On January 31st, 2023, Red Hat released Red Hat Device Edge, which provides access to MicroShift. MicroShift offers the simplicity of single-node deployment with the functionality and services you need for computing in resource-constrained locations. You can have many deployments on different hosts, creating the specific system image needed for each of your applications. Installing MicroShift on top of your managed RHEL devices in hard-to-service locations also allows for streamlined over-the-air updates.
In this blog we will demonstrate how to enable NVIDIA GPUs on an x86 system running Red Hat Device Edge.
Pre-requisites
We assume that you have already followed the MicroShift documentation to install Microshift 4.12 on the Red Hat Enterprise Linux 8.7 machine.
And obviously, you need a machine with an NVIDIA GPU. You can verify this with the following command:
$ lspci -nnv | grep -i nvidia
example output:
17:00.0 3D controller [0302]: NVIDIA Corporation GA100GL [A30 PCIe] [10de:20b7] (rev a1)
Subsystem: NVIDIA Corporation Device [10de:1532]
Install the NVIDIA GPU driver
This is a fairly simple step, because NVIDIA provides precompiled driver in RPM repositories that implement the modularity mechanism. At this stage, you should have already subscribed your machine and enabled the rhel-8-for-x86_64-baseos-rpms and rhel-8-for-x86_64-appstream-rpms repositories. We simply need to add the NVIDIA repository.
$ sudo dnf config-manager --add-repo=https://developer.download.nvidia.com/compute/cuda/repos/rhel8/x86_64/cuda-rhel8.repo
NVIDIA provides different branches of their drivers, with different lifecycles, which are described in NVIDIA Datacenter Drivers documentation. In this blog post, we will use the latest version from the production branch. At the time of writing, it is version R525. The install is done as follows:
$ sudo dnf module install nvidia-driver:525
Now, the driver is installed, be you still need to blacklist the nouveau driver which is a community developped in-tree driver from NVIDIA GPUs. It will conflict with the NVIDIA driver and must be disabled. This requires a reboot to take effect.
$ echo 'blacklist nouveau' | sudo tee /etc/modprobe.d/nouveau-blacklist.conf
$ sudo systemctl reboot
After the machine has rebooted, you can verify that the NVIDIA drivers are installed properly.
$ nvidia-smi
example output:
Fri Jan 13 14:29:53 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.60.13 Driver Version: 525.60.13 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA A30 Off | 00000000:17:00.0 Off | 0 |
| N/A 29C P0 35W / 165W | 0MiB / 24576MiB | 25% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
Install NVIDIA Container Toolkit
The NVIDIA Container Toolkit allows users to build and run GPU accelerated containers. The toolkit includes a container runtime library and utilities to automatically configure containers to leverage NVIDIA GPUs. You have to install it to allow the container runtime to transparently configure the NVIDIA GPUs for the pods deployed in Microshift.
NVIDIA container toolkit supports these distributions. Now we install Nvidia Container Toolkit for RHEL 8.6 which matches our version (shown in step 1).
$ curl -s -L https://nvidia.github.io/libnvidia-container/rhel8.7/libnvidia-container.repo | sudo tee /etc/yum.repos.d/libnvidia-container.repo
$ sudo dnf install nvidia-container-toolkit -y
The NVIDIA Container Toolkit requires some SELinux permissions to work properly. These permissions are set in 3 steps.
First, we allow containers to use devices from the host.
$ sudo dnf install container-selinux.noarch
$ sudo setsebool -P container_use_devices on
It still misses a permission, so we create a policy file.
$ cat <<EOF > nvidia-container-microshift.te
module nvidia-container-microshift 1.0;
require {
type xserver_misc_device_t;
type container_t;
class chr_file { map read write };
}
#============= container_t ==============
allow container_t xserver_misc_device_t:chr_file map;
EOF
And we compile and apply the policy.
$ checkmodule -m -M -o nvidia-container-microshift.mod nvidia-container-microshift.te
$ semodule_package --outfile nvidia-container-microshift.pp --module nvidia-container-microshift.mod
$ sudo semodule -i nvidia-container-microshift.pp
Install NVIDIA Device Plugin
For Microshift to be able to allocate GPU resource to the pods, you need to deploy the NVIDIA Device Plugin, which is Daemonset that allows you to automatically:
- Expose the number of GPUs on each nodes of your cluster
- Keep track of the health of your GPUs
- Run GPU enabled containers in your Kubernetes cluster.
The deployment is pretty easy, since you only have to add a few manifests and a kustomize configuration to the /etc/microshift/manifests folder where Microshift looks for manifests to create at start time. This is explained in the Configuring section of the Microshift documentation.
Let's create the folder:
$ sudo mkdir -p /etc/microshift/manifests
The device plugin runs in privileged mode, so we isolate it from other workloads, by running it in its own namespace, nvidia-device-plugin. We have worked with NVIDIA to create a static deployment manifest for the device plugin, including the namespace, role, role binding and service account. To add it to the manifests deployed by Microshift at start time, we download it as /etc/microshift/manifests/nvidia-device-plugin.yml.
$ curl -s -L https://gitlab.com/nvidia/kubernetes/device-plugin/-/raw/main/deployments/static/nvidia-device-plugin-privileged-with-service-account.yml | sudo tee /etc/microshift/manifests/nvidia-device-plugin.yml
The resources will not be created automatically just because the files exist. We need to add them to the kustomize configuration. This is done through a single kustomization.yaml file in the manifests folder that references all the resources we want to create.
$ cat <<EOF | sudo tee /etc/microshift/manifests/kustomization.yaml
---
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
resources:
- nvidia-device-plugin.yml
EOF
At that point, you are ready to restart the microshift service so that it creates the resources.
$ sudo systemctl restart microshift
Once Microshift is up and running, you can see that the pod is running in nvidia-device-plugin namespace.
$ oc get pod -n nvidia-device-plugin
NAMESPACE NAME READY STATUS RESTARTS AGE
nvidia-device-plugin nvidia-device-plugin-daemonset-jx8s8 1/1 Running 0 1m
And you can see in its log that it has registered itself as a device plugin for the nvidia.com/gpu resources.
$ oc logs -n nvidia-device-plugin nvidia-device-plugin-jx8s8
[...]
2022/12/13 04:17:38 Retreiving plugins.
2022/12/13 04:17:38 Detected NVML platform: found NVML library
2022/12/13 04:17:38 Detected non-Tegra platform: /sys/devices/soc0/family file not found
2022/12/13 04:17:38 Starting GRPC server for 'nvidia.com/gpu'
2022/12/13 04:17:38 Starting to serve 'nvidia.com/gpu' on /var/lib/kubelet/device-plugins/nvidia-gpu.sock
2022/12/13 04:17:38 Registered device plugin for 'nvidia.com/gpu' with Kubelet
You can also verify that the node exposes the nvidia.com/gpu resources in its capacity.
$ oc get node -o json | jq -r '.items[0].status.capacity'
example output:
{
"cpu": "48",
"ephemeral-storage": "142063152Ki",
"hugepages-1Gi": "0",
"hugepages-2Mi": "0",
"memory": "196686216Ki",
"nvidia.com/gpu": "1",
"pods": "250"
}
Run a test GPU accelerate workload
Now that the device plugin is running, you can run workloads that leverage the acceleration. A simple example the CUDA vectorAdd program. NVIDIA provides it as a container image, so it's easy to use.
We create a test namespace.
$ oc create namespace test
And define the pod specification. Note the spec.containers[0].resources.limits field where we ask for 1 nvidia.com/gpu resource.
$ cat << EOF > pod-cuda-vector-add.yaml
---
apiVersion: v1
kind: Pod
metadata:
name: test-cuda-vector-add
namespace: test
spec:
restartPolicy: OnFailure
containers:
- name: cuda-vector-add
image: "nvidia/samples:vectoradd-cuda11.2.1-ubi8"
resources:
limits:
nvidia.com/gpu: 1
securityContext:
allowPrivilegeEscalation: false
capabilities:
drop: ["ALL"]
runAsNonRoot: true
seccompProfile:
type: "RuntimeDefault"
EOF
We can simply create the pod.
$ oc apply -f pod-cuda-vector-add.yaml
And you can see in the pod log that it has found a CUDA device.
$ oc logs -n test test-cuda-vector-add
[Vector addition of 50000 elements]
Copy input data from the host memory to the CUDA device
CUDA kernel launch with 196 blocks of 256 threads
Copy output data from the CUDA device to the host memory
Test PASSED
Done
Well done! You have a machine with Microshift that can run NVIDIA GPU accelerated workloads.
Run MLPerf Inference and see the performance of real world workloads
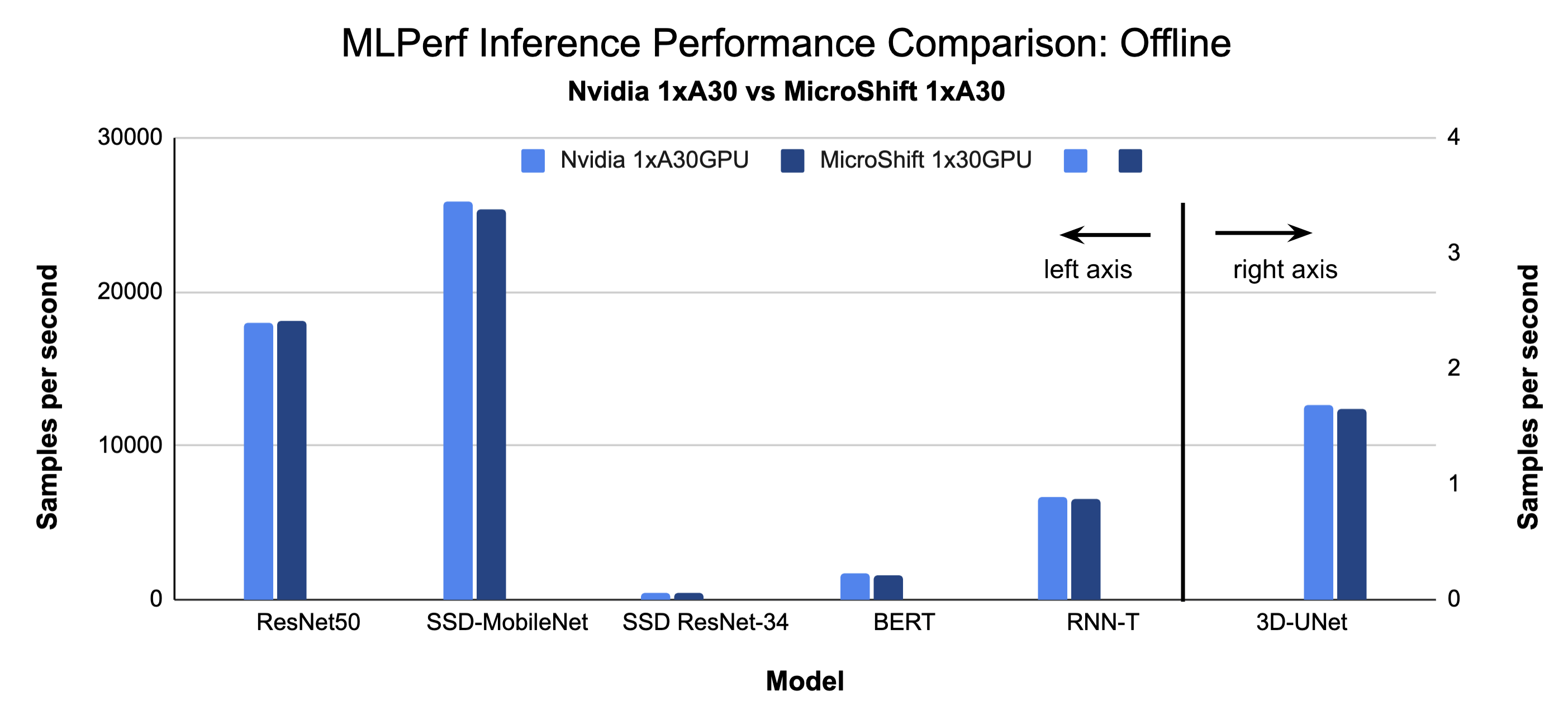
Microshift performed exceptionally well when compared to Nvidia published MLPerf v2.0 results for edge systems with one A30 GPU.
MLPerf is the industry standard open-source Machine Learning (ML) Benchmark with real world workloads for Natural Language Processing (NLP), Computer Vision (image classification, object detection & medical image segmentation), and Speech. The MLPerf inference benchmark suite measures how fast the system can process input and produce results, using a trained model. We ran MLPerf inference for edge with 1XA30 Nvidia GPU (Intel Xeon/Ice Lake CPU), and compared our results with Nvidia's published 1XA30 GPU results (AMD Epyc CPU).
For Singlestream our results on MicroShift + RHEL 8.7 were better (lower is better) for all inference benchmarks (Resnet50, SSD-MobileNet, SSD-resnet34, 3D-Unet, RNN-T, BERT) in all cases, compared to the Nvidia published results. This may have been due to a difference in the CPUs we used (Nvidia results were on AMD Epyc and our results were on Intel Ice Lake), or Operating system differences RHEL 8.7 vs Ubuntu.
For Offline results on MicroShift + Rhel 8.7 were within 0-2.6% worse than Nvidia Published results.
To reproduce our results please use these instructions.

Acknowledgements
We would like to thank Tom Tracy for his work preparing the host system for this blog and for his feedback regarding our proposed system setup.
About the authors

Diane Feddema is a Principal Software Engineer at Red Hat Inc in the Performance and Scale Team with a focus on AI/ML applications. She has submitted official results in multiple rounds of MLCommons MLPerf Inference and Training, dating back to the initial MLPerf rounds. Diane Leads performance analysis and visualization for MLPerf benchmark submissions and collaborates with Red Hat Hardware Partners in creating joint MLPerf benchmark submissions.
Diane has a BS and MS in Computer Science and is presently co-chair of the Best Practices group of the MLPerf consortium.

More like this
[node:rh-smart-meta-title]
Connect, collaborate, and grow: Your guide to Ecosystem Success Day at Red Hat Summit 2026
The Containers_Derby | Command Line Heroes
Kubernetes and the quest for a control plane | Technically Speaking
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds