
Imagine you have a file (or bunch of files) and you want to search for a specific string or configuration setting within these files. Opening each file individually and trying to find the specific string would be tiresome and probably isn’t the right approach. So what can we use, then?
There are many tools we can use in *nix-based systems to find and manipulate text. In this article, we will cover the grep command to search for patterns, whether found in files or coming from a stream (a file or input comping from a pipe, or |). In an upcoming article, we will also see how to use sed (Stream Editor) to manipulate a stream.
The best way to understand the working of a program or utility is to consult its man page. Many (if not all) Unix tools provide man pages during install. On Red Hat Enterprise Linux-based systems, we can run the following to list grep's documentation files:
$ rpm -qd grep
/usr/share/doc/grep/AUTHORS
/usr/share/doc/grep/NEWS
/usr/share/doc/grep/README
/usr/share/doc/grep/THANKS
/usr/share/doc/grep/TODO
/usr/share/info/grep.info.gz
/usr/share/man/man1/egrep.1.gz
/usr/share/man/man1/fgrep.1.gz
With man pages at our disposal, we now can use grep and explore its options.
grep basics
During this part of the article, we use the words file, which you can find at the following location:
$ ls -l /usr/share/dict/words
lrwxrwxrwx. 1 root root 11 Feb 3 2019 /usr/share/dict/words -> linux.words
This file contains 479,826 words and is provided by the words package. In my Fedora system, that package is words-3.0-33.fc30.noarch. When we list the contents of the words file, we see the following output:
$ cat /usr/share/dict/words
1080
10-point
10th
11-point
[……]
[……]
zyzzyva
zyzzyvas
ZZ
Zz
zZt
ZZZ
Ok, so we said the words file contained 479,826 lines, but how do we know that? Remember, we talked about man pages earlier. Let’s see if grep offers an option to count lines in a given file.
Ironically, we’ll use grep to grep for the option as follows:

So, we obviously need -c, or the long option --count, to count the number of lines in a given file. Counting the lines in /usr/share/dict/words yields:
$ grep -c '.' /usr/share/dict/words
479826
The '.' means that we will count all lines containing at least one character, space, blank, tab, etc.
Basic grep regexes
The grep command becomes more powerful when we use regular expressions (regexes). So, while we focus on the grep command itself, we’ll also touch on basic regular expression syntax.
Let’s assume that we are only interested in words starting with Z. This situation is where regexes come in handy. We use the carat (^) to search for patterns starting with a specific character, denoting the start of a string:
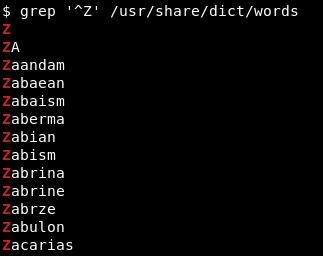
To search for patterns ending with a specific character, we use the dollar sign ($) to denote the end of the string. See the example below where we search for strings ending with hat:
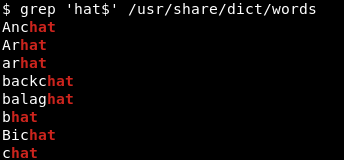
To print all lines that contain hat regardless of its position, whether at the beginning of the line or at the end of the line, we’d use something like:
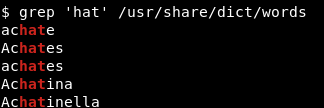
The ^ and $ are called metacharacters and should be escaped with a backslash (\) when we want to match these characters literally. If you want to know more about metacharacters, see https://www.regular-expressions.info/characters.html.
Example: Remove comments
Now that we’ve scratched the surface of grep, let’s work on some real-world scenarios. Many configuration files in *nix contain comments, which describe different settings within the configuration file. The /etc/fstab, file for example, has:
$ cat /etc/fstab
#
# /etc/fstab
# Created by anaconda on Thu Oct 27 05:06:06 2016
#
# Accessible filesystems, by reference, are maintained under '/dev/disk'
# See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info
#
/dev/mapper/VGCRYPTO-ROOT / ext4 defaults,x-systemd.device-timeout=0 1 1
UUID=e9de0f73-ddddd-4d45-a9ba-1ffffa /boot ext4 defaults 1 2
LABEL=SSD_SWAP swap swap defaults 0 0
#/dev/mapper/VGCRYPTO-SWAP swap swap defaults,x-systemd.device-timeout=0 0 0
The comments are marked by the hash (#), and we want to ignore them when printed. One option is the cat command:
$ cat /etc/fstab | grep -v '^#'
However, you don’t need cat here (avoid Useless Use of Cat). The grep command is perfectly capable of reading files, so instead, you can use something like this to ignore lines that contain comments:
$ grep -v '^#' /etc/fstab
If you want to send the output (without comments) to another file instead, you’d use:
$ grep -v '^#' /etc/fstab > ~/fstab_without_comment
While grep can format the output on the screen, this command is unable to modify a file in place. To do this, we’d need a file editor like ed. In the next article, we’ll use sed to achieve the same thing we did here with grep.
Example: Remove comments and empty lines
While we’re still on grep, let’s examine the /etc/sudoers file. This file contains many comments, but we are only interested in lines that have no comments, and we also want to get rid of the empty lines.
So, first, let’s remove the lines containing the comments. The following output is produced:
# grep -v '^#' /etc/sudoers
Defaults !visiblepw
Defaults env_reset
Defaults env_keep = "COLORS DISPLAY HOSTNAME HISTSIZE KDEDIR LS_COLORS"
Defaults env_keep += "MAIL PS1 PS2 QTDIR USERNAME LANG LC_ADDRESS LC_CTYPE"
Defaults env_keep += "LC_COLLATE LC_IDENTIFICATION LC_MEASUREMENT LC_MESSAGES"
Defaults env_keep += "LC_MONETARY LC_NAME LC_NUMERIC LC_PAPER LC_TELEPHONE"
Defaults env_keep += "LC_TIME LC_ALL LANGUAGE LINGUAS _XKB_CHARSET XAUTHORITY"
Defaults secure_path = /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
root ALL=(ALL) ALL
%wheel ALL=(ALL) ALL
Now, we want to get rid of the blank (empty) lines. Well, that is easy, just run another grep command:
# grep -v '^#' /etc/sudoers | grep -v '^$'
Defaults !visiblepw
Defaults env_reset
Defaults env_keep = "COLORS DISPLAY HOSTNAME HISTSIZE KDEDIR LS_COLORS"
Defaults env_keep += "MAIL PS1 PS2 QTDIR USERNAME LANG LC_ADDRESS LC_CTYPE"
Defaults env_keep += "LC_COLLATE LC_IDENTIFICATION LC_MEASUREMENT LC_MESSAGES"
Defaults env_keep += "LC_MONETARY LC_NAME LC_NUMERIC LC_PAPER LC_TELEPHONE"
Defaults env_keep += "LC_TIME LC_ALL LANGUAGE LINGUAS _XKB_CHARSET XAUTHORITY"
Defaults secure_path = /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
root ALL=(ALL) ALL
%wheel ALL=(ALL) ALL
valentin.local ALL=NOPASSWD: /usr/bin/updatedb
Could we do better? Could we run our grep command to be more resource-friendly and not fork grep twice? We certainly can:
# grep -Ev '^#|^$' /etc/sudoers
Defaults !visiblepw
Defaults env_reset
Defaults env_keep = "COLORS DISPLAY HOSTNAME HISTSIZE KDEDIR LS_COLORS"
Defaults env_keep += "MAIL PS1 PS2 QTDIR USERNAME LANG LC_ADDRESS LC_CTYPE"
Defaults env_keep += "LC_COLLATE LC_IDENTIFICATION LC_MEASUREMENT LC_MESSAGES"
Defaults env_keep += "LC_MONETARY LC_NAME LC_NUMERIC LC_PAPER LC_TELEPHONE"
Defaults env_keep += "LC_TIME LC_ALL LANGUAGE LINGUAS _XKB_CHARSET XAUTHORITY"
Defaults secure_path = /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
root ALL=(ALL) ALL
%wheel ALL=(ALL) ALL
valentin.local ALL=NOPASSWD: /usr/bin/updatedb
Here we introduced another grep option, -E (or --extended-regexp) <PATTERN> is an extended regular expression.
Example: Print only /etc/passwd users
It is obvious that grep is powerful when used with regexes. This article covers merely a small portion of what grep is really capable of. To demonstrate the capabilities of grep and the use of regular expressions, we’ll parse the /etc/passwd file and print only the usernames.
The format of the /etc/passwd file is as follows:
$ head /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
The above fields have the following meaning:
<name>:<password>:<UID>:<GID>:<GECOS>:<directory>:<shell>
See man 5 passwd for more information on the /etc/passwd file. To print the usernames only, we could use something like the following:
$ grep -Eo '^[a-zA-Z_-]+' /etc/passwd
root
bin
daemon
adm
lp
sync
shutdown
halt
mail
operator
In the above grep command, we introduced another option: -o (or --only-matching) to show only the part of a line matching <PATTERN>. Then, we combined -Eo to get the desired result.
We will now break up the above command so we can better understand what’s really happening. From left to right:
^matches at the start of the line.[a-zA-Z_-]is called a character class, and it matches a single character matching included list.+is a quantifier that matches between one and an unlimited number times.
The above regular expression will repeat itself until it reaches a character that it doesn’t match. The file’s first line is:
root:x:0:0:root:/root:/bin/bash
It is processed as follows:
- The first character is an
r, so it is matched by[a-z]. - The
+moves to the next character. - The second character is an
oand this is matched by[a-z]. - The
+moves to the next character.
This sequence repeats until we hit the colon (:). The character class [a-zA-Z_-] does not match the : symbol, so grep moves to the next line.
Since the usernames in the passwd file are all lowercase, we could also simplify our character class as follows, and still get the desired result:
$ grep -Eo '^[a-z_-]+' /etc/passwd
Example: Find a process
When using ps to grep for a process, we often use something like:
$ ps aux | grep ‘thunderbird’
But the ps command will not only list the thunderbird process. It also lists the grep command we just ran as well, since grep is also running after the pipe and is shown in the process list:
$ ps aux | grep thunderbird
val+ 2196 0.7 2.1 52 33 tty2 Sl+ 16:47 1:55 /usr/lib64/thunderbird/thunderbird
val+ 14064 0.0 0.0 57 82 pts/2 S+ 21:12 0:00 grep --color=auto thunderbird
We can handle this by adding grep -v grep to exclude grep from the output:
$ ps aux | grep thunderbird | grep -v grep
val+ 2196 0.7 2.1 52 33 tty2 Sl+ 16:47 1:55 /usr/lib64/thunderbird/thunderbird
While using grep -v grep will do what we wanted, better ways exist to achieve the same result without forking a new grep process:
$ ps aux | grep [t]hunderbird
val+ 2196 0.7 2.1 52 33 tty2 Sl+ 16:47 1:55 /usr/lib64/thunderbird/thunderbird
The [t]hunderbird here matches the literal t, and is case sensitive. It won’t match grep, and that’s why we are now seeing only thunderbird in the output.
This example is just a demonstration on how flexible grep is, won’t help you troubleshoot your process tree. There are better tools suited for this purpose, like pgrep.
Wrap-up
Use grep when you want to search for a pattern, either in a file or multiple directories recursively. Try to understand how regular expressions work when grep, since regexes can be powerful.
[Want to try out Red Hat Enterprise Linux? Download it now for free.]
About the author
Valentin is a system engineer with more than six years of experience in networking, storage, high-performing clusters, and automation.
He is involved in different open source projects like bash, Fedora, Ceph, FreeBSD and is a member of Red Hat Accelerators.
More like this
4 reasons to start using image mode for Red Hat Enterprise Linux right now
Advancing post-quantum capabilities of SSH in Red Hat Enterprise Linux
Operating System Management | Compiler
OS Wars_part 1 | Command Line Heroes
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds