When an operator fails, it can mean loss of critical functionality. When an admin sees an operator at risk, it must be fixed before it becomes a critical issue. As an operator developer, you want to help your users get this valuable info, fast. Here's how the Red Hat OpenShift Virtualization operator team created an Operator health metric that can help.
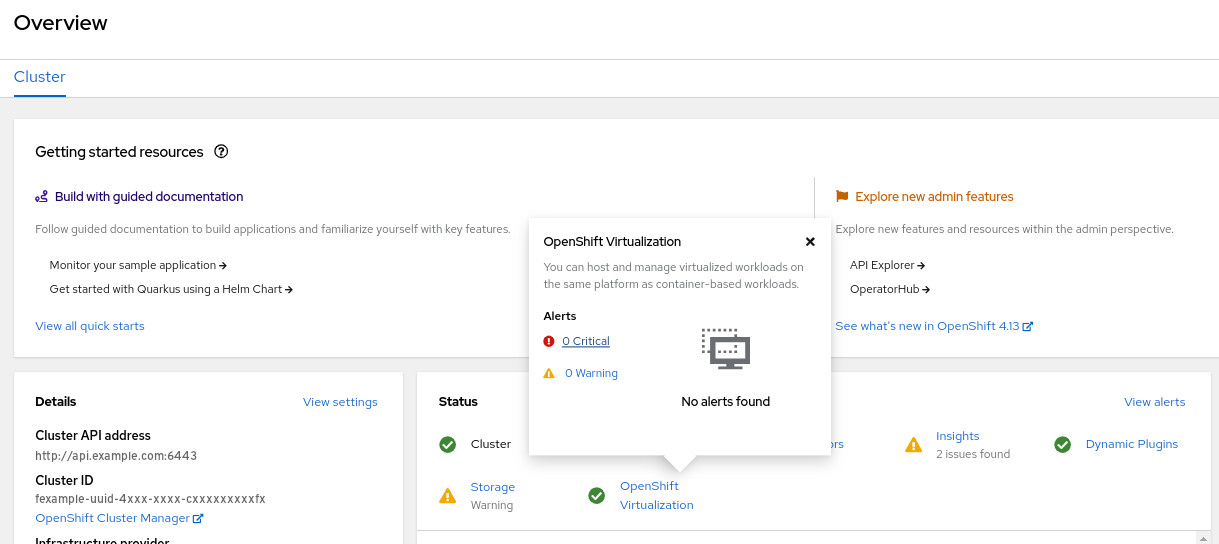
Currently, operators have different metrics and alerts that are unique to their needs and reflect their conditions. Yet there is no aggregation that can tell the user, through one single pane of glass, what the operator's general health is. Moreover, it’s not clear to users which alerts impact the operator's health and which are related to workloads.
In the OpenShift Virtualization operator, we created a metric that performs this aggregation and enables us to clearly define the operator's health.
To achieve this, we added three labels to each of the operator alerts:
1. kubernetes_operator_part_of – operator name
2. kubernetes_operator_component – operator component (can be the same as the above)
3. operator_health_impact – indicates the impact of the issue on the operator's health. This label will get one of the following values:
criticalindicates an issue that negatively impacts the operator's health, and the user should take action immediately to solve it.warningindicates an issue that might soon negatively impact the operator's health, and the user should solve the issue.noneindicates an issue that doesn't affect the operator's health. In most cases, this is related to the workload rather than the operator itself.
We also created and added a new metric that aggregates the metrics conditions by the name kubevirt_hco_system_health_status.
Its value is calculated by the following:
Degraded=Trueor !Available=True->kubevirt_hco_system_health_status= 2 (Error)Progressing=Trueor !ReconcileComplete=True->kubevirt_hco_system_health_status= 1 (Warning)- Else (
Available=TrueandDegraded=FalseandProgressing=FalseandReconcileComplete=True) ->kubevirt_hco_system_health_status= 0 (Healthy)
We created a recording rule for the health metric called kubevirt_hyperconverged_operator_health_status that will indicate the overall health of our operator, link. Values: healthy (0), warning (1) or critical (2).
It is based on both alerts and operator conditions. Its value will be the minimum of the two mentioned above.
This metric provides a clear operator health status and enables you to easily detect the causes of the issue by checking the firing alerts and their health impact.
Health metrics based on Conditions vs. Alerts
| Conditions-based health metric | Alerts-based health metric |
| Doesn’t necessarily indicate a real issue since issues can be resolved by k8s. | Usually indicates a real issue since there is an evaluation time prior to each alert. |
| Harder to track the issue and sub-operator since data in the conditions is aggregative. | Easy to track what the issue is since we can see the alerts. |
| Precision depends on the code coverage. | Precision depends on the alerts coverage. |
| Doesn’t require additional code changes. | Requires adding the the labels: - operator_health_impact to differentiate between operator and workload alerts to determine if they impact the health of the operator.- kubernetes_operator_part_of - To identify the alerts related to the specific operator. |
| It is the convention for reporting health status in OCP operators. | Not the convention. The community is not sure why this approach would be better. |
About the author

Shirly has been with Red Hat since January 2014 and currently serves as the OpenShift Virtualization Observability Team Lead. In this role, Shirly concentrates on improving the operator observability within the Kubernetes and OpenShift ecosystem, to ensure it effectively addresses user needs. Over the years, Shirly has been involved in numerous projects, driven by a genuine passion for enhancing system efficiency and user experience. She is also proactive in sharing the knowledge and best practices garnered with the broader operators community.
More like this
Optimizing cluster observability: A strategic approach to selective log routing in Red Hat OpenShift
New observability features in Red Hat OpenShift 4.21 and Red Hat Advanced Cluster Management for Kubernetes 2.16
The Containers_Derby | Command Line Heroes
Can Kubernetes Help People Find Love? | Compiler
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds