classification, object or anomaly detection task) to enable applications such as flood segmentation, burn scar detection, and crop classification. Both the base model and task-specific variants are available on Hugging Face and can now be served at scale using AI Inference Server and OpenShift AI.
Serving your own Earth and space model with AI Inference Server 3.3
You can serve your own model with AI Inference Server by registering it to vLLM as a general plugin. This must be made available to AI Inference Server when it is started, for example, via a persistent volume claims (PVC) or docker mount, and installed into the main Python environment used for starting vLLM. Similar to other models, vLLM expects out-of-tree models to be available on Hugging Face, or for their weights and configuration file to be available locally.
2 types of inference are supported, tensor-to-tensor and image-to-image. Tensor-to-tensor is supported for both pixel-wise regression and segmentation tasks for all tensor dimensions. Image-to-image is supported for segmentation tasks via our generic segmentation task IOProcessor. If your model needs different inputs, or the generic segmentation task IOProcessor is not compatible, you can provide your own IOProcessor.
To distribute the model to others, you can publish your vLLM general plugin code on a publicly accessible repository and place the model weights and config.json on Hugging Face.
Serving Earth and space inference with Red Hat AI Inference Server
Red Hat AI Inference Server provides a hardened and supported version of vLLM for enterprise inference. It exposes an OpenAI-compatible API and integrates with OpenShift AI and Red Hat Enterprise Linux AI (RHEL AI).
How does vLLM benefit Earth and space model serving?
Unlike large language models (LLMs), Earth and space observation models like Prithvi -EO-2.0 generate outputs in a non-autoregressive fashion, that is in a single pass. For these types of models, the big wins with vLLM are its request queuing and scheduling capabilities: continuous batching (high throughput under concurrency) and I/O-core inference splitting (maximizing GPU utilization while multimodal input/output processing is offloaded to a different process).
Continuous batching
vLLM’s scheduler dynamically merges requests arriving close in time into batches to increase GPU occupancy, and hence throughput, even when each inference is short and single pass.
I/O-inference split
vLLM separates the serving layer (including input and output processing) from the engine (inference) and supports asynchronous request handling. This means input/output (I/O) operations don’t block on GPU work and vice-versa—the engine schedules work independently and returns results when ready. I/O processors leverage Python's asyncio, so concurrent operations from multiple requests don’t block each other on read or downloads.
Performance results: Increasing throughout by pipelining inference stages with vLLM
With AI Inference Server 3.3, model serving benefits directly from vLLM 0.13’s dynamic batching, async I/O pipeline, and server/engine split, enabling high‑throughput inference, particularly when images are fetched from remote URLs.
In our tests, AI Inference Server sustained 14.6 tiles/sec, a 4.43× improvement over the limit of serial inference for 512x512 images (2MB)—"tiles" in geospatial parlance—downloaded via URL and processed by Prithvi-EO-2.0-300M-TL-Sen1Floods11. A single serial request takes on average 0.291s, spending ~0.23s on network I/O and only ~0.04s on inference. AI Inference Server increases throughput by pipelining these stages across many requests—overlapping downloads with inference, performing multiple concurrent downloads via async I/O, and dynamically batching inference operations on the engine side.
As Figure 1 shows, throughput climbs with increasing request rate until it plateaus at 14.6 tiles/sec, which is primarily due to a combination of the post-processing being serialized and reaching the limit of the outbound bandwidth on our test cluster. Figure 2 shows the corresponding latency profile: response times remain stable up to 10 requests per second (rps). They begin to rise as they approach the throughput limit, due to transient queuing and inference batching. After the max throughput, all requests queue and latency increases sharply.
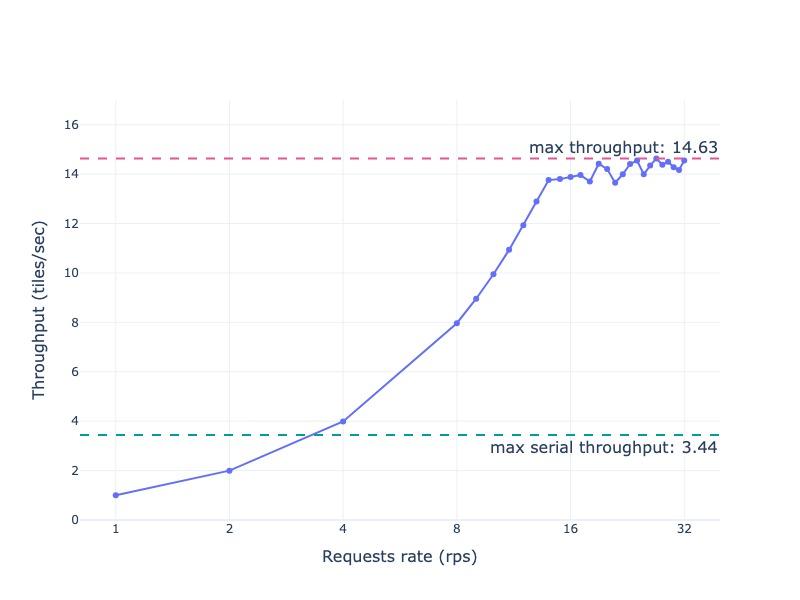
Figure 1: Throughput of Prithvi-EO-2.0-300M-TL-Sen1Floods11 served via AI Inference Server 3.3 and processing 512x512 tiles downloaded from Hugging Face
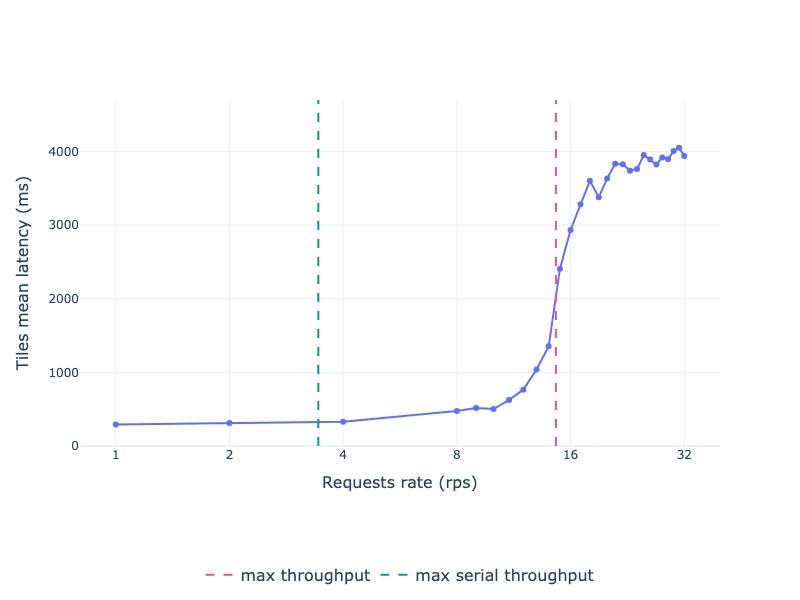
Figure 2: Average latency of Prithvi-EO-2.0-300M-TL-Sen1Floods11 served via AI Inference Server 3.3 and processing 512x512 tiles downloaded from Hugging Face
Scaling model serving with OpenShift AI
The demand for Earth and space observation models is bursty: emergency events (floods, fires), seasonal crop management, solar active region emergence, scheduled monitoring windows, and nightly satellite downlinks create spikes in inference requests. Combining Kserve with KEDA provides autoscaling of inference services based on custom vLLM metrics to control cost while meeting service level agreements (SLAs).
Combining AI Inference server with Kserve and KEDA matches load through the following capabilities:
- Autoscaling: scale the number of servers based on values of custom vLLM metrics
- Scaling settings: Set min/max scale bounds, tune to rapidly respond to request bursts
- Scale to zero: Scale down servers and free GPUs when not needed to save costGPU scheduling: Combine with OpenShift and NVIDIA GPU Operator and Node Feature Discovery label GPU nodes to scale with correct resources
Why AI Inference Server for Earth and space?
The enterprise benefits of using AI Inference Server for Earth and space inference requests include:
- Elastic cost control: Scale up under load, scale downwhen idle—ideal for event-driven geospatial pipelines
- Operational consistency: Same AI Inference Server image on RHEL AI or OpenShift AI on cloud or edge
- Open ecosystem and hardware choice: vLLM supports diverse accelerators, AI Inference Server delivers enterprise-grade support with Red Hat integrations
- Future-ready multimodality: Harness vLLM’s evolution beyond text to include Earth and space models, general vision models, and multimodal input/output
Beyond Earth and space models
The enhancements introduced to vLLM are domain-agnostic and enable serving a broad class of non-autoregressive, non-text models across scientific and industrial domains. Models with complex preprocessing or postprocessing requirements can encapsulate that logic in custom I/O processors and gain the inference pipelining features we demonstrated above for Pritvhi.
Learn more
- Check the documentation
- Read Red Hat’s overview of how vLLM accelerates AI inference and enterprise use cases
- Deep dive into Red Hat AI Inference Server technical architecture and parallelism
- Explore using vLLM for geospatial serving mechanics and more
- Try Prithvi models in your environment: Hugging Face, GitHub
Product
Red Hat AI
About the authors

Michael Johnston is a Research Scientist and Manager of the Next Generation Systems team at IBM Research Ireland. His work sits at the intersection of high-performance computing, application design, and computational biophysics and biochemistry, with a focus on building and evaluating next-generation platforms that support data- and AI-driven science.
He has worked closely with the Hartree Centre—IBM’s collaboration with the UK Science and Technology Facilities Council (STFC)—across projects including the Square Kilometre Array (SKA) Telescope, which aims to observe the universe in unprecedented detail, and Oasis, a tool for estimating catastrophe losses. A significant part of his research has centred on materials discovery, and from 2015 to 2020 he led a team of IBM researchers developing “virtual experiments” that provide frictionless access to complex analytics and accelerate insight generation.
More recently, he has been leading research on Discovery Systems: integrated systems designed to speed up the scientific process through composable architectures, runtimes for AI surrogates of physical models, and automation and optimisation of end-to-end discovery workflows. He collaborates with his team and partners worldwide to push the performance, flexibility, and usability of scientific computing environments. Michael holds a PhD in Computational Biophysics from Universitat Pompeu Fabra in Barcelona.
Michele Gazzetti is a research software engineer part of the Data-Centric Computing and Cloud team at IBM Research Lab in Dublin, Ireland.
His work primarily targets large scale systems for the next generation of cloud datacenters. His interests relate to the design and optimization of distributed workloads, from middleware to management via virtualization and container technologies.
Michele holds a Master in Computer Engineering (Distributed Systems) from the University of Bologna. He also received B.Sc. diploma in Computer Engineering from Università di Modena e Reggio Emilia.
I joined the Next Generation Systems and Cloud at IBM Research Europe (Ireland Lab) in 2017. My research activities are focused on novel cloud computing paradigms, and applications of distributed systems and cloud computing concepts to the field of Artificial Intelligence. In the past I have been involved in research on virtualization, mostly applied to KVM, and parallel programming applied to multi- and many-core computing systems. My interests include also a fascination about the low-level close-to-the-hardware building blocks of computing systems, and their interfaces with the Operating System.
I hold a Ph.D. in Computers and Electronic Engineering from University of Bologna, received in 2015. I hold a M.Sc. from the same university (2010) and a B.Sc. from University of Catania (2017), both in Computers Engineering.

Erwan Gallen is Senior Principal Product Manager, Generative AI, at Red Hat, where he follows Red Hat AI Inference Server product and manages hardware-accelerator enablement across OpenShift, RHEL AI, and OpenShift AI. His remit covers strategy, roadmap, and lifecycle management for GPUs, NPUs, and emerging silicon, ensuring customers can run state-of-the-art generative workloads seamlessly in hybrid clouds.
Before joining Red Hat, Erwan was CTO and Director of Engineering at a media firm, guiding distributed teams that built and operated 100 % open-source platforms serving more than 60 million monthly visitors. The experience sharpened his skills in hyperscale infrastructure, real-time content delivery, and data-driven decision-making.
Since moving to Red Hat he has launched foundational accelerator plugins, expanded the company’s AI partner ecosystem, and advised Fortune 500 global enterprises on production AI adoption. An active voice in the community, he speaks regularly at NVIDIA GTC, Red Hat Summit, OpenShift Commons, CERN, and the Open Infra Summit.
More like this
A decade of open innovation: Red Hat continues to scale the open hybrid cloud with Microsoft
Stop managing the past and start building IT’s future
Technically Speaking | Build a production-ready AI toolbox
Technically Speaking | Platform engineering for AI agents
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds