
Pourquoi ne peut-on pas regrouper tous les GPU dans le datacenter ?
La centralisation de l'architecture informatique est depuis longtemps la solution privilégiée aux problèmes de mise à l'échelle, de gestion et d'environnement. Cette approche prend différentes formes :
- Le matériel est hébergé dans de vastes datacenters.
- Il est presque toujours possible d'ajouter des nœuds ou du matériel supplémentaires, qui peuvent être gérés en local (parfois même sur le même sous-réseau).
- L'alimentation, le refroidissement et la connectivité sont stables et redondants.
Malgré l'efficacité apparente de cette approche, il est rare qu'une solution soit adaptée à toutes les situations. Prenons l'exemple du contrôle de la qualité dans le secteur de la fabrication.
Le contrôle de la qualité sur les sites de fabrication
Dans une usine ou une chaîne de montage, des tâches spécifiques sont effectuées dans des centaines, voire des milliers de zones. Avec un modèle traditionnel, chaque étape numérique ou outil physique doit transmettre le résultat de sa tâche à une application centrale située dans un cloud très éloigné. Plusieurs questions se posent alors.
- Rapidité : combien de temps faut-il pour qu'une photo soit prise, chargée dans le cloud et analysée par l'application centrale, qu'une réponse soit envoyée et qu'une mesure soit prise ? Vaut-il mieux prendre son temps au détriment du chiffre d'affaires, ou aller plus vite malgré le risque d'erreurs et d'accidents ? Les décisions sont-elles prises en temps réel ou quasi réel ?
- Quantité : quelle quantité de bande passante réseau faut-il pour que chaque capteur puisse charger ou télécharger un flux de données brutes en permanence ? Est-ce même possible ? Est-ce excessivement coûteux ?
- Fiabilité : que se passerait-il en cas de perte de connectivité réseau ? L'usine serait-elle complètement à l'arrêt ?
- Évolutivité : en supposant que les activités soient florissantes, un datacenter centralisé peut-il évoluer pour traiter chaque donnée brute issue de chaque périphérique, où qu'il se trouve ? Si oui, à quel prix ?
- Sécurité : certaines données brutes sont-elles considérées comme sensibles ? Est-il autorisé de les transmettre en dehors de la zone ? De les stocker n'importe où ? Doivent-elles être chiffrées avant d'être diffusées et analysées ?
Le passage à l'edge computing
Si vous hésitez sur certaines questions, l'edge computing peut vous aider. Le principe est de déplacer les fonctionnalités d'application privées, réduites ou sensibles à la latence depuis le datacenter vers l'endroit où se déroule le travail. Cette approche est déjà couramment utilisée, notamment dans les voitures et les téléphones. Avec l'edge computing, l'évolutivité n'est plus un problème, mais un avantage.
Reprenons notre exemple de la fabrication. Si chaque chaîne de montage disposait d'un petit cluster à proximité, tous les problèmes mentionnés pourraient être résolus.
- Rapidité : les photos des tâches accomplies sont examinées sur site et plus rapidement sur du matériel local.
- Quantité : la bande passante vers les sites externes est considérablement réduite, ce qui diminue les coûts récurrents.
- Fiabilité : même en cas de perte de connectivité réseau étendue, l'activité peut se poursuivre localement et se resynchroniser avec un cloud central lorsque la connectivité est rétablie.
- Évolutivité : quel que soit le nombre d'usines, les ressources requises sont réparties sur chaque site, ce qui évite de développer des datacenters centraux uniquement pour les périodes de forte activité.
- Sécurité : aucune donnée brute ne quitte le site, avec à la clé une surface d'exposition aux attaques réduite.
L'edge computing et le cloud public
Red Hat OpenShift, la plateforme Kubernetes d'entreprise leader sur le marché, offre un environnement flexible qui permet de placer les applications (et l'infrastructure) là où elles sont nécessaires. Il est à la fois possible d'exécuter les applications dans un cloud public centralisé et de les déplacer vers les chaînes de montage, où elles peuvent rapidement ingérer des données, les analyser et les traiter. Il s'agit de l'apprentissage automatique (AA) en périphérie du réseau. Les trois exemples suivants illustrent l'association de l'edge computing et de clouds privés et publics. Le premier associe l'edge computing et un cloud public.

- Les données sont acquises sur site. C'est là que les données brutes sont collectées. Les capteurs et les appareils de l'Internet des objets (IoT) qui prennent des mesures ou réalisent des tâches peuvent se connecter à des serveurs d'edge computing localisés à l'aide des flux Red Hat AMQ ou du composant AMQ Broker. Il peut s'agir de petits nœuds uniques ou de larges clusters haute disponibilité, en fonction des exigences des applications. Des nœuds de toute taille peuvent être utilisés dans tous les types de zone.
- La préparation des données, la modélisation, le développement et la distribution des applications sont des étapes cruciales. Les données sont ingérées, stockées et analysées. Sur la base de la chaîne de montage, les éventuels schémas sont identifiés sur les images de widgets (par exemple, des défauts dans les matériaux ou les processus). C'est là que se produit l'apprentissage. Les nouvelles informations obtenues sont réintégrées dans les applications cloud-native déployées en périphérie du réseau. Ce processus ne se déroule pas en périphérie du réseau, car l'exécution intensive de processeurs (CPU) et de processeurs graphiques (GPU) sur des clusters denses et centralisés permet de gagner plusieurs jours, voire plusieurs semaines, par rapport à l'utilisation de petits appareils d'edge computing.
- Les équipes de développement qui utilisent Red Hat OpenShift Pipelines et GitOps peuvent améliorer leurs applications en continu grâce à l'intégration et à la distribution continues (CI/CD), afin d'accélérer le processus. Plus vite les connaissances acquises peuvent être exploitées, plus il est possible de consacrer du temps et des ressources au chiffre d'affaires. Ainsi, en périphérie du réseau, les applications (nouvelles ou mises à jour) optimisées par l'intelligence artificielle exploitent de nouvelles connaissances pour observer et ingérer des données avant de les comparer aux modèles récents. Le cycle se répète dans le cadre de l'amélioration continue.
L'edge computing et le cloud privé
Dans notre deuxième exemple, l'ensemble du processus est identique, à l'exception de l'étape 2 qui s'effectue sur site dans un cloud privé.

Les entreprises peuvent choisir un cloud privé pour les raisons suivantes :
- Elles possèdent déjà le matériel et peuvent exploiter le capital existant.
- Elles doivent respecter des réglementations strictes en matière de localisation et de sécurité des données. Les données sensibles ne peuvent pas être stockées dans un cloud public, ni transiter par celui-ci.
- Elles nécessitent du matériel personnalisé, tel que des circuits FPGA (Field-Programmable Gate Array), des processeurs graphiques ou une configuration qui n'est pas proposée par les fournisseurs de cloud public.
- Certaines de leurs charges de travail sont plus coûteuses à exécuter dans un cloud public que sur du matériel local.
Ces quelques exemples illustrent bien la flexibilité offerte par OpenShift. Il est même possible d'exécuter OpenShift sur un cloud privé Red Hat OpenStack Platform.
L'edge computing et le cloud hybride
Le dernier exemple utilise un cloud hybride composé de clouds publics et privés.
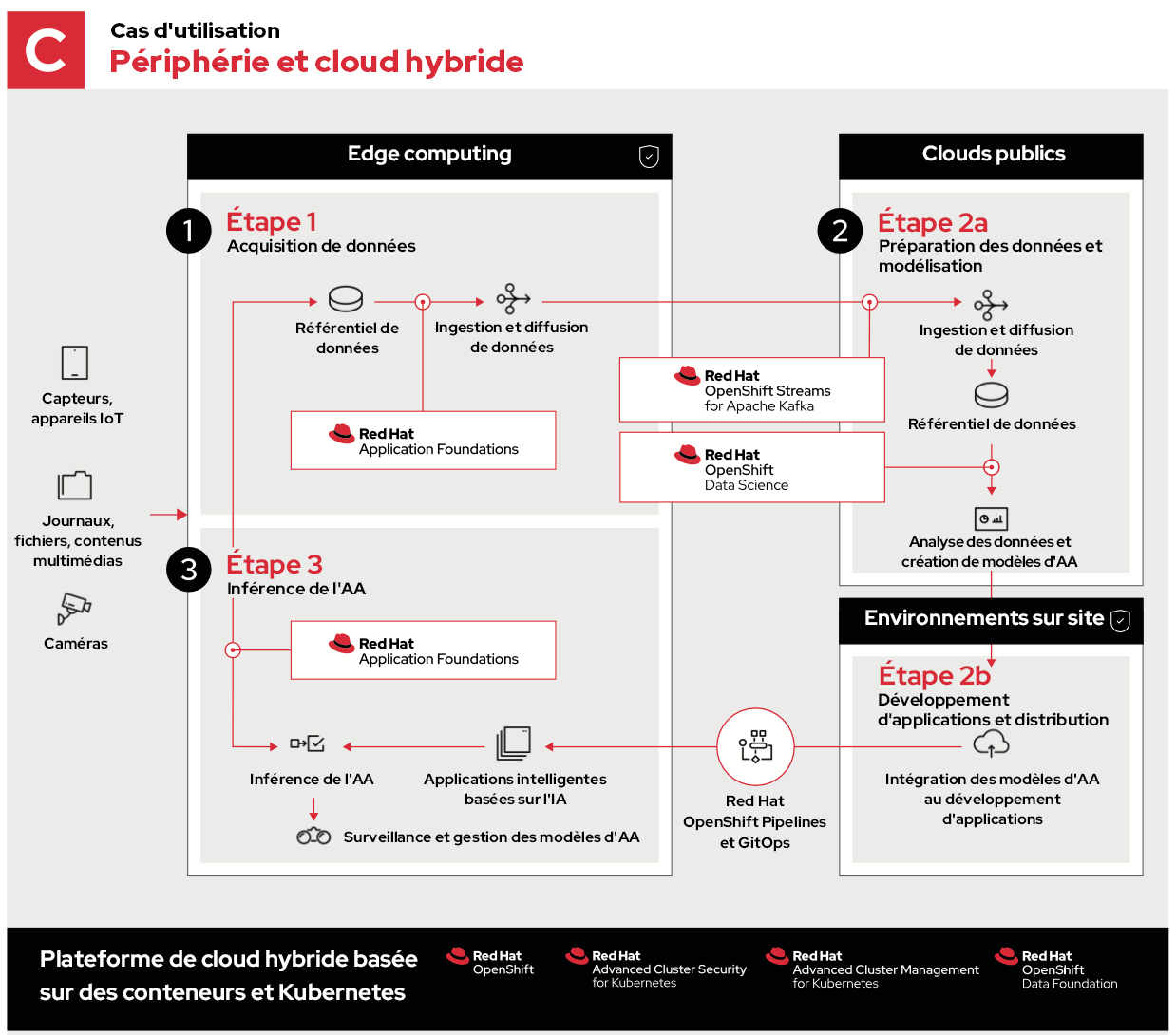
Dans ce cas, les étapes 1 et 3 sont identiques, et l'étape 2 comporte les mêmes processus. Ceux-ci sont toutefois distribués pour s'exécuter dans des environnements optimaux.
- L'étape 2a consiste à ingérer, stocker et analyser des données depuis la périphérie du réseau. Cette approche permet de tirer parti de l'échelle des ressources, de la diversité géographique et de la connectivité des clouds publics pour collecter et déchiffrer les données.
- L'étape 2b permet de développer des applications sur site. Il est ainsi possible d'accélérer, de sécuriser ou de personnaliser des workflows de développement spécifiques avant de renvoyer les mises à jour vers la périphérie.
Les solutions de Red Hat
Compte tenu du nombre de variables et d'éléments à prendre en compte, un environnement d'edge computing performant doit être flexible. Qu'il s'agisse de gérer une connectivité réseau lente, peu fiable ou nulle, de respecter des normes de conformité strictes ou d'atteindre des performances élevées, nous offrons à nos clients les outils dont ils ont besoin pour créer des solutions flexibles qui s'adaptent de façon à exécuter les bonnes applications aux bons endroits.
Quelle que soit la source des informations obtenues (périphérie du réseau, cloud public connu ou cloud privé sur site), les équipes de développement peuvent utiliser des outils qu'elles maîtrisent pour renouveler en permanence leurs applications cloud-native (exécutées sur OpenShift) et les exécuter en suivant la méthode la plus adaptée.
À propos de l'auteur
Ben has been at Red Hat since 2019, where he has focused on edge computing with Red Hat OpenShift as well as private clouds based on Red Hat OpenStack Platform. Before this he spent a decade doing a mix of sales and product marking across telecommunications, enterprise storage and hyperconverged infrastructure.
Plus de résultats similaires
Les menaces liées à l'IA évoluent. Vos défenses doivent en faire autant.
Pourquoi l'IA agentique représente une évolution des applications
Technically Speaking | Defining sovereign AI with open source
Infrastructure At The Edge | Compiler
Parcourir par canal

Automatisation
Les dernières nouveautés en matière d'automatisation informatique pour les technologies, les équipes et les environnements

Intelligence artificielle
Actualité sur les plateformes qui permettent aux clients d'exécuter des charges de travail d'IA sur tout type d'environnement

Cloud hybride ouvert
Découvrez comment créer un avenir flexible grâce au cloud hybride

Sécurité
Les dernières actualités sur la façon dont nous réduisons les risques dans tous les environnements et technologies

Edge computing
Actualité sur les plateformes qui simplifient les opérations en périphérie

Infrastructure
Les dernières nouveautés sur la plateforme Linux d'entreprise leader au monde

Applications
À l’intérieur de nos solutions aux défis d’application les plus difficiles
Virtualisation
L'avenir de la virtualisation d'entreprise pour vos charges de travail sur site ou sur le cloud