
Most of the time when you run a script, you're concerned with its immediate results. Sometimes, though, the task is complex or needs to execute at a particular time, and there are many ways to achieve that goal.
By the end of this article, you should be able to do the following:
- Format dates and use them as conditions to make your program wait before moving to the next stage.
- Wait for a file without knowing for how long with
inotifytools. - Run your program at a specific time based on conditions by using
atq. - Use
cronto run a task more than once. - Run many tasks on different machines—some with complex relationships. Apache Airflow is an excellent tool for this type of situation.
You can find the code for this article in my GitHub repository.
Get the date inside a Bash script
Say you want a script to download the COVID-19 Vaccinations by Town and Age Group dataset from the state of Connecticut when the following conditions exist:
- It is during the week (there are no updates to the data made over the weekend).
- It is after 6PM (there are no updates earlier in the day).
GNU /usr/bin/date supports special format flags with the sign +. To see the full list, just type:
# /usr/bin/date --help
Back to your script. You can get the current day of the week and hour of the day and perform a few comparisons with a simple script:
#!/bin/bash
# Simple script that shows how to work with dates and times
# Jose Vicente Nunez Zuleta
#
test -x /usr/bin/date || exit 100
function is_week_day {
local -i day_of_week
day_of_week=$(/usr/bin/date +%u)|| exit 100
# 1 = Monday .. 5 = Friday
test "$day_of_week" -ge 1 -a "$day_of_week" -le 5 && return 0 || return 1
}
function too_early {
local -i hour
hour=$(/usr/bin/date +%H)|| exit 100
test "$hour" -gt 18 && return 0|| return 1
}
# No updates during the weekend, so don't bother (not an error)
is_week_day || exit 0
# Don't bother to check before 6:00 PM
too_early || exit 0
report_file="$HOME/covid19-vaccinations-town-age-grp.csv"
# COVID-19 Vaccinations by Town and Age Group
/usr/bin/curl \
--silent \
--location \
--fail \
--output "$report_file" \
--url 'https://data.ct.gov/api/views/gngw-ukpw/rows.csv?accessType=DOWNLOAD'
echo "Downloaded: $report_file"
If the conditions are met, the output will be something like this:
./WorkingWithDateAndTime.sh
Downloaded: /home/josevnz/covid19-vaccinations-town-age-grp.csv
Wait for a file using inotify tools
Here's another type of problem: You are waiting for a file named $HOME/lshw.json to arrive. Once it does, you want to start processing it. I wrote this script (version 1) to handle this situation:
#!/bin/bash
# Wait for a file to arrive and once is there process it
# Author: Jose Vicente Nunez Zuleta
test -x /usr/bin/jq || exit 100
LSHW_FILE="$HOME/lshw.json"
# Enable the debug just to show what is going on...
trap "set +x" QUIT EXIT
set -x
while [ ! -f "$LSHW_FILE" ]; do
sleep 30
done
/usr/bin/jq ".|.capabilities" "$LSHW_FILE"|| exit 100
A magic process generates the file for while you are waiting:
# sudo /usr/sbin/lshw -json > $HOME/lshw.json
And you wait until the file arrives:
./WaitForFile.sh
+ '[' '!' -f /home/josevnz/lshw.json ']'
+ sleep 30
+ '[' '!' -f /home/josevnz/lshw.json ']'
+ /usr/bin/jq '.|.capabilities' /home/josevnz/lshw.json
{
"smbios-3.2.1": "SMBIOS version 3.2.1",
"dmi-3.2.1": "DMI version 3.2.1",
"smp": "Symmetric Multi-Processing",
"vsyscall32": "32-bit processes"
}
+ set +x
There are a few problems with this approach:
- You may wait too long. If the file arrives one second after the process starts sleeping, you wait 29 seconds.
- If the system sleeps too little, it wastes CPU cycles.
- What happens if the file never arrives? You could use the
timeouttool or more complex logic to handle this scenario.
Another alternative is to use the Inotify API with inotify-tools and do a better, version 2 of the script using inotifywait:
#!/bin/bash
# Wait for a file to arrive and once is there process it
# Author: Jose Vicente Nunez Zuleta
test -x /usr/bin/jq || exit 100
test -x /usr/bin/inotifywait|| exit 100
test -x /usr/bin/dirname|| exit 100
LSHW_FILE="$HOME/lshw.json"
while [ ! -f "$LSHW_FILE" ]; do
test "$(/usr/bin/inotifywait --timeout 28800 --quiet --syslog --event close_write "$(/usr/bin/dirname "$LSHW_FILE")" --format '%w%f')" == "$LSHW_FILE" && break
done
/usr/bin/jq ".|.capabilities" "$LSHW_FILE"|| exit 100
So if a random file shows up on $HOME, it won't break the wait cycle, but if the file you're looking for shows up there and is fully written, it will exit the loop:
#/usr/bin/touch $HOME/randomfilenobodycares.txt
#sudo /usr/sbin/lshw -json > $HOME/lshw.json
Note the timeout in seconds (28,800 = 8 hours). inotifywait will exit after that if the file is not there.
Do it once by hand, do it twice with cron
Let's go back to the script above that downloads the COVID-19 data. If you want to automate it, you can make it part of a cron job but without the hour and day of the week logic.
As a reminder, this is the command you want to run:
report_file="$HOME/covid19-vaccinations-town-age-grp.csv"
# COVID-19 Vaccinations by Town and Age Group
/usr/bin/curl \
--silent \
--location \
--fail \
--output "$report_file" \
--url 'https://data.ct.gov/api/views/gngw-ukpw/rows.csv?accessType=DOWNLOAD'
To run it every weekday at 6PM and save the output to a log, use:
# minute (0-59),
# hour (0-23),
# day of the month (1-31),
# month of the year (1-12),
# day of the week (0-6, 0=Sunday),
# command
0 18 * * 1-5 /usr/bin/curl --silent --location --fail --output "$HOME/covid19-vaccinations-town-age-grp.csv" --url 'https://data.ct.gov/api/views/gngw-ukpw/rows.csv?accessType=DOWNLOAD' > $HOME/logs/covid19-vaccinations-town-age-grp.log
Cron also gives the flexibility to do things you can normally achieve only with other tools like systemd units. For example, say you want to download the vaccination details as soon as a Linux server reboots (this worked for me on Fedora 29):
@reboot /usr/bin/curl --silent --location --fail --output "$HOME/covid19-vaccinations-town-age-grp.csv" --url 'https://data.ct.gov/api/views/gngw-ukpw/rows.csv?accessType=DOWNLOAD' > $HOME/logs/covid19-vaccinations-town-age-grp.log
So how do you edit and maintain cron jobs? crontab -e gives an interactive editor with some syntax checks. I prefer to use the Ansible cron module to automate my cron editing. In addition, that ensures I can keep my jobs on Git for proper review and deployment.
[ Learn how to configure your Chrony daemon with an Ansible playbook. ]
Finally, the cron syntax is very powerful, and that can lead to unexpected complexity. You can use tools like Crontab Generator to get the proper syntax without having to overthink the meaning of each field.
Now, what if you need to run something but not right away? Generating a crontab for that may be too complicated, but there are other things you can do.
Use atq
The Unix tool atq is very similar to cron, but its beauty is that it supports a very loose and rich syntax for scheduling jobs for execution.
Imagine the following example: You need to run an errand in 50 minutes and want to leave your server downloading a file, and you determine it is OK to download the file 60 minutes from now:
# cat aqt_job.txt
/usr/bin/curl --silent --location --fail --output "$HOME/covid19-vaccinations-town-age-grp.csv" --url 'https://data.ct.gov/api/views/gngw-ukpw/rows.csv?accessType=DOWNLOAD'
at 'now + 1 hour' -f aqt_job.txt
warning: commands will be executed using /bin/sh
job 10 at Sat Aug 14 06:59:00 2021
You can confirm your job was indeed scheduled to run (note that the job ID is 10):
# atq
10 Sat Aug 14 06:59:00 2021 a josevnz
And if you change your mind, you can remove it:
# atrm 10
# atq
Back to the original script. Rewrite it (version 3) to use at instead of just date for scheduling the data file download:
#!/bin/bash
# Simple script that shows how to work with dates and times, and Unix 'at'
# Jose Vicente Nunez Zuleta
#
test -x /usr/bin/date || exit 100
test -x /usr/bin/at || exit 100
report_file="$HOME/covid19-vaccinations-town-age-grp.csv"
export report_file
function create_at_job_file {
/usr/bin/cat<<AT_FILE>"$1"
# COVID-19 Vaccinations by Town and Age Group
/usr/bin/curl \
--silent \
--location \
--fail \
--output "$report_file" \
--url 'https://data.ct.gov/api/views/gngw-ukpw/rows.csv?accessType=DOWNLOAD'
AT_FILE
}
function is_week_day {
local -i day_of_week
day_of_week=$(/usr/bin/date +%u)|| exit 100
# 1 = Monday .. 5 = Friday
test "$day_of_week" -ge 1 -a "$day_of_week" -le 5 && return 0 || return 1
}
function already_there {
# My job is easy to spot as it has a unique footprint...
for job_id in $(/usr/bin/atq| /usr/bin/cut -f1 -d' '| /usr/bin/tr -d 'a-zA-Z'); do
if [ "$(/usr/bin/at -c "$job_id"| /usr/bin/grep -c 'COVID-19 Vaccinations by Town and Age Group')" -eq 1 ]; then
echo "Hmmm, looks like job $job_id is already there. Not scheduling a new one. To cancel: '/usr/bin/atrm $job_id'"
return 1
fi
done
return 0
}
# No updates during the weekend, so don't bother (not an error)
is_week_day || exit 0
# Did we schedule this before?
already_there|| exit 100
ATQ_FILE=$(/usr/bin/mktemp)|| exit 100
export ATQ_FILE
trap '/bin/rm -f $ATQ_FILE' INT EXIT QUIT
echo "$ATQ_FILE"
create_at_job_file "$ATQ_FILE"|| exit 100
/usr/bin/at '6:00 PM' -f "$ATQ_FILE"
So atq is a convenient "fire and forget" scheduler that also works with the machine's load. You're more than welcome to go deeper and find out more details about at.
Handle multiple task dependencies running on multiple hosts
This last example has less to do with cron and Bash and more with creating a complex pipeline of tasks that can run on different machines and have interdependencies.
Cron specifically is not very good at putting together multiple tasks that depend on each other. Luckily, sophisticated tools like Apache Airflow can be used to create complex pipelines and workflows.
Here is a different example: I have various Git repositories across my machines on my home network. I want to ensure I automatically commit changes on some of those repositories, pushing some of those changes remotely if needed.
In Airflow, tasks are defined using Python. This is great as you can add your own modules, the syntax is familiar, and you can also keep job definitions under version control (like Git).
So what does this new job look like? Here is the Directed Acyclic Graph (heavily documented in Markup format):
# pylint: disable=pointless-statement,line-too-long
"""
# Make git backups on different hosts in Nunez family servers
## Replacing the following cron jobs on dmaf5
----------------------------------------------------------------------
MAILTO=kodegeek.com@protonmail.com
*/5 * * * * cd $HOME/Documents && /usr/bin/git add -A && /usr/bin/git commit -m "Automatic check-in" >/dev/null 2>&1
*/30 * * * * cd $HOME/Documents && /usr/bin/git push --mirror > $HOME/logs/codecommit-push.log 2>&1
----------------------------------------------------------------------
"""
from datetime import timedelta
from pathlib import Path
from os import path
from textwrap import dedent
from airflow import DAG
from airflow.providers.ssh.operators.ssh import SSHOperator
from airflow.operators.bash import BashOperator
from airflow.utils.dates import days_ago
default_args = {
'owner': 'josevnz',
'depends_on_past': False,
'email': ['myemail@kodegeek.com'],
'email_on_failure': True,
'email_on_retry': False,
'retries': 5,
'retry_delay': timedelta(minutes=30),
'queue': 'git_queue'
}
TUTORIAL_PATH = f'{path.join(Path.home(), "DatesAndComplexInBash")}'
DOCUMENTS_PATH = f'{path.join(Path.home(), "Documents")}'
with DAG(
'git_tasks',
default_args=default_args,
description='Git checking/push/pull across Nunez family servers, during week days 6:00-19:00',
schedule_interval='*/30 6-19 * * 1-5',
start_date=days_ago(2),
tags=['backup', 'git'],
) as git_backup_dag:
git_backup_dag.doc_md = __doc__
git_commit_documents = SSHOperator(
task_id='git_commit_documents',
depends_on_past=False,
ssh_conn_id="ssh_josevnz_dmaf5",
params={'documents': DOCUMENTS_PATH},
command=dedent(
"""
cd {{params.documents}} && \
/usr/bin/git add --ignore-errors --all \
&&
/usr/bin/git commit --quiet --message 'Automatic Document check-in @ dmaf5 {{ task }}'
"""
)
)
git_commit_documents.doc_md = dedent(
"""
#### Jose git commit PRIVATE documents on dmaf5 machine
* Add and commit with a default message.
* Templated using Jinja2 and f-strings
"""
)
git_push_documents = SSHOperator(
task_id='git_push_documents',
depends_on_past=False,
ssh_conn_id="ssh_josevnz_dmaf5",
params={'documents': DOCUMENTS_PATH},
command=dedent(
"""
cd {{params.documents}} && \
/usr/bin/git push
"""
)
)
git_push_documents.doc_md = dedent(
"""
#### Jose git push PRIVATE documents from dmaf5 machine into a private remote repository
"""
)
remote_repo_git_clone = BashOperator(
task_id='remote_repo_git_clone',
depends_on_past=False,
params={'tutorial': TUTORIAL_PATH},
bash_command=dedent(
"""
cd {{params.tutorial}} \
&& \
/usr/bin/git pull --quiet
"""
)
)
remote_repo_git_clone.doc_md = dedent(
"""
You need to clone the repository first:
git clone --verbose git@github.com:josevnz/DatesAndComplexInBash.git
Uses BashOperator as it runs on the same machine where Airflow runs.
"""
)
# Task relantionships
# Git documents is a dependency for push documents
git_commit_documents >> git_push_documents
# No dependency except the day of the week and time
remote_repo_git_clone
The relationships of these tasks can be seen in the GUI. In this case, the graph mode is displayed.
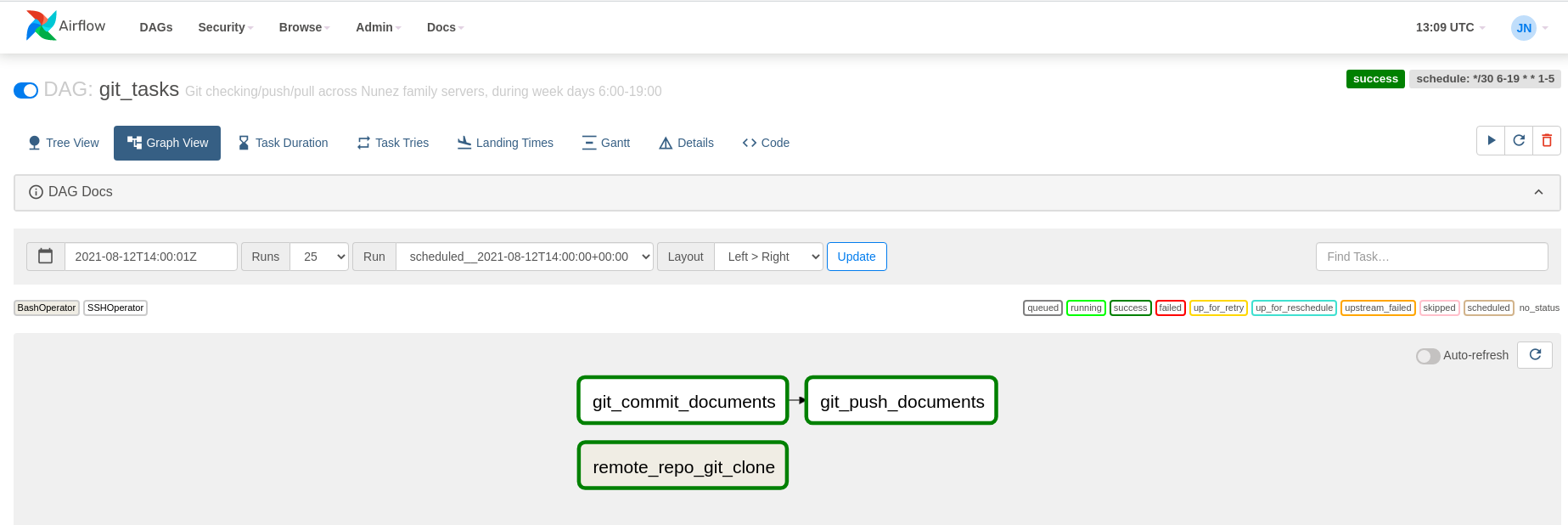
There is a lot more to explore with Airflow. You are more than welcome to look around to get more details and learn more.
[ Download a Bash Shell Scripting Cheat Sheet. ]
Wrap up
That was a lot of ground to cover in one article. Dealing with dates and time is complex, but there are plenty of tools to help you in your coding tasks. Here are the things you learned how to do:
- Format options in
/usr/bin/datethat can be used to alter the way scripts behave. - Use
inotify-toolsto efficiently listen for events related to the filesystem, like waiting for a file to be copied. - Automate periodic, repetitive tasks with
cronand useatwhen a little bit more flexibility is required. - Consider more advanced frameworks like Airflow when
cronfalls short.
Some of the script examples above are complex. As usual, statically verify your scripts with Pylint or Bash SpellCheck to save yourself some headaches.
About the author
Proud dad and husband, software developer and sysadmin. Recreational runner and geek.
More like this
Why platform engineering fails to scale: Product and adoption design in practice
The new reality of supply chain trust: Why platform-native security is non-negotiable
Where Coders Code | Command Line Heroes
What Kind of Coder Will You Become? | Command Line Heroes
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds