
As agentic systems become common in the enterprise, it's clear to anyone concerned about sovereignty in AI factories: Inference is the hard part to scale.
One of the many benefits of a sovereign cloud is agency in how you accomplish your operations. Sovereign AI means you have control over the agents in your applications, workflows, and value delivery chain. Much of agent behavior is dependent on interactions with the model, so a truly sovereign agentic system requires sovereign inference - which in turn demands accelerators and AI models that are fully under your control.
For flexible and general-purpose agentic systems, you need large models. Fine tuning works great for cost efficiency on individual agentic use cases, but large models become a prerequisite for things like deep research agents. Any organization implementing these solutions wants to provide performant access to the models its teams need, while balancing capital expenditure of accelerator infrastructure with dynamic runtime requirements for that inference stack.
Autoscaling: The solution, and a new problem
Red Hat AI has supported autoscaling generative AI inference since we started shipping vLLM images in KServe. We're continually adding new features to improve the experience, such as recent support for load-aware autoscaling of vLLM inference pods in llm-d.
When a model inference pod starts on a node for the first time, it must load the model weights onto your accelerator's memory before it can serve inference requests. Models can be stored many ways, but Hugging Face is a common model repository. This means the model weights must be downloaded from the internet at least once, over your WAN connection. Downloading a model with over one trillion parameters would take about an hour and a half on a gigabit WAN connection.
Consequently, autoscaling that requires downloading a model from Hugging Face every time a new pod starts severely impacts your agility in reacting to traffic spikes.
Addressing the problem at the architecture level
Sovereign deployment models typically require an organizational governance process to approve different models for use. After approval, weights must be downloaded at least once, and then made available in a way that enables your inference platform to access them efficiently.
We worked with a large manufacturing customer to demonstrate how autoscaling generative AI inference works in practice, and our deployments took advantage of several characteristics of their platform's integration with ours.
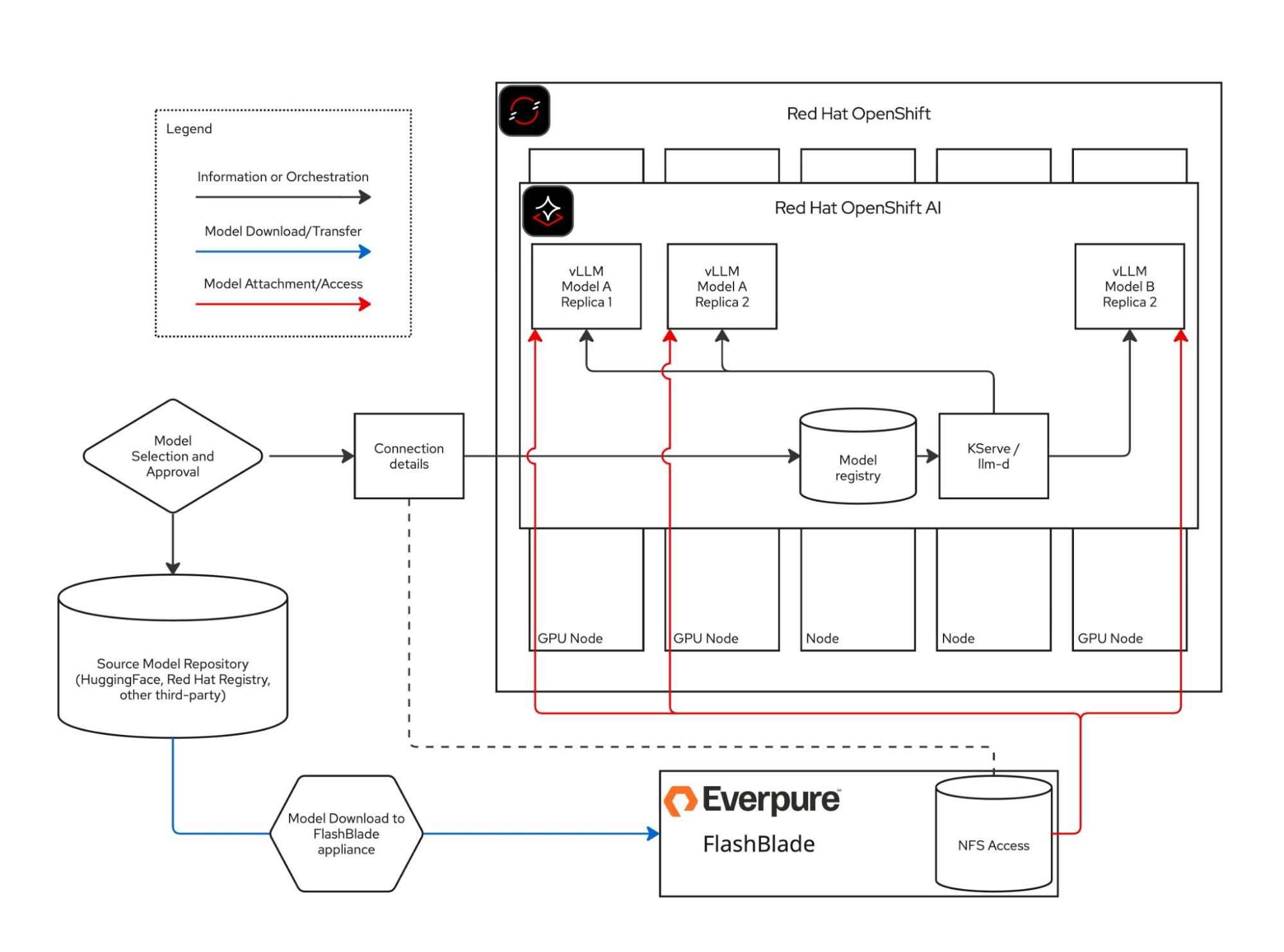
Alt text: Architecture to accelerate inference scaling in a bare-metal environment.
When a model is approved for enterprise use, it goes through a governed onboarding process into Factory-local storage. That onboarding has two outcomes:
- The model weights land in durable, high-performance storage
- The Red Hat OpenShift AI model registry records a storage URI pointing to them
The model registry becomes the source of truth. KServe queries it whenever it needs to locate and serve the model, providing the connection details to the orchestrated vLLM pods starting up on GPU nodes.
We worked with Everpure (formerly known as Pure Storage) to store models once as files on a shared persistent volume using their FlashBlade storage solution. The OpenShift AI model registry records a pvc://URI pointing to that volume. The volume is accessed over the NFS protocol on every GPU node to load the model into VRAM.
Why Everpure for inference workloads
There are several advantages to using Everpure storage solutions in the AI Factory architecture:
- True concurrent multi-reader access: FlashBlade supports multiple GPU nodes reading the same files in parallel through its NFS interface.
- Bypass CPU memory: FlashBlade supports NFS over RDMA (RoCEv2) enabling direct storage-to-GPU VRAM data transfers that bypass CPU memory entirely.
- POSIX semantics: vLLM and PyTorch open SafeTensors files using standard POSIX file I/O, including memory mapping, sequential reads, and standard open/close operations. FlashBlade serves these natively over NFS.
- OS page cache: When multiple pods on the same node load overlapping model shards, NFS benefits from the OS page cache so that repeat reads are served from memory without going back to storage.
To enable these capabilities, Portworx uses FlashBlade Direct Access to dynamically provision a FlashBlade NFS filesystem for a Kubernetes PVC and mount it to pods. In this scenario, the data path goes directly to FlashBlade and bypasses Portworx storage pools, though Portworx still handles provisioning, orchestration, and the mount lifecycle. Because it is NFS-based, multi-node shared access (RWX) is supported. Multiple vLLM replicas mount the same volume simultaneously without per-node copies.
Optionally, Portworx can warm local NVMe drives to serve as a high-speed cache for model artifacts. By storing models as OCI artifacts directly on the node, customers can reduce cold start times.
When KServe launches a new vLLM replica in response to increased inference load, that pod mounts the already-resident model volume and begins loading weights into VRAM immediately. The download step is entirely eliminated. Startup time is reduced to the time it takes to move weights from storage into VRAM.
Note: vLLM does not read the model storage continuously during inference. The SafeTensors files that make up a modern LLM are loaded entirely into GPU VRAM at process start. Once that load is complete, the disk is not touched again for the duration of the serving session.
This is a burst workload, not a sustained I/O workload. Because the storage challenge is concentrated entirely at startup, making startup fast is so high-leverage.
FlashBlade's architecture is specifically suited to this pattern. It maintains consistent per-client throughput as additional vLLM replicas mount the same model, up to the aggregate bandwidth of the configured system (which scales linearly as blades are added). Its distributed metadata architecture handles the concurrency of many nodes opening many files simultaneously, without the bottlenecks that would saturate a traditional NFS server.
Elasticity at scale
The practical difference between the old pattern and this new architecture is simple: it transforms auto-scaling from an impractical, time-consuming theoretical capability into a highly useful operational tool.
- The old pattern: With a per-node download model, a new vLLM replica can take hours to initialize. As a result, you cannot preemptively scale to meet anticipated load, respond quickly to a traffic spike, or fail over gracefully when a node goes down.
- The new architecture: With shared storage, a new replica mounts the model volume and begins loading weights into VRAM in seconds. The time to serve is limited by how fast the storage can feed the GPU, not by how long it takes to move terabytes across the internet.
Furthermore, because the same volume is mounted by every node in the cluster, a node failure does not trigger a re-download. KServe schedules a replacement pod, and the model is available again without any manual intervention.
Getting started
To understand the outcomes this architecture enables, get familiar with how autoscaling inference works in Red Hat OpenShift AI by checking out our interactive experience. Work with your Everpure or Red Hat account teams or join us at one of the following upcoming events to talk to an Everpure or Red Hat AI expert:
- Red Hat Summit Connect regional events
- Pure Accelerate event
Product trial
Red Hat OpenShift AI (Self-Managed) | Product Trial
About the authors
A Red Hatter since 2019, James' past experiences include IT infrastructure engineering, cyber security and traditional system administration. He built infrastructure as code and ran tooling in Linux containers for several years, spent two more years as an incident responder and threat hunter on DoD networks and loves to tinker with whatever lives at the nexus of performance and security. His focus on security, including the use of modern technologies to enable Defense-in-Depth in IT infrastructure, are likely to shine through his writing.
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds